kubernetes service 原理精讲
---
# 介绍
Kubernetes Service 用于流量的负载均衡和反向代理,其通过 kube-proxy 组件实现。从服务的角度来看,kube-controller-manager 实现了服务注册,kube-proxy 实现了 kubernetes 集群内服务的负载均衡。
示意图如下:
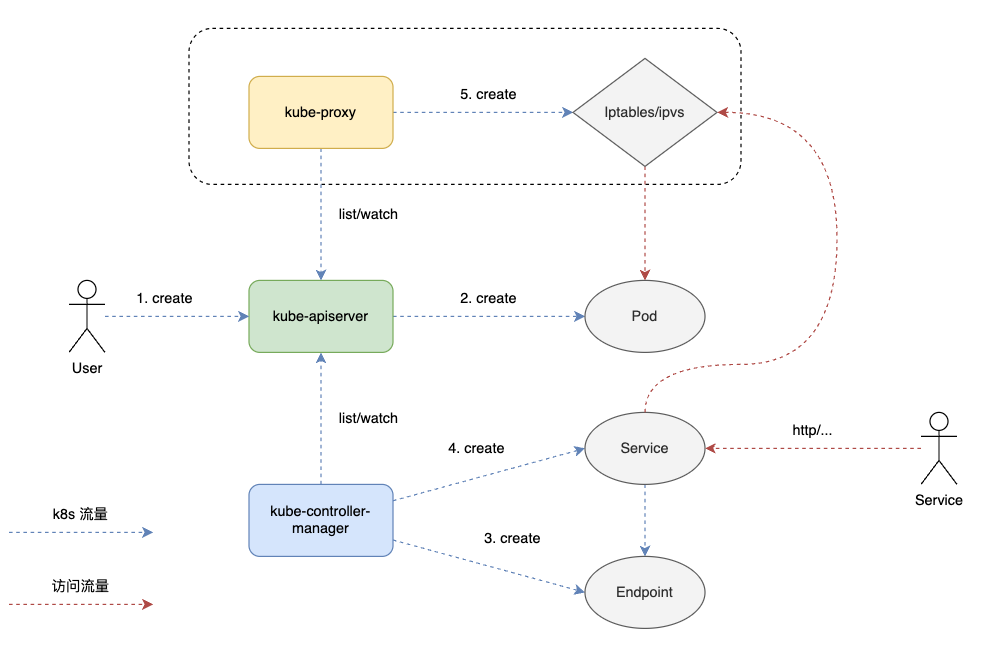
`kube-proxy` 通过三种模式 `userspace`,`iptables` 和 `IPVS` 实现 Service 流量的负载均衡。`userspace` 不太常用,kube-proxy 自 v1.8 开始支持 IPVS,v1.11 GA。
iptables 和 IPVS 都是基于内核的 `Netfilter` 实现。iptables 基于 iptables 表匹配规则,复杂度为 O(n),IPVS 基于哈希表实现规则匹配,复杂度为 O(1)。详细对比如下:
性能对比测试:
| 场景 | iptables 延迟 | IPVS 延迟 | 提升幅度 |
|-------------------------|-------------------|---------------|--------------|
| 100 Service(10 Pod) | 2.1ms | 1.3ms | 38% |
| 1000 Service(100 Pod)| 11.4ms | 2.9ms | 75% |
| 10000 Service(1000 Pod)| 超时 | 3.2ms | 100% |
*数据来源:Kubernetes 社区性能测试*
多维度对比:
| 维度 | iptables | IPVS |
|----------------|-----------------------------|------------------------------|
| 性能 | 低(O(n) 复杂度) | 高(O(1) 复杂度) |
| 扩展性 | 适合小规模集群 | 支持百万级 Service/Pod |
| 算法 | 仅随机选择 | 10+ 种负载均衡算法 |
| 资源占用 | 高(规则链维护) | 低(哈希表存储) |
| 故障恢复 | 全量重载,可能抖动 | 增量更新,无感知 |
# iptabls
iptables 介绍学习可参考 [iptables](https://www.zsythink.net/archives/category/%e8%bf%90%e7%bb%b4%e7%9b%b8%e5%85%b3/iptables),非常好的 iptables 学习资料,强烈推荐。
