C++ 11 多线程初探-std::memory_order
std::memory_order(可译为内存序,访存顺序)
动态内存模型可理解为存储一致性模型,主要是从行为(behavioral)方面来看多个线程对同一个对象同时(读写)操作时(concurrency)所做的约束,动态内存模型理解起来稍微复杂一些,涉及了内存,Cache,CPU 各个层次的交互,尤其是在共享存储系统中,为了保证程序执行的正确性,就需要对访存事件施加严格的限制。
假设存在两个共享变量a, b,初始值均为 0,两个线程运行不同的指令,如下表格所示,线程 1 设置 a 的值为 1,然后设置 R1 的值为 b,线程 2 设置 b 的值为 2,并设置 R2 的值为 a,请问在不加任何锁或者其他同步措施的情况下,R1,R2 的最终结
果会是多少?
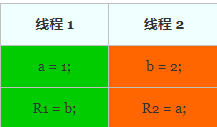
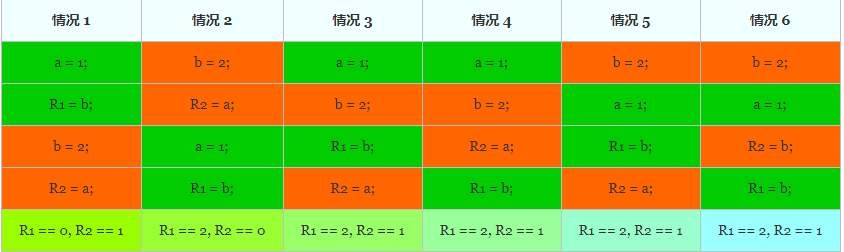
由于没有施加任何同步限制,两个线程将会交织执行,但交织执行时指令不发生重排,即线程 1 中的 a = 1 始终在 R1 = b 之前执行,而线程 2 中的 b = 2 始终在 R2 = a 之前执行 ,因此可能的执行序列共有 4!/(2!*2!) = 6 种
多线程环境下顺序一致性包括两个方面,(1). 从多个线程平行角度来看,程序最终的执行结果相当于多个线程某种交织执行的结果,(2)从单个线程内部执行顺序来看,该线程中的指令是按照程序事先已规定的顺序执行的(即不考虑运行时 CPU 乱序执行和 Memory Reorder)。当然,顺序一致性代价太大,不利于程序的优化,现在的编译器在编译程序时通常将指令重新排序。对编译器和 CPU 作出一定的约束才能合理正确地优化你的程序,那么这个约束是什么呢?答曰:内存模型。C++程序员要想写出高性能的多线程程序必须理解内存模型,编译器会给你的程序做优化(静态),CPU为了提升性能也有乱序执行(动态),总之,程序在最终执行时并不会按照你之前的原始代码顺序来执行,因此内存模型是程序员、编译器,CPU 之间的契约,遵守契约后大家就各自做优化,从而尽可能提高程序的性能。
C++11 中规定了 6 中访存次序(Memory Order),如下:
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
上述 6 中访存次序(内存序)分为 3 类,顺序一致性模型(std::memory_order_seq_cst),Acquire-Release 模型(std::memory_order_consume, std::memory_order_acquire, std::memory_order_release, std::memory_order_acq_rel,) (获取/释放语义模型
)和 Relax 模型(std::memory_order_relaxed)(宽松的内存序列化模型)。
memory_order_relaxed: 只保证当前操作的原子性,不考虑线程间的同步,其他线程可能读到新值,也可能读到旧值。比如 C++ shared_ptr 里的引用计数,我们只关心当前的应用数量,而不关心谁在引用谁在解引用。
memory_order_release:(可以理解为 mutex 的 unlock 操作)
- 对写入施加 release 语义(store),在代码中这条语句前面的所有读写操作都无法被重排到这个操作之后,即 store-store 不能重排为 store-store, load-store 也无法重排为 store-load
- 当前线程内的所有写操作,对于其他对这个原子变量进行 acquire 的线程可见
- 当前线程内的与这块内存有关的所有写操作,对于其他对这个原子变量进行 consume 的线程可见
memory_order_acquire: (可以理解为 mutex 的 lock 操作)
- 对读取施加 acquire 语义(load),在代码中这条语句后面所有读写操作都无法重排到这个操作之前,即 load-store 不能重排为 store-load, load-load 也无法重排为 load-load
- 在这个原子变量上施加 release 语义的操作发生之后,acquire 可以保证读到所有在 release 前发生的写入,举个例子:
c = 0;
thread 1:{
a = 1;
b.store(2, memory_order_relaxed);
c.store(3, memory_order_release);
}
thread 2:{
while (c.load(memory_order_acquire) != 3) ; // 以下 assert 永远不会失败
assert(a == 1 && b == 2);
assert(b.load(memory_order_relaxed) == 2);
}
memory_order_consume:
- 对当前要读取的内存施加 release 语义(store),在代码中这条语句后面所有与这块内存有关的读写操作都无法被重排到这个操作之前
- 在这个原子变量上施加 release 语义的操作发生之后,acquire 可以保证读到所有在 release 前发生的并且与这块内存有关的写入,举个例子:
a = 0;
c = 0;
thread 1:{
a = 1;
c.store(3, memory_order_release);
}
thread 2:{
while (c.load(memory_order_consume) != 3) ;
assert(a == 1); // assert 可能失败也可能不失败
}
memory_order_acq_rel:
- 对读取和写入施加 acquire-release 语义,无法被重排
- 可以看见其他线程施加 release 语义的所有写入,同时自己的 release 结束后所有写入对其他施加 acquire 语义的线程可见
memory_order_seq_cst:(顺序一致性)
- 如果是读取就是 acquire 语义,如果是写入就是 release 语义,如果是读取+写入就是 acquire-release 语义
- 同时会对所有使用此 memory order 的原子操作进行同步,所有线程看到的内存操作的顺序都是一样的,就像单个线程在执行所有线程的指令一样
通常情况下,默认使用 memory_order_seq_cst,所以你如果不确定怎么这些 memory order,就用这个。
C++ 11 多线程初探-std::memory_order的更多相关文章
- 【转】C++ 11 并发指南一(C++ 11 多线程初探)
引言 C++ 11自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些C++ 11的新特性,算是记录一下自己学到的东西吧,和大家共勉. 相信Linux程序员都用过Pthrea ...
