MapReduce数据流(一)
在上一篇文章中我们讲解了一个基本的MapReduce作业由那些基本组件组成,从高层来看,所有的组件在一起工作时如下图所示:
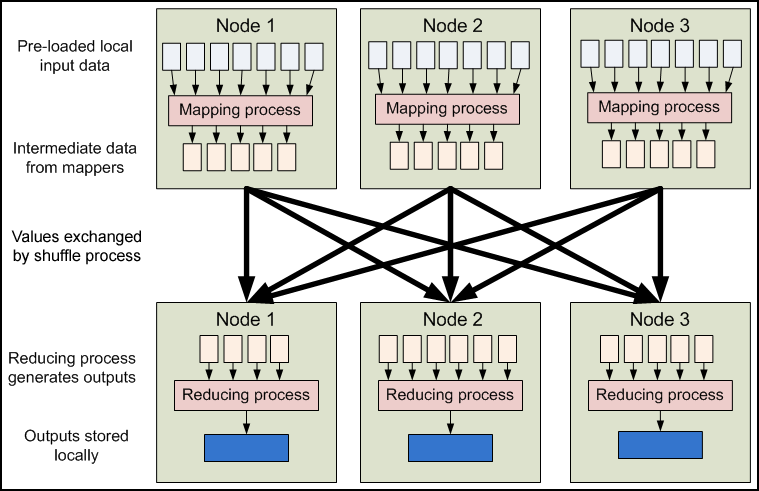
图4.4高层MapReduce工作流水线
MapReduce的输入一般来自HDFS中的文件,这些文件分布存储在集群内的节点上。运行一个MapReduce程序会在集群的许多节点甚至所有节点上运行mapping任务,每一个mapping任务都是平等的:mappers没有特定“标识物”与其关联。因此,任意的mapper都可以处理任意的输入文件。每一个mapper会加载一些存储在运行节点本地的文件集来进行处理(译注:这是移动计算,把计算移动到数据所在节点,可以避免额外的数据传输开销)。
当mapping阶段完成后,这阶段所生成的中间键值对数据必须在节点间进行交换,把具有相同键的数值发送到同一个reducer那里。Reduce任务在集群内的分布节点同mappers的一样。这是MapReduce中唯一的任务节点间的通信过程。map任务间不会进行任何的信息交换,也不会去关心别的map任务的存在。相似的,不同的reduce任务之间也不会有通信。用户不能显式的从一台机器封送信息到另外一台机器;所有数据传送都是由Hadoop MapReduce平台自身去做的,这些是通过关联到数值上的不同键来隐式引导的。这是Hadoop MapReduce的可靠性的基础元素。如果集群中的节点失效了,任务必须可以被重新启动。如果任务已经执行了有副作用(side-effect)的操作,比如说,跟外面进行通信,那共享状态必须存在可以重启的任务上。消除了通信和副作用问题,那重启就可以做得更优雅些。
近距离观察
在上一图中,描述了Hadoop MapReduce的高层视图。从那个图你可以看到mapper和reducer组件是如何用到词频统计程序中的,它们是如何完成它们的目标的。接下来,我们要近距离的来来看看这个系统以获取更多的细节。

图4.5细节化的Hadoop MapReduce数据流
图4.5展示了流线水中的更多机制。虽然只有2个节点,但相同的流水线可以复制到跨越大量节点的系统上。下去的几个段落会详细讲述MapReduce程序的各个阶段。
输入文件:文件是MapReduce任务的数据的初始存储地。正常情况下,输入文件一般是存在HDFS里。这些文件的格式可以是任意的;我们可以使用基于行的日志文件,也可以使用二进制格式,多行输入记录或其它一些格式。这些文件会很大—数十G或更大。
输入格式:InputFormat类定义了如何分割和读取输入文件,它提供有下面的几个功能:
- 选择作为输入的文件或对象;
- 定义把文件划分到任务的InputSplits;
- 为RecordReader读取文件提供了一个工厂方法;
Hadoop自带了好几个输入格式。其中有一个抽象类叫FileInputFormat,所有操作文件的InputFormat类都是从它那里继承功能和属性。当开启Hadoop作业时,FileInputFormat会得到一个路径参数,这个路径内包含了所需要处理的文件,FileInputFormat会读取这个文件夹内的所有文件(译注:默认不包括子文件夹内的),然后它会把这些文件拆分成一个或多个的InputSplit。你可以通过JobConf对象的setInputFormat()方法来设定应用到你的作业输入文件上的输入格式。下表给出了一些标准的输入格式:
|
输入格式 |
描述 |
键 |
值 |
|
TextInputFormat |
默认格式,读取文件的行 |
行的字节偏移量 |
行的内容 |
|
KeyValueInputFormat |
把行解析为键值对 |
第一个tab字符前的所有字符 |
行剩下的内容 |
|
SequenceFileInputFormat |
Hadoop定义的高性能二进制格式 |
用户自定义 |
用户自定义 |
表4.1MapReduce提供的输入格式
默认的输入格式是TextInputFormat,它把输入文件每一行作为单独的一个记录,但不做解析处理。这对那些没有被格式化的数据或是基于行的记录来说是很有用的,比如日志文件。更有趣的一个输入格式是KeyValueInputFormat,这个格式也是把输入文件每一行作为单独的一个记录。然而不同的是TextInputFormat把整个文件行当做值数据,KeyValueInputFormat则是通过搜寻tab字符来把行拆分为键值对。这在把一个MapReduce的作业输出作为下一个作业的输入时显得特别有用,因为默认输出格式(下面有更详细的描述)正是按KeyValueInputFormat格式输出数据。最后来讲讲SequenceFileInputFormat,它会读取特殊的特定于Hadoop的二进制文件,这些文件包含了很多能让Hadoop的mapper快速读取数据的特性。Sequence文件是块压缩的并提供了对几种数据类型(不仅仅是文本类型)直接的序列化与反序列化操作。Squence文件可以作为MapReduce任务的输出数据,并且用它做一个MapReduce作业到另一个作业的中间数据是很高效的。