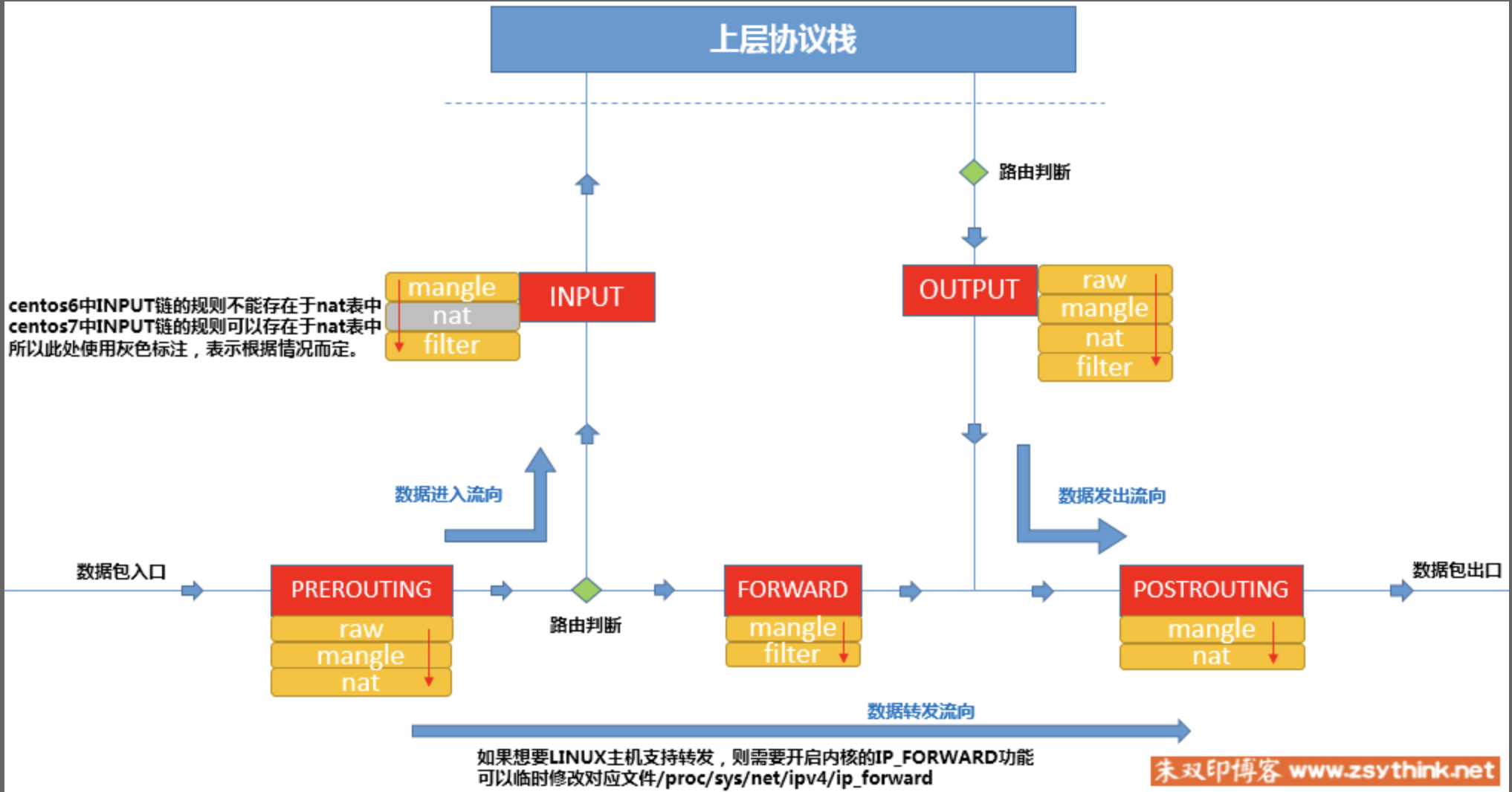
iptables 重点在五链五表,其示意图如下:
kube-proxy 通过在 INPUT,FORWARD,POST_ROUTING 链上添加钩子规则实现 Service 的负载均衡和反向代理。示意图如下:
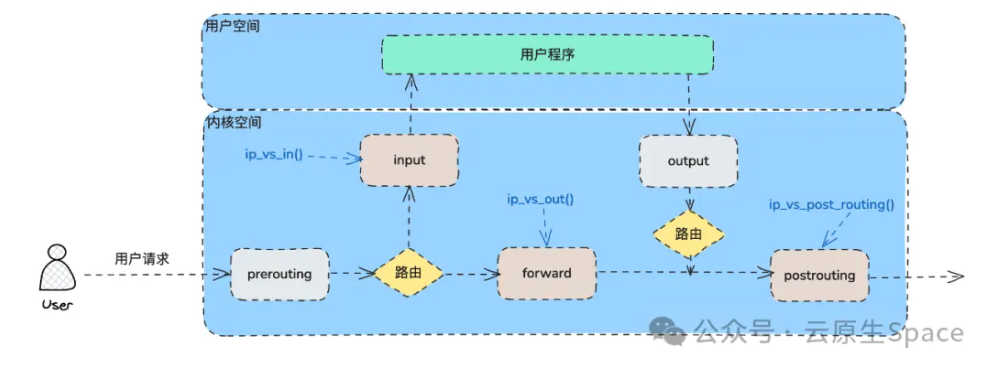
*图片来源于 [公众号:云原生 Space](https://mp.weixin.qq.com/s/HgQrub757qhIBCYO45o4NQ)*
kubernetes v1.8 版本之前的 Service 负载均衡基于 iptables 实现,可以参考 [一文看懂 Kubernetes 服务发现: Service](https://www.cnblogs.com/xingzheanan/p/14110134.html) 学习,本文重点关注在 IPVS 实现上。
# ipvs
IPVS 提供 DNAT 和负载均衡,需要和 iptables 配合使用才能实现 Service 的流量转发。
结合 ClusterIP 看 kube-proxy ipvs 是如何实现流量负载均衡的。
## Service ClusterIP
Kubernetes Service:
```
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 443/TCP 385d
```
ipvsadm 查看 svc 的负载均衡信息:
```
# ipvsadm -l -n | grep 10.233.0.1:443 -A 3
TCP 10.233.0.1:443 rr
-> 10.251.xxx.30:6443 Masq 1 18 2
-> 10.251.xxx.31:6443 Masq 1 25 0
-> 10.251.xxx.32:6443 Masq 1 13 1
```
输出部分元素解释:
- rr: 表示负载均衡策略,默认是 rr。
- Masq:负载均衡模式,Masq 指的是 NAT 模式。IPVS 支持 Direct Routing,Tunneling 模式,这两种都不支持端口映射,IPVS 使用的是 Masq 模式。
> IPVS 提供如下负载均衡策略:
> - rr:轮询调度
> - lc:最小连接数
> - dh:目标哈希
> - sh:源哈希
> - sed:最短期望延迟
> - nq: 不排队调度
只有负载均衡信息并不能使集群内访问 ClusterIP 的流量转发到后端服务。流量首先需要经过内核,由内核根据 iptables 策略决定丢弃/接受还是转发包。要接收访问 ClusterIP 的流量就需要在 iptables 的 PREROUTING 表中配置接受策略。并且需要创一个 dummy 接口,添加 ClusterIP 从而骗过内核,接收集群内发往 ClusterIP 的数据包。
