MapReduce数据流(一)
在上一篇文章中我们讲解了一个基本的MapReduce作业由那些基本组件组成,从高层来看,所有的组件在一起工作时如下图所示:
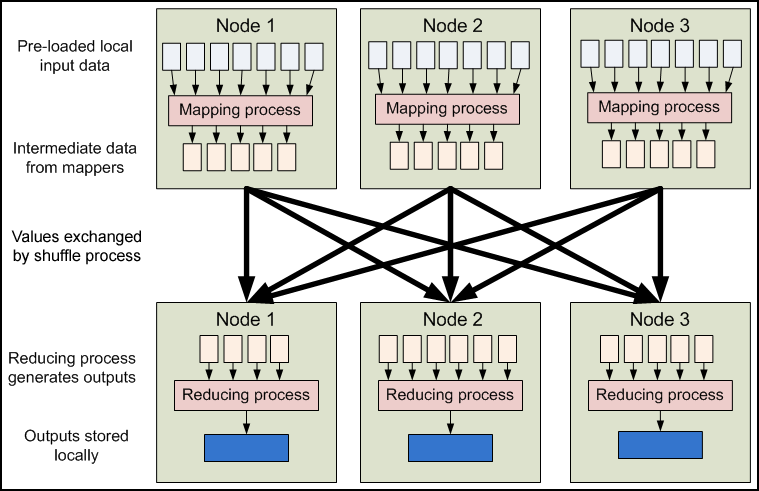
图4.4高层MapReduce工作流水线
MapReduce的输入一般来自HDFS中的文件,这些文件分布存储在集群内的节点上。运行一个MapReduce程序会在集群的许多节点甚至所有节点上运行mapping任务,每一个mapping任务都是平等的:mappers没有特定“标识物”与其关联。因此,任意的mapper都可以处理任意的输入文件。每一个mapper会加载一些存储在运行节点本地的文件集来进行处理(译注:这是移动计算,把计算移动到数据所在节点,可以避免额外的数据传输开销)。
当mapping阶段完成后,这阶段所生成的中间键值对数据必须在节点间进行交换,把具有相同键的数值发送到同一个reducer那里。Reduce任务在集群内的分布节点同mappers的一样。这是MapReduce中唯一的任务节点间的通信过程。map任务间不会进行任何的信息交换,也不会去关心别的map任务的存在。相似的,不同的reduce任务之间也不会有通信。用户不能显式的从一台机器封送信息到另外一台机器;所有数据传送都是由Hadoop MapReduce平台自身去做的,这些是通过关联到数值上的不同键来隐式引导的。这是Hadoop MapReduce的可靠性的基础元素。如果集群中的节点失效了,任务必须可以被重新启动。如果任务已经执行了有副作用(side-effect)的操作,比如说,跟外面进行通信,那共享状态必须存在可以重启的任务上。消除了通信和副作用问题,那重启就可以做得更优雅些。
近距离观察
在上一图中,描述了Hadoop MapReduce的高层视图。从那个图你可以看到mapper和reducer组件是如何用到词频统计程序中的,它们是如何完成它们的目标的。接下来,我们要近距离的来来看看这个系统以获取更多的细节。

图4.5细节化的Hadoop MapReduce数据流
图4.5展示了流线水中的更多机制。虽然只有2个节点,但相同的流水线可以复制到跨越大量节点的系统上。下去的几个段落会详细讲述MapReduce程序的各个阶段。
输入文件:文件是MapReduce任务的数据的初始存储地。正常情况下,输入文件一般是存在HDFS里。这些文件的格式可以是任意的;我们可以使用基于行的日志文件,也可以使用二进制格式,多行输入记录或其它一些格式。这些文件会很大—数十G或更大。
输入格式:InputFormat类定义了如何分割和读取输入文件,它提供有下面的几个功能:
- 选择作为输入的文件或对象;
- 定义把文件划分到任务的InputSplits;
- 为RecordReader读取文件提供了一个工厂方法;
Hadoop自带了好几个输入格式。其中有一个抽象类叫FileInputFormat,所有操作文件的InputFormat类都是从它那里继承功能和属性。当开启Hadoop作业时,FileInputFormat会得到一个路径参数,这个路径内包含了所需要处理的文件,FileInputFormat会读取这个文件夹内的所有文件(译注:默认不包括子文件夹内的),然后它会把这些文件拆分成一个或多个的InputSplit。你可以通过JobConf对象的setInputFormat()方法来设定应用到你的作业输入文件上的输入格式。下表给出了一些标准的输入格式:
|
输入格式 |
描述 |
键 |
值 |
|
TextInputFormat |
默认格式,读取文件的行 |
行的字节偏移量 |
行的内容 |
|
KeyValueInputFormat |
把行解析为键值对 |
第一个tab字符前的所有字符 |
行剩下的内容 |
|
SequenceFileInputFormat |
Hadoop定义的高性能二进制格式 |
用户自定义 |
用户自定义 |
表4.1MapReduce提供的输入格式
默认的输入格式是TextInputFormat,它把输入文件每一行作为单独的一个记录,但不做解析处理。这对那些没有被格式化的数据或是基于行的记录来说是很有用的,比如日志文件。更有趣的一个输入格式是KeyValueInputFormat,这个格式也是把输入文件每一行作为单独的一个记录。然而不同的是TextInputFormat把整个文件行当做值数据,KeyValueInputFormat则是通过搜寻tab字符来把行拆分为键值对。这在把一个MapReduce的作业输出作为下一个作业的输入时显得特别有用,因为默认输出格式(下面有更详细的描述)正是按KeyValueInputFormat格式输出数据。最后来讲讲SequenceFileInputFormat,它会读取特殊的特定于Hadoop的二进制文件,这些文件包含了很多能让Hadoop的mapper快速读取数据的特性。Sequence文件是块压缩的并提供了对几种数据类型(不仅仅是文本类型)直接的序列化与反序列化操作。Squence文件可以作为MapReduce任务的输出数据,并且用它做一个MapReduce作业到另一个作业的中间数据是很高效的。
