python pandas 数据处理
pandas是基于numpy包扩展而来的,因而numpy的绝大多数方法在pandas中都能适用。
pandas中我们要熟悉两个数据结构Series 和DataFrame
Series是类似于数组的对象,它有一组数据和与之相关的标签组成。
import pandas as pd object=pd.Series([2,5,8,9]) print(object)
结果为:
0 2
1 5
2 8
3 9
dtype: int64
结果中包含一列数据和一列标签
我们可以用values和index分别进行引用
print(object.values)
print(object.index)
结果为:
[2 5 8 9]
RangeIndex(start=0, stop=4, step=1)
我们还可以按照自己的意愿构建标签
object=pd.Series([2,5,8,9],index=['a','b','c','d']) print(object)
结果为:
a 2
b 5
c 8
d 9
dtype: int64
我们还可以对序列进行运算
print(object[object>5])
结果为
c 8
d 9
dtype: int64
也可以把Series看成一个字典,使用in进行判断
print('a' in object)
结果为:
True
另外,值是不能直接被索引到的
print(2 in object)
结果为:
False
Series中的一些方法,
isnull或者notnull可以用于判断数据中缺失值情况
name或者index.name可以对数据进行重命名
DataFrame数据框,也是一种数据结构,和R中的数据框类似
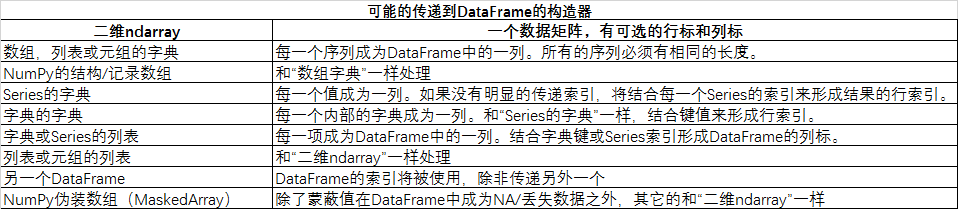
data={'year':[2000,2001,2002,2003],
'income':[3000,3500,4500,6000]}
data=pd.DataFrame(data)
print(data)
结果为:
income year
0 3000 2000
1 3500 2001
2 4500 2002
3 6000 2003
data1=pd.DataFrame(data,columns=['year','income','outcome'],
index=['a','b','c','d'])
print(data1)
结果为:
year income outcome
a 2000 3000 NaN
b 2001 3500 NaN
c 2002 4500 NaN
d 2003 6000 NaN
新增加列outcome在data中没有,则用na值代替
索引的几种方式
print(data1['year'])
print(data1.year)
两种索引是等价的,都是对列进行索引,结果为:
a 2000
b 2001
c 2002
d 2003
Name: year, dtype: int64
对行进行索引,则是另外一种形式
print(data1.ix['a'])
结果为:
year 2000
income 3000
outcome NaN
Name: a, dtype: object
print(data1[1:3])
或者也可以用切片的形式
结果为:
year income outcome
b 2001 3500 NaN
c 2002 4500 NaN
增加和删除列
data1['money']=np.arange(4)
增加列为money
year income outcome money
a 2000 3000 NaN 0
b 2001 3500 NaN 1
c 2002 4500 NaN 2
d 2003 6000 NaN 3
del data1['outcome']
删除列结果为:
year income money
a 2000 3000 0
b 2001 3500 1
c 2002 4500 2
d 2003 6000 3
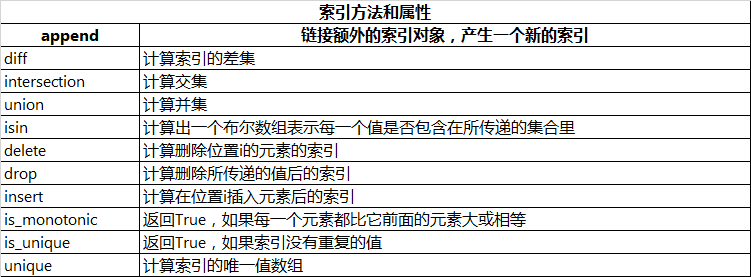
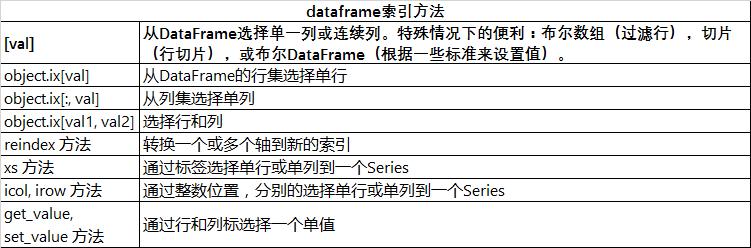
pandas中的主要索引对象以及相对应的索引方法和属性