kube-proxy 会创建 kube-ipvs0 的 dummy 接口,如下:
```
kube-ipvs0: flags=130 mtu 1500
inet 10.233.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
```
*这里也从侧面印证了为什么是集群内访问,这是 dummy 接口,集群外不通*
查看 iptables 策略看内核是如何接收访问 ClusterIP 的数据包的:
```
# iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
// 流量首先经过 PREROUTING 链的 nat 表,匹配 KUBE-SERVICES 规则
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
Chain KUBE-SERVICES (2 references)
target prot opt source destination
// KUBE-LOAD-BALANCER:匹配访问 LoadBalancer 的流量,和 ClusterIP 没有关系
KUBE-LOAD-BALANCER all -- anywhere anywhere /* Kubernetes service lb portal */ match-set KUBE-LOAD-BALANCER dst,dst
// 集群内源 ip 不是 10.222.0.0/18 网段的流量将进入 KUBE-MARK-MASQ 规则
// 这里匹配是发往 ClusterIP 的流量,10.222.0.0/18 网段是 kubernetes 分给 pod 的 ip,这条策略的意思是匹配集群内非 pod 访问 ClusterIP 的流量
KUBE-MARK-MASQ all -- !10.222.0.0/18 anywhere /* Kubernetes service cluster ip + port for masquerade purpose */ match-set KUBE-CLUSTER-IP dst,dst
// KUBE-NODE-PORT:匹配访问 NodePort 的流量,和 ClusterIP 没有关系
KUBE-NODE-PORT all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
ACCEPT all -- anywhere anywhere match-set KUBE-CLUSTER-IP dst,dst
