Generative Modeling by Estimating Gradients of the Data Distribution
概
当前生成模型, 要么依赖对抗损失(GAN), 要么依赖替代损失(VAE), 本文提出了基于score matching 训练, 以及利用annealed Langevin dynamics推断的模型, 思想非常有趣.
主要内容
Langevin dynamics
对于分布\(p(x)\), 我们可以通过下列方式迭代生成
\]
其中\(\tilde{x}_0 \sim \pi(x)\)来自一个先验分布, \(z_t \sim \mathcal{N}(0, I)\). 当步长\(\epsilon \rightarrow 0\)并且\(T \rightarrow +\infty\)的时候, \(\tilde{x}_T\)可以认为是从\(p(x)\)中采样的样本.
注: 一般的Langevin, dynamics还需要在每一次迭代后计算一个接受概率然后判断是否接受, 不过在实际中这一步往往可以省略.
Score Matching
通过上述的迭代可以发现, 我们只需要获得\(\nabla_x \log p(x)\)即可采样\(x\), 我们可以期望通过下面的方式, 通过一个网络\(s_{\theta}(x)\)来逼近\(\nabla_x \log p_{data}(x)\):
\]
但是在实际中, 先验\(\log p_{data}(x)\)也是未知的, 幸运的是上述公式等价于:
\]
注: 见 score matching
Denoising Score Matching
一个共识是, 所获得的数据往往是一个低维流形, 即其内在的维度实际上很低. 所以\(\mathbb{E}_{p_{data}(x)}\)在实际中会出现高密度的区域估计得很好, 但是低密度得区域估计得非常差. Denosing Score Matching提高了一个较为鲁棒的替代方法:
\]
当优化得足够好的时候,
\]
实际中, 通常取\(q_{\sigma}(\tilde{x}|x) = \mathcal{N}(\tilde{x}|x, \sigma^2 I)\), 相当于在真实数据\(x\)上加了一个扰动, 当扰动足够小(\(\sigma\)足够小)的时候, \(q_{\sigma}(x) \approx p_{data}(x)\), 则\(s_{\theta^*}(x) \approx \nabla_x \log p_{data}(x)\).
注: 为啥期望部分要有\(p_{data}\)? 实际上上述目标和score matching依旧是等价的.
Noise Conditional Score Networks
Slow mixing of Langevin dynamics
假设\(p_{data}(x) = \pi p_1(x) + (1 - \pi)p_2(x)\), 且\(p_1, p_2\)的支撑集合是互斥的, 那么 \(\nabla_{x} \log p_{data}(x)\)要么为\(\nabla_{x} \log p_{1}(x)\)或者\(\nabla_{x} \log p_{2}(x)\), 与\(\pi\)没有丝毫关联, 这会导致训练的结果与\(\pi\)也没有关联. 在实际中, 若\(p_1, p_2\)近似互斥, 也会产生类似的情况:
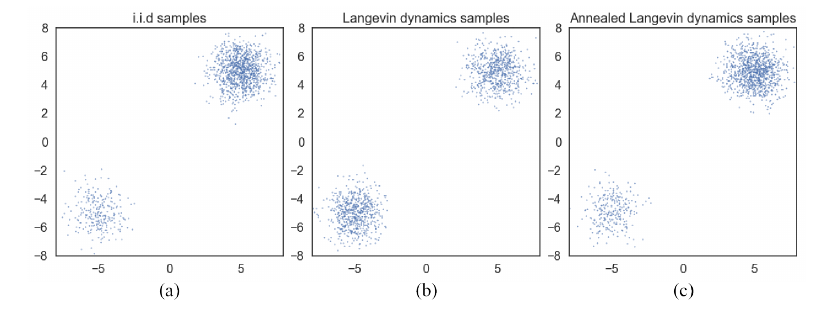
如上图所示, 通过Langevin dynamics采样的点几乎是1:1的, 这与真实的分布便有了出入.
作者的想法是, 设计一个noise conditional score networks:
\]
给定不同的\(\sigma\)其拟合不同扰动大小的\(p_{\sigma}\), 在采样中, 首先用大一点的\(\sigma\), 然后再逐步缩小, 这便是一种退火的思想. 显然, 一开始用大一点的\(\sigma\)能够为后面的采样提供更好更鲁棒的初始点.
损失函数
设定\(\sigma_i, i=1,2,\cdots, L\), 且满足:
\]
即一个等比例(缩小)的数列.
对于每个\(\sigma\)采用如下损失:
\frac{1}{2} \mathbb{E}_{p_{data}(x)} \mathbb{E}_{\mathcal{N}(\tilde{x}|x, \sigma I)} [\| s_{\theta} (\tilde{x}, \sigma) + \frac{\tilde{x} - x}{\sigma^2} \|_2^2].
\]
注: \(\nabla_{\tilde{x}} q_{\sigma}(\tilde{x}|x) = -\frac{\tilde{x} - x}{\sigma^2}\).
于是总损失为
\]
\(\lambda(\sigma_i)\)为权重系数.
Annealed Langevin dynamics
Input: \(\{\sigma_i\}_{i=1}^L, \epsilon, T\);
- 初始化\(x_0\);
- For \(i=1,2,\cdots, L\) do:
- \(\alpha_i \leftarrow \epsilon \cdot \sigma_i^2 / \sigma_L^2\);
- For \(t=1,2,\cdots, T\) do:
- 采样\(z_t \sim \mathcal{N}(0, I)\);
- \(x_t \leftarrow x_{t-1} + \frac{\alpha_i}{2}s_{\theta}(x_{t-1}, \sigma) + \sqrt{\alpha_i} z_t\);
- \(x_0 \leftarrow x_T\);
Output: \(x_T\).
