Xgboost调参总结
一、xgboost简介:
- 全称:eXtreme Gradient Boosting
- 作者:陈天奇(华盛顿大学博士)
- 基础:GBDT
- 所属:boosting迭代型、树类算法。
- 适用范围:分类、回归
- 优点:速度快、效果好、能处理大规模数据、支持多种语言、支持自定义损失函数等等。
- 缺点:算法参数过多,调参负责,对原理不清楚的很难使用好XGBoost。不适合处理超高维特征数据。
- 项目地址:https://github.com/dmlc/xgboost
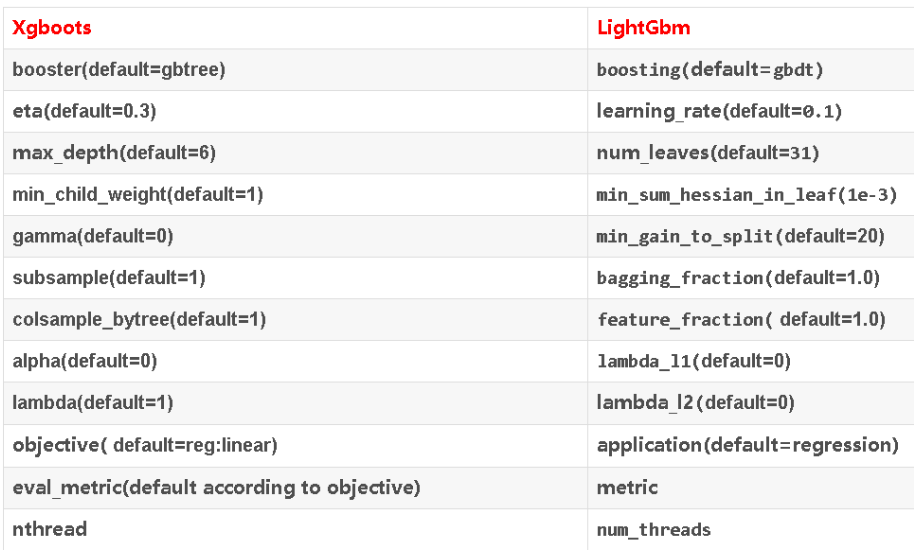
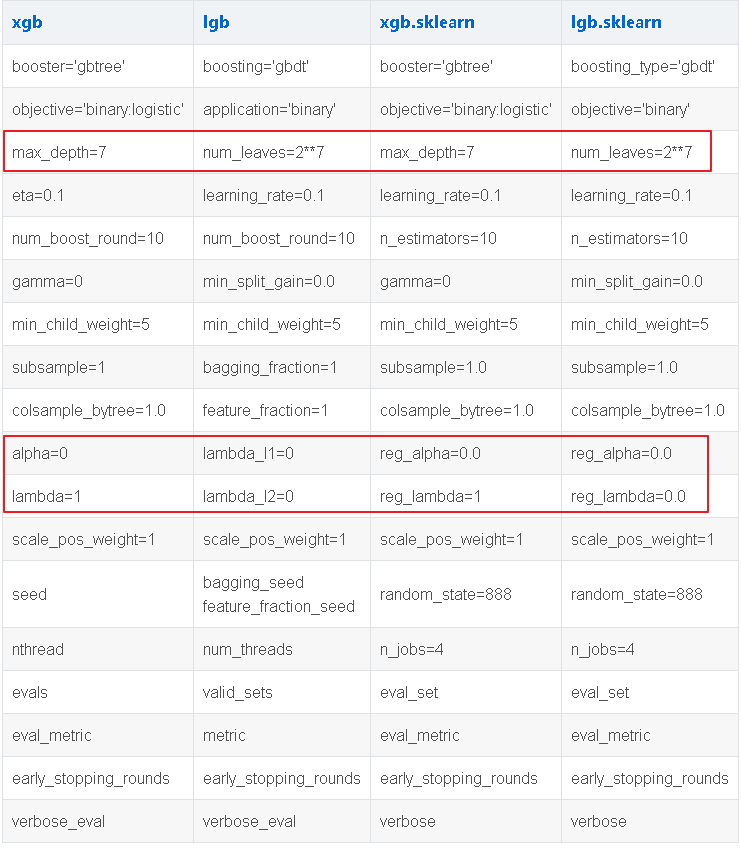
二、参数速查
参数分为三类:
- 通用参数:宏观函数控制。
- Booster参数:控制每一步的booster(tree/regression)。
- 学习目标参数:控制训练目标的表现。
二、回归
from xgboost.sklearn import XGBRegressor
from sklearn.model_selection import ShuffleSplit
import xgboost as xgb xgb_model_ = XGBRegressor(n_thread=8)
cv_split = ShuffleSplit(n_splits = 6,train_size=0.7,test_size=0.2)
xgb_params={'max_depth':[4,5,6,7],
'learning_rate':np.linspace(0.03,0.3,10),
'n_estimators':[100,200]} xgb_search = GridSearchCV(xgb_model_,
param_grid=xgb_params,
scoring='r2',
iid=False,
cv=5)
xgb_search.fit(gbdt_train_data,gbdt_train_label) print(xgb_search.grid_scores_)
print(xgb_search.best_params_)
print(xgb_search.best_score_)

1.xgboost不支持MAE的解决方法
xgboost支持自定义目标函数,但是要求目标函数必须二阶可到,我们必须显示给出梯度(一阶导)和海瑟矩阵(二阶导),但是MAE不可导,
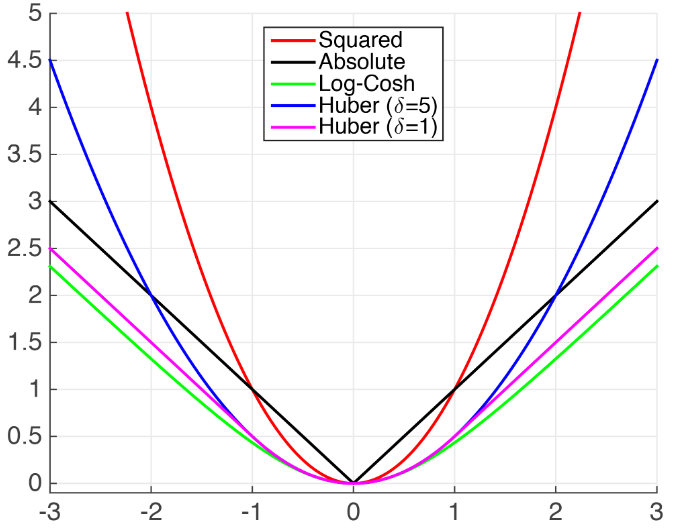
(1)xgboost自带的MSE,与MAE相距较远。比较接近的损失有Huber Loss 以及 Fair Loss。