ACCEPT all -- anywhere anywhere match-set KUBE-LOAD-BALANCER dst,dst
```
这里的逻辑很重要,为了理解清晰,有必要进一步介绍下 `KUBE-MARK-MASQ` 这条规则:
```
KUBE-MARK-MASQ all -- !10.222.0.0/18 anywhere /* Kubernetes service cluster ip + port for masquerade purpose */ match-set KUBE-CLUSTER-IP dst,dst
```
这条规则包括两个点:
1. `match-set KUBE-CLUSTER-IP dst,dst` 使用 iptables 的 ipset 模块匹配访问 ClusterIP 的流量。ipset 创建了一个包括 ip 信息等的集合 `KUBE-CLUSTER-IP`(实际是哈希表,查找复杂度为 O(1)):
```
# ipset list KUBE-CLUSTER-IP | grep 10.233.0.1,tcp:443
10.233.0.1,tcp:443
```
2. 匹配到访问 ClusterIP 的流量后进入 `KUBE-MARK-MASQ` 规则:
```
Chain KUBE-MARK-MASQ (4 references)
target prot opt source destination
MARK all -- anywhere anywhere MARK or 0x4000
```
`KUBE-MARK-MASQ` 规则将数据包打上 `MARK:0x4000` 标签。
> 这里留个问题,为什么需要打上 `MARK:0x4000` 标签?
接着打上 MARK 标签的数据包被接收,进入 ipvs 负载均衡到相应的后端服务。
### 转发到哪里?
kubernetes 集群中每个节点都会起 kube-proxy 配置 iptables/ipvs 规则,并且这些规则是一致的。不同于传统负载均衡,kubernetes 集群内的负载均衡是分布式的。由 kube-proxy 保持信息一致。
集群内节点访问本节点的后端服务可以通过流量被接收后通过 ipvs 做 DNAT 直接转发到 pod 服务,没有问题。
那么,集群内节点访问 ClusterIP 转发到其它节点的 pod 该怎么做的呢?这涉及到跨节点通信,就需要 CNI 的帮忙了。示意图如下:
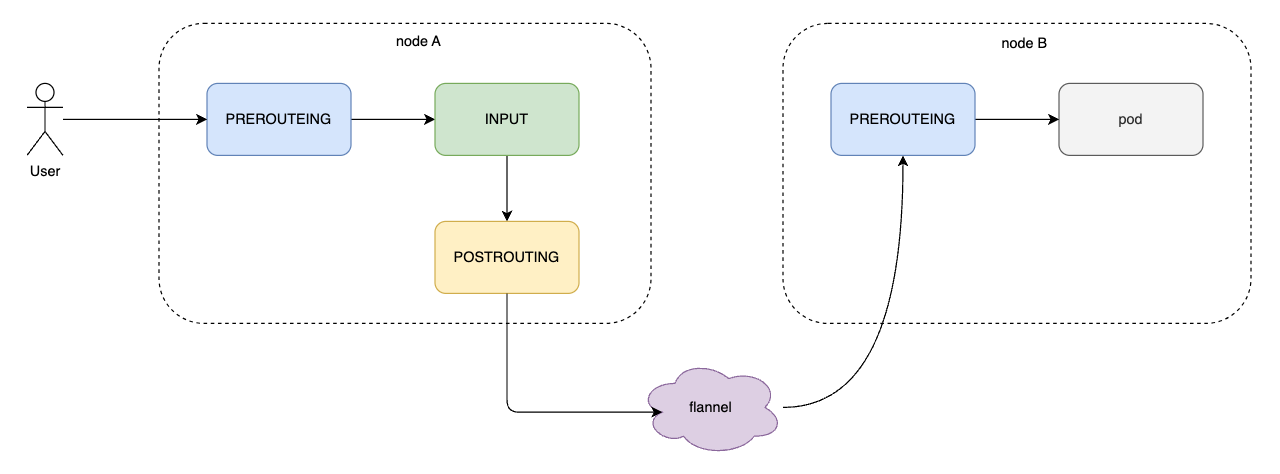
## 数据怎么回去?
前面提到通过 DNAT 数据包会转发到后端服务。后端服务的数据包又该怎么回去呢?