MapReduce数据流(一)的更多相关文章
- MapReduce数据流
图4.5细节化的Hadoop MapReduce数据流 图4.5展示了流线水中的更多机制.虽然只有2个节点,但相同的流水线可以复制到跨越大量节点的系统上.下去的几个段落会详细讲述MapReduce程序 ...
- 简述MapReduce数据流
目前it基本都是一个套路,获得数据然后进行逻辑处理,存储数据. 基本上弄清楚整个的数据流向就等于把握了命脉. 现在说说mapreduce的数据流 1.首先数据会按照TextInputFormat按照特 ...
- MapReduce数据流(二)
输入块(InputSplit):一个输入块描述了构成MapReduce程序中单个map任务的一个单元.把一个MapReduce程序应用到一个数据集上,即是指一个作业,会由几个(也可能几百个)任务组成. ...
- 理解hadoop的Map-Reduce数据流(data flow)
http://blog.csdn.net/yclzh0522/article/details/6859778 Map-Reduce的处理过程主要涉及以下四个部分: 客户端Client:用于提交Map- ...
- MapReduce数据流-输出
- MapReduce数据流-Reduce
- MapReduce数据流-Partiton&Shuffle
- MapReduce数据流-Mapper
- MapReduce数据流-输入
随机推荐
- VB6 GDI+ 入门教程[9] Bitmap魔法(2):数据读写
本文转自 http://vistaswx.com/blog/article/category/tutorial/page/2 VB6 GDI+ 入门教程[9] Bitmap魔法(2):数据读写 200 ...
- 基于OGG的Oracle与Hadoop集群准实时同步介绍
版权声明:本文由王亮原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/220 来源:腾云阁 https://www.qclou ...
- Unity3D Mecanim 动画系统骨骼动画问题解决方法
http://7dot9.com/2014/08/16/unity3d-mecanim%E5%8A%A8%E7%94%BB%E7%B3%BB%E7%BB%9F%E9%AA%A8%E9%AA%BC%E5 ...
- J2EE相关总结
Java Commons The Java™ Tutorials: http://docs.oracle.com/javase/tutorial/index.html Java Platform, E ...
- angular-ui-router状态不变刷新页面
需求: 当前在A页面状态,要求在点击A状态时,可以刷新A状态. 解决方法:在ui-sref状态切换的标签中添加属性 ui-sref-opts="{reload: true}" ...
- hdu---(5038)Grade(胡搞)
Grade Time Limit: 3000/1500 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total Sub ...
- hdu----(4308)Saving Princess claire_(搜索)
Saving Princess claire_ Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/ ...
- UI-简答的BOL的取值塞值
不知道从什么时候开始,习惯用BOL MODEL来做一些东西的了.某个项目开始正式接触标准主数据的时候,开始了用MAINTAIN BAPI和BUPA的一些FM.然后在一段时间内是以此类的FM来开发的.B ...
- HTML:表格与表单
一.图片热点:规划出图片上的一个区域,可以做出超链接,直接点击图片区域就可以完成跳转的效果. <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 ...
- Mysql date_sub函数使用
mysql中内置函数date_add和date_sub能对指定的时间进行增加或减少一个指定的时间间隔,语法如下: DATE_ADD(date,INTERVAL expr type) DATE_SUB( ...