- C++11 并发指南一(C++11 多线程初探)
引言 C++11 自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些 C++11 的新特性,今后几篇博客我都会写一些关于 C++11 的特性,算是记录一下自己学到的东西吧, ...
- C++11 并发指南一(C++11 多线程初探)(转)
引言 C++11 自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些 C++11 的新特性,今后几篇博客我都会写一些关于 C++11 的特性,算是记录一下自己学到的东西吧, ...
- 【C/C++开发】C++11 并发指南一(C++11 多线程初探)
引言 C++11 自2011年发布以来已经快两年了,之前一直没怎么关注,直到最近几个月才看了一些 C++11 的新特性,今后几篇博客我都会写一些关于 C++11 的特性,算是记录一下自己学到的东西吧, ...
- 【C++】c++11多线程初探
相关头文件c++11 新标准中引入了四个头文件来支持多线程编程,他们分别是<atomic> ,<thread>,<mutex>,<condition_vari ...
- C++ 11 多线程下std::unique_lock与std::lock_guard的区别和用法
这里主要介绍std::unique_lock与std::lock_guard的区别用法 先说简单的 一.std::lock_guard的用法 std::lock_guard其实就是简单的RAII封装, ...
- C++11 多线程编程 使用lambda创建std::thread (生产/消费者模式)
要写个tcp server / client的博客,想着先写个c++11多线程程序.方便后面写博客使用. 目前c++11中写多线程已经很方便了,不用再像之前的pthread_create,c++11中 ...
- C++11多线程教学(二)
C++11多线程教学II 从我最近发布的C++11线程教学文章里,我们已经知道C++11线程写法与POSIX的pthreads写法相比,更为简洁.只需很少几个简单概念,我们就能搭建相当复杂的处理图片程 ...
- C++11多线程教学(一)
本篇教学代码可在GitHub获得:https://github.com/sol-prog/threads. 在之前的教学中,我展示了一些最新进的C++11语言内容: 1. 正则表达式(http://s ...
随机推荐
- [leetcode] 48. 旋转图像(Java)(模拟)
48. 旋转图像 模拟题,其实挺不喜欢做模拟题的... 其实这题一层一层的转就好了,外层转完里层再转,其实就是可重叠的子问题了. 转的时候呢,一个数一个数的转,一个数带动四个数.如图所示,2这个数应该 ...
- Linux系统挂载NFS文件系统
https://help.aliyun.com/document_detail/90529.html?spm=a2c4g.11186623.6.570.43212f30T5yM4w
- GO学习-(36) Go语言在select语句中实现优先级
Go语言在select语句中实现优先级 Go语言在select语句中实现优先级 select语句介绍 Go 语言中的 select语句用于监控并选择一组case语句执行相应的代码.它看起来类似于swi ...
- 华为计算平台MDC810发布量产
华为计算平台MDC810发布量产 塞力斯的发布会刚刚结束,会上塞力斯SF5自由远征版也确实让人眼前一亮. 全球首款4S级加速能力.1000+km续航新能源作为这款车的卖点. 续航1000+km成了最近 ...
- NVIDIA Jarvis:一个GPU加速对话人工智能应用的框架
NVIDIA Jarvis:一个GPU加速对话人工智能应用的框架 Introducing NVIDIA Jarvis: A Framework for GPU-Accelerated Conversa ...
- PEP 324 subprocess 新的进程模块 -- Python官方文档译文 [原创]
PEP 324 -- subprocess 新的进程模块(subprocess - New process module) 英文原文:https://www.python.org/dev/peps/p ...
- ubuntu 如何更改 grub 界面主题
ubuntu 如何更改 grub 界面主题 安装 Liunx 系统的人都知道,系统引导是通过 grub 去引导的,但是 grub 这个界面就很单调,大概是这样子的 这肯定不符合我们潮流青年的审美的~ ...
- Redis与DB的数据一致性解决方案(史上最全)
文章很长,而且持续更新,建议收藏起来,慢慢读! 高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : 极致经典 + 社群大片好评 < Java 高并发 三 ...
- MySQL的可重复读级别能解决幻读问题吗?
之前在深入了解数据库理论的时候,了解到事务的不同隔离级别可能存在的问题.为了更好的理解所以在MySQL数据库中测试复现这些问题.关于脏读和不可重复读在相应的隔离级别下都很容易的复现了. 但是对于幻读, ...
- Linux命令大全之挂载命令
理解:Linux挂载相当于Windows分配盘符 1.查询系统中已挂载的设备 mount 2.设置自动挂载 编辑文件/etc/fstab,把文件写入就可以启动自动挂载了, 注:一般不把光盘写入,如果写 ...