后端数据包经过 OUTPUT 链到 POSTROUTING 链,在 POSTROUTING 链做 SNAT 转发数据包到访问节点。
流程如下:
```
// 从集群内发出的数据包先走 OUTPUT
// OUTPUT 链接收数据包,继续进入 POSTROUTING 链
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
DOCKER all -- anywhere !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
// POSTROUTING 实现出去流量的转发
// 流量将进入 KUBE-POSTROUTING 链
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
KUBE-POSTROUTING all -- anywhere anywhere /* kubernetes postrouting rules */
Chain KUBE-POSTROUTING (1 references)
target prot opt source destination
MASQUERADE all -- anywhere anywhere /* Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose */ match-set KUBE-LOOP-BACK dst,dst,src
RETURN all -- anywhere anywhere mark match ! 0x4000/0x4000
MARK all -- anywhere anywhere MARK xor 0x4000
MASQUERADE all -- anywhere anywhere /* kubernetes service traffic requiring SNAT */ random-fully
```
`KUBE-POSTROUTING` 的规则非常重要,值得拆开好好讲。
**规则1: MASQUERADE**
`MASQUERADE all -- anywhere anywhere /* Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose */ match-set KUBE-LOOP-BACK dst,dst,src`
这条规则是给 pod 访问自己用的,如果 pod 要访问自己,那就别匹配其它规则了,直接将流量转给自己。这称为发卡弯(hairping)模式。
这也是为什么这条规则在 `KUBE-POSTROUTING` 链最前面的原因。
继续往下看,我们的任务是探索后端服务的数据包又该怎么回去的。
**规则2: RETURN**
`RETURN all -- anywhere anywhere mark match ! 0x4000/0x4000`
啊哈,还记得我们前面留的问题为什么要打 `MARK:0x4000` 标签吗?
答案就在这条规则,如果包不带 `MARK:0x4000` 则退出 `KUBE-POSTROUTING`,意味着只有带 `MARK:0x4000` 标签的数据包才会做 SNAT。`MARK:0X4000` 实际是用来区分是否做 NAT 的标签。
我们的数据包是带 `MARK:0X4000` 标签的,继续往下走。
**规则3: MARK**
`MARK all -- anywhere anywhere MARK xor 0x4000`
`MARK xor 0x4000` 清除数据包的 `MARK:0X4000` 标签。
**规则4: MASQUERADE**
`MASQUERADE all -- anywhere anywhere /* kubernetes service traffic requiring SNAT */ random-fully`
终于到 SNAT 规则了,对数据包做 SNAT,将请求转发回去。
# 小结
本文主要通过 kubernetes service 的 ClusterIP 示例介绍了 iptables 结合 ipvs 是如何管理集群内流量的。关于 NodePort,Ingress,LoadBalancer 并未在文中的讨论范围之内。后续看是否需要继续介绍其它 service 类型。
下一讲会继续介绍 kube-proxy 是如何实现 ipvs/iptables 管理的,力图做到原理实现一网打尽,敬请期待~
# 参考文章
- [【深度】这一次,彻底搞懂 kube-proxy IPVS 模式的工作原理!](https://cloud.tencent.com/developer/article/1832918)
- [一文读懂 K8S Service 原理](https://mp.weixin.qq.com/s/HgQrub757qhIBCYO45o4NQ)
- [IPVS-Based In-Cluster Load Balancing Deep Dive](https://kubernetes.io/blog/2018/07/09/ipvs-based-in-cluster-load-balancing-deep-dive/)
- [一文看懂 Kube-proxy](https://zhuanlan.zhihu.com/p/337806843)
---
kubernetes service 原理精讲的更多相关文章
- 深入Java核心 Java内存分配原理精讲
深入Java核心 Java内存分配原理精讲 栈.堆.常量池虽同属Java内存分配时操作的区域,但其适用范围和功用却大不相同.本文将深入Java核心,详细讲解Java内存分配方面的知识. Java内存分 ...
- 小书MybatisPlus第7篇-代码生成器的原理精讲及使用方法
本文是本系列文章的第七篇,前6篇访问地址如下: 小书MybatisPlus第1篇-整合SpringBoot快速开始增删改查 小书MybatisPlus第2篇-条件构造器的应用及总结 小书Mybatis ...