MapReduce数据流(一)的更多相关文章
- MapReduce数据流
图4.5细节化的Hadoop MapReduce数据流 图4.5展示了流线水中的更多机制.虽然只有2个节点,但相同的流水线可以复制到跨越大量节点的系统上.下去的几个段落会详细讲述MapReduce程序 ...
- 简述MapReduce数据流
目前it基本都是一个套路,获得数据然后进行逻辑处理,存储数据. 基本上弄清楚整个的数据流向就等于把握了命脉. 现在说说mapreduce的数据流 1.首先数据会按照TextInputFormat按照特 ...
- MapReduce数据流(二)
输入块(InputSplit):一个输入块描述了构成MapReduce程序中单个map任务的一个单元.把一个MapReduce程序应用到一个数据集上,即是指一个作业,会由几个(也可能几百个)任务组成. ...
- 理解hadoop的Map-Reduce数据流(data flow)
http://blog.csdn.net/yclzh0522/article/details/6859778 Map-Reduce的处理过程主要涉及以下四个部分: 客户端Client:用于提交Map- ...
- MapReduce数据流-输出
- MapReduce数据流-Reduce
- MapReduce数据流-Partiton&Shuffle
- MapReduce数据流-Mapper
- MapReduce数据流-输入
随机推荐
- IIS_Mvc发布
网站发布步骤: 这部分是转载文章 在此标明出处,以前有文章是转的没标明的请谅解,因为有些已经无法找到出处,或者与其它原因. 如有冒犯请联系本人,或删除,或标明出处. 因为好的文章,以前只想收藏,但连接 ...
- python网络编程socket之多进程
#coding:utf-8 __author__ = 'similarface' import os,socket,threading,SocketServer SERVER_HOST='localh ...
- linux中无 conio.h的解决办法
conio.h不是C标准库中的头文件,在ISO和POSIX标准中均没有定义.conio是Console Input/Output(控制台输入输出)的简写,其中定义了通过控制台进行数据输入和数据输出的函 ...
- java synchronized静态同步方法与非静态同步方法,同步语句块
摘自:http://topmanopensource.iteye.com/blog/1738178 进行多线程编程,同步控制是非常重要的,而同步控制就涉及到了锁. 对代码进行同步控制我们可以选择同步方 ...
- P92认识对话框
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- inline-block的简单理解
1. 概念display:inline-block 将对象呈现为inline对象,但是对象的内容作为block对象呈现.之后的内联对象会被排列在同一行内.比如我们可以给一个link(a元素)inlin ...
- android - anim translate中 fromXDelta、toXDelta、fromYDelta、toXDelta属性
<?xml version="1.0" encoding="utf-8"?> <set xmlns:android="http:// ...
- DB、ETL、DW、OLAP、DM、BI关系结构图
DB.ETL.DW.OLAP.DM.BI关系结构图 在此大概用口水话简单叙述一下他们几个概念: (1)DB/Database/数据库——这里一般指的就是OLTP数据库,在线事物数据库,用来支持生产的, ...
- Android开发--Activity的创建
1.Activity概述 Activity是android四大基本组件之一.每一个activity文件对应一个界面,一个程序由多个activity组成. 2.Android工作目录
- C#获取相对路径的方法
这八种C#获取相对路径的方法,包括获取和设置当前目录的完全限定路径.获取启动了应用程序的可执行文件的路径,不包括可执行文件的名称等等内容. C#获取相对路径1. 获取和设置当前目录的完全限定路径. ...