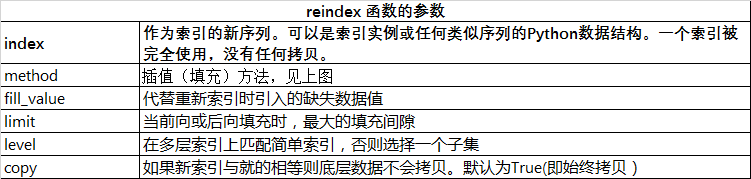
此外还有一个reindex函数可以重新构建索引
data={'year':[2000,2001,2002,2003],
'income':[3000,3500,4500,6000]}
data1=pd.DataFrame(data,columns=['year','income','outcome'],
index=['a','b','c','d'])
data2=data1.reindex(['a','b','c','d','e'])
print(data2)
结果为:


data2=data1.reindex(['a','b','c','d','e'],method='ffill')
print(data2)
使用方法后的结果为:

索引删除以及过滤等相关方法
print(data1.drop(['a']))
结果为:
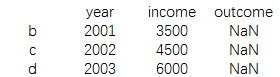
print(data1[data1['year']>2001])
结果为:
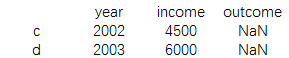
print(data1.ix[['a','b'],['year','income']])
结果为 :
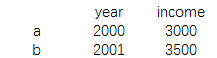
print(data1.ix[data1.year>2000,:2])
结果为:
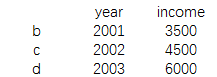
详细的索引过滤方法如下:
dataframe的算法运算
data={'year':[2000,2001,2002,2003],
'income':[3000,3500,4500,6000]}
data1=pd.DataFrame(data,columns=['year','income','outcome'],
index=['a','b','c','d'])
data2=pd.DataFrame(data,columns=['year','income','outcome'],
index=['a','b','c','d'])
data1['outcome']=range(1,5)
data2=data2.reindex(['a','b','c','d','e'])
print(data1.add(data2,fill_value=0))
结果为:
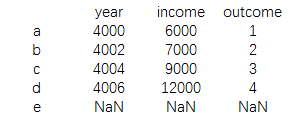
对dataframe进行排序
data=pd.DataFrame(np.arange(10).reshape((2,5)),index=['c','a'],
columns=['one','four','two','three','five']) print(data)
结果为:

print(data.sort_index())
结果为:
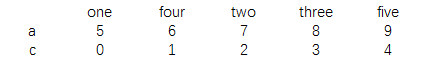
print(data.sort_index(axis=1))
结果为:

print(data.sort_values(by='one'))
结果为:
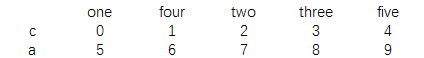
print(data.sort_values(by='one',ascending=False))
结果为:

这里是对结果进行降序排列
汇总以及统计描述
data=pd.DataFrame(np.arange(10).reshape((2,5)),index=['c','a'],
columns=['one','four','two','three','five']) print(data.describe())
结果为:

print(data.sum())
结果为:
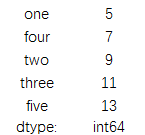
print(data.sum(axis=1))
结果为:
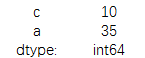
详细约简方法

相关描述统计函数

相关系数与协方差
data=pd.DataFrame(np.random.random(20).reshape((4,5)),index=['c','a','b','c'],
columns=['one','four','two','three','five']) print(data)
结果为:
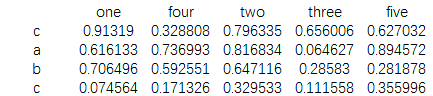
print(data.one.corr(data.three))
one和three的相关系数为:
0.706077105725
print(data.one.cov(data.three))
one和three的协方差为:
0.0677896135613
print(data.corrwith(data.one))
one和所有列的相关系数:

唯一值,成员资格等方法
data=pd.Series(['a','a','b','b','b','c','d','d']) print(data.unique())
结果为:
['a' 'b' 'c' 'd']
print(data.isin(['b']))
结果为:
0 False
1 False
2 True
3 True
4 True
5 False
6 False
7 False
dtype: bool
print(pd.value_counts(data.values,sort=False))
结果为:
d 2
c 1
b 3
a 2
dtype: int64

缺失值处理
data=pd.Series(['a','a','b',np.nan,'b','c',np.nan,'d']) print(data.isnull())
结果为:
0 False
1 False
2 False
3 True
4 False
5 False
6 True
7 False
dtype: bool
print(data.dropna())
结果为:
0 a
1 a
2 b
4 b
5 c
7 d
dtype: object
print(data.ffill())
结果为:
0 a
1 a
2 b
3 b
4 b
5 c
6 c
7 d
dtype: object
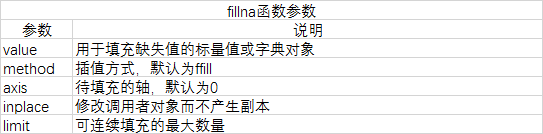
print(data.fillna(0))
结果为:
0 a
1 a
2 b
3 0
4 b
5 c
6 0
7 d
dtype: object