- MOS管工作原理精讲
- 小书MybatisPlus第8篇-逻辑删除实现及API细节精讲
本文为Mybatis Plus系列文章的第8篇,前7篇访问地址如下: 小书MybatisPlus第1篇-整合SpringBoot快速开始增删改查 小书MybatisPlus第2篇-条件构造器的应用及总 ...
- Keepalived原理与实战精讲--VRRP协议
. 前言 VRRP(Virtual Router Redundancy Protocol)协议是用于实现路由器冗余的协议,最新协议在RFC3768中定义,原来的定义RFC2338被废除,新协议相对还简 ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 《VC++ 6简明教程》即VC++ 6.0入门精讲 学习进度及笔记
VC++6.0入门→精讲 2013.06.09,目前,每一章的“自测题”和“小结”三个板块还没有看(备注:第一章的“实验”已经看完). 2013.06.16 第三章的“实验”.“自测题”.“小结”和“ ...
- iOS开发——语法篇OC篇&高级语法精讲二
Objective高级语法精讲二 Objective-C是基于C语言加入了面向对象特性和消息转发机制的动态语言,这意味着它不仅需要一个编译器,还需要Runtime系统来动态创建类和对象,进行消息发送和 ...
- Linux实战教学笔记18:linux三剑客之awk精讲
Linux三剑客之awk精讲(基础与进阶) 标签(空格分隔): Linux实战教学笔记-陈思齐 快捷跳转目录: * 第1章:awk基础入门 * 1.1:awk简介 * 1.2:学完awk你可以掌握: ...
- 总结:Java 集合进阶精讲1
知识点:Java 集合框架图 总结:Java 集合进阶精讲1 总结:Java 集合进阶精讲2-ArrayList 集合进阶1---为集合指定初始容量 集合在Java编程中使用非常广泛,当容器的量变得非 ...
随机推荐
- android无障碍开发 企业微信 机器人
实现 Android 无障碍开发 企业微信 机器人 作为一名新入行的开发者,你可能对如何开发一个支持企业微信的无障碍机器人感到迷茫.在这篇文章中,我将为你详细讲解实现这一功能的流程和代码示例. 流程概 ...
- Typecho去除更新检测和后台日志
Typecho去除官方日志 打开 admin/index.php,找到下面的代码并删除,在 93-102 行. 代码: <div class="col-mb-12 col-tb-4&q ...
- Linux 通过docker安装nginx,.net core sdk或运行时安装到Linux
1.Linux docker通过yum安装 https://blog.csdn.net/GMingZhou/article/details/94024453 https://qizhanming.co ...
- linux服务问题传文件连不上问题远程问题等
通过iptables相关命令实现防火墙的打开和关闭 1.首先可以在打开的终端使用iptables --help查看帮助使用命令: 2.查看防火墙状态:service iptables status(此 ...
- Linux云服务器如何安装配置Redis
为大家分享linux云服务器如何安装配置Redis,示例为CentOS7系统 Redis 是一款开源的高性能内存数据库,以极速读写(微秒级)和丰富数据结构著称,支持字符串.哈希.列表等类型,兼具持久化 ...
- winform 实现太阳,地球,月球 运作规律https://www.cnblogs.com/axing/p/18762710
无图眼吊(动图) 缘由 最近我太太在考公学习,给我出了两道高中地理知识的题目,把我问的一头雾水,题目是这样的 第一题 第二题 看到这两道题,当时大脑飞速运转,差点整个身体都在自转了,所以产生了个 ...
- 文件上传fuzz工具-Upload_Auto_Fuzz
一.工具介绍 在日常遇到文件上传时,如果一个个去测,会消耗很多时间,如果利用工具去跑的话就会节省很多时间,本Burp Suite插件专为文件上传漏洞检测设计,提供自动化Fuzz测试,共300+条p ...
- 使用键盘控制gazebo小车模型运动
博客地址:https://www.cnblogs.com/zylyehuo/ gazebo小车模型创建详见另一篇博客 博客地址:gazebo小车模型(附带仿真环境) - zylyehuo - 博客园 ...
- Audio DSP 链接脚本文件解析
上篇文章(智能手表音乐播放功耗的优化)讲了怎么优化音乐场景下的功耗,其中第二点是优化memory的布局.那么在哪里优化memory的布局呢?就是在本文要讲的链接脚本(ld)文件里.作为audio DS ...
- BUUCTF---rsa_output
题目 点击查看代码 {21058339337354287847534107544613605305015441090508924094198816691219103399526800112802416 ...