细节
关于参数\(\lambda(\sigma)\)的选择:
作者推荐选择\(\lambda(\sigma) = \sigma^2\), 因为当优化到最优的时候, \(\|s_{\theta}(x, \sigma)\|_2 \propto 1 / \sigma\), 故\(\sigma^2 \ell(\theta;\sigma) = \frac{1}{2}\mathbb{E}[\|\sigma s_{\theta}(x, \sigma) + \frac{\tilde{x} - x}{\sigma} \|_2^2]\), 其中\(\sigma s_{\theta}(x, \sigma) \propto 1, \frac{\tilde{x} - x}{\sigma} \sim \mathcal{N}(0, I)\), 故\(\sigma^2 \ell_{\theta,\sigma}\)与\(\sigma\)无关.关于\(\alpha_i \leftarrow \epsilon \cdot \sigma_i^2 / \sigma_L^2\):
对于一次Langevin dynamic, 其获得的信息为: \(\frac{\alpha_i}{2} s_{\theta}(x_{t-1}, \sigma)\), 其噪声为\(\sqrt{\alpha_i}z_t\), 故其信噪比(signal-to-noise)为(应该是element-wise的计算?)
\]
当我们按照算法中的取法时, 我们有
\|\frac{\alpha_i s_{\theta}(x, \sigma_i)}{2 \sqrt{\alpha_i} z}\|_2^2
&\approx\frac{\alpha_i \| s_{\theta}(x, \sigma_i)\|_2^2}{4} \\
&\propto\frac{\|\sigma_i s_{\theta}(x, \sigma_i)\|_2^2}{4} \\
&\propto \frac{1}{4}.
\end{array}
\]
故采用此策略能够保证SNR保持一个稳定的值.
代码
Generative Modeling by Estimating Gradients of the Data Distribution的更多相关文章
- 泡泡一分钟:GEN-SLAM - Generative Modeling for Monocular Simultaneous Localization and Mapping
张宁 GEN-SLAM - Generative Modeling for Monocular Simultaneous Localization and Mapping GEN-SLAM - 单 ...
- Statistics : Data Distribution
1.Normal distribution In probability theory, the normal (or Gaussian or Gauss or Laplace–Gauss) dist ...
- 论文笔记之:Generative Adversarial Nets
Generative Adversarial Nets NIPS 2014 摘要:本文通过对抗过程,提出了一种新的框架来预测产生式模型,我们同时训练两个模型:一个产生式模型 G,该模型可以抓住数据分 ...
- [GAN] Generative networks
中文版:https://zhuanlan.zhihu.com/p/27440393 原文版:https://www.oreilly.com/learning/generative-adversaria ...
- Generative model 和Discriminative model
学习音乐自动标注过程中设计了有关分类型模型和生成型模型的东西,特地查了相关资料,在这里汇总. http://blog.sina.com.cn/s/blog_a18c98e50101058u.html ...
- 生成模型(Generative)和判别模型(Discriminative)
生成模型(Generative)和判别模型(Discriminative) 引言 最近看文章<A survey of appearance models in visual object ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- (转)Introductory guide to Generative Adversarial Networks (GANs) and their promise!
Introductory guide to Generative Adversarial Networks (GANs) and their promise! Introduction Neural ...
- SalGAN: Visual saliency prediction with generative adversarial networks
SalGAN: Visual saliency prediction with generative adversarial networks 2017-03-17 摘要:本文引入了对抗网络的对抗训练 ...
随机推荐
- keybd_event模拟键盘按键,mouse_event怎么用
从 模仿UP主,用Python实现一个弹幕控制的直播间! - 蛮三刀酱 - 博客园 (cnblogs.com) 知道了 PyAutoGUI: * Moving the mouse and clicki ...
- day13 cookie与session和中间件
day13 cookie与session和中间件 今日内容概要 cookie与session简介 django操作cookie与session django中间件简介 如何自定义中间件 csrf跨站请 ...
- day25 组合和内置函数
day25 组合和内置函数 一.组合 # 解决类与类之间代码冗余问题: 1. 继承 2. 组合 组合:一个对象拥有一个属性, 属性的值必须是另外一个对象 继承满足的是:什么是什么的关系 # is-a ...
- 虚拟机中安装centos系统的详细过程
linux-centos的安装 检查电脑是否开启虚拟化,只有开启虚拟化才能安装虚拟机 新建虚拟机 鼠标点进去,选中红框所示,回车 登录: 输入默认用户名(超级管理员 root) 密码:安装时设置的密码
- 【leetcode】952. Largest Component Size by Common Factor(Union find)
You are given an integer array of unique positive integers nums. Consider the following graph: There ...
- Linux学习 - 分区与文件系统
一.分区类型 1 主分区:总共最多只能分四个 2 扩展分区:只能有一个(主分区中的一个分区),不能存储数据和格式化,必须再划分成逻辑分区 才 ...
- Spring Batch Event Listeners
Learn to create and configure Spring batch's JobExecutionListener (before and after job), StepExecut ...
- 拷贝txt文本中的某行的数据到excel中
package com.hope.day01;import java.io.*;import java.util.ArrayList;public class HelloWorld { publ ...
- java通过jdbc连接数据库并更新数据(包括java.util.Date类型数据的更新)
一.步骤 1.获取Date实例,并通过getTime()方法获得毫秒数: 2.将获取的毫秒数存储到数据库中,注意存储类型为nvarchar(20): 3.读取数据库的毫秒数,作为Date构造方法的参数 ...
- logstash 正则表达式
正则表达式 3. 使用给定好的符号去表示某个含义 4. 例如.代表任意字符 5. 正则符号当普通符号使用需要加反斜杠 正则的发展 6. 普通正则表达式 7. 扩展正则表达式 普通正则表达式 . 任意一 ...