层次化索引
可以对数据进行多维度的索引
data = pd.Series(np.random.randn(10), index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 2, 3, 1, 2, 2, 3]]) print(data)
结果为:

print(data.index)
结果为:
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],
labels=[[0, 0, 0, 1, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 1, 2]]) print(data['c'])
结果为:

print(data[:,2])
结果为:

print(data.unstack())
结果为:
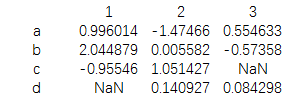
把数据转换成为一个dataframe
print(data.unstack().stack())

unstack()的逆运算
了解这些,应该可以进行一些常规的数据处理了。
python pandas 数据处理的更多相关文章
- Python———pandas数据处理
pandas模块 更高级的数据分析工具基于NumPy构建包含Series和DataFrame两种数据结构,以及相应方法 调用方法:from pandas import Series, DataFra ...
- Python——pandas数据处理(python programming)
- Python空间数据处理环境搭
Python空间数据处理环境搭 Conda的下载和安装 什么是Conda? 官方定义:Package, dependency and environment management for any la ...
- Python Pandas的使用 !!!!!详解
Pandas是一个基于python中Numpy模块的一个模块 Python在数据处理和准备⽅⾯⼀直做得很好,但在数据分析和建模⽅⾯就差⼀些.pandas帮助填补了这⼀空⽩,使您能够在Python中执 ...
- python & pandas链接mysql数据库
Python&pandas与mysql连接 1.python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.con ...
- Python pandas ERROR 2006 (HY000): MySQL server has gone away
之前在做python pandas大数据分析的时候,在将分析后的数据存入mysql的时候报ERROR 2006 (HY000): MySQL server has gone away 原因分析:在对百 ...
- python地理数据处理库geopy
http://blog.csdn.net/pipisorry/article/details/52205266 python地理位置处理 python地理编码地址以及用来处理经纬度的库 GeoDjan ...
- Python+Pandas 读取Oracle数据库
Python+Pandas 读取Oracle数据库 import pandas as pd from sqlalchemy import create_engine import cx_Oracle ...
- 看到篇博文,用python pandas改写了下
看到篇博文,https://blog.csdn.net/young2415/article/details/82795688 需求是需要统计部门礼品数量,自己简单绘制了个表格,如下: 大意是,每个部门 ...
随机推荐
- node.js系列笔记之node.js初识《一》
node.js系列笔记之node.js初识<一> 一:环境说明 1.1 Linux系统CentOS 5.8 1.2 nodejs v0.10.15 1.3 nodejs源码下载地址 htt ...
- 从0开始LInux配置PHP开发环境
主要参考 http://www.cnblogs.com/Fly-sky/p/3770305.html 次要参考 http://www.cnblogs.com/mchina/archive/2012/1 ...
- reading words in your computer and changing to female voice, linux festival text2wave saving wav files
on a brand new linux PC, e.g. ubuntu 14.04 amd64 To hear voice sudo apt-get install festival -y then ...
- python cookbook学习笔记 第一章 文本(2)
1.6合并字符串 ka=list('kaluoc') #字符串转成字符串列表 print ''.join(ka) #大量的字符串相连,join是最高效的 print '%s%s something % ...
- 分享一套 CodeSmit 代码生成模板。
分享一套 CodeSmit 代码生成模板. 住博客园 5 年了,以前也发过一些博文,但都在 一天后 / 几周后 / 几年后 将它删了:因为感觉代码写得不好:不清晰或侵入太大,哪怕只有一句侵入. 可是最 ...
- STM8S TIM1 PWM初始化设置
#define TIM1_DIV1 (uint16)(1-1) #define TIM1_DIV2 (uint16)(2-1) #define TIM1_DIV4 (uint16)(4-1) #def ...
- Linux-gate.so技术细节
1. linux-gate.so是什么参考这里:http://www.trilithium.com/johan/2005/08/linux-gate/简而言之,linux-gate.so是为了实现用户 ...
- .NET基础——方法
这一篇,我们来学习C#中的方法——函数 1. 方法的功能 方法的功能:用来复用代码的,当我们在一个程序中反复的写了同样的代码,我们就可以把需要重复写的代码定义在一个方法中,用到的时候只需要调用就可 ...
- 编译 MVC View
默认MVC的 View页面 不参与编译,当更改view对应model后,view编译也能通过,或者页面有错误的服务端代码时也不会报错. 那么如何在编译的时候能让View中的错误也不能通过呢.经过查找找 ...
- java基础练习 2
public class Second { /* * 打印出杨辉三角形(要求打印出10行如下图) */ public static void main(String[] args){ int i,j, ...