- MSE
- Huber Loss
- Fair Loss:$c^2(\frac{|x|}{c}-ln(\frac{|x|}{c}+1))$
- Psuedo-Huber loss
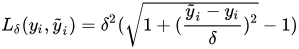
Fair Loss代码:代码来自solution in the Kaggle Allstate Challenge.
def fair_obj(preds, dtrain):
"""y = c * abs(x) - c**2 * np.log(abs(x)/c + 1)"""
x = preds - dtrain.get_labels()
c = 1
den = abs(x) + c
grad = c*x / den
hess = c*c / den ** 2
return grad, hess
Psuedo-Huber loss代码:
import xgboost as xgb dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(x_test, label=y_test) param = {'max_depth': 5}
num_round = 10 def huber_approx_obj(preds, dtrain):
d = preds - dtrain.get_labels() #remove .get_labels() for sklearn
h = 1 #h is delta in the graphic
scale = 1 + (d / h) ** 2
scale_sqrt = np.sqrt(scale)
grad = d / scale_sqrt
hess = 1 / scale / scale_sqrt
return grad, hess bst = xgb.train(param, dtrain, num_round, obj=huber_approx_obj)
具体可参考:kaggle 讨论 | Xgboost-How to use “mae” as objective function?
(2)自定义近似MAE导数:直接构造MAE的导数
- Log-Cosh Loss function:$\left.log(cosh(h(\mathbf{x}_{i})-y_{i}))\right.$,$\left.cosh(x)=\frac{e^{x}+e^{-x}}{2}\right.$
Log-cosh代码如下:
def log_cosh_obj(preds, dtrain):
x = preds - dtrain.get_labels()
grad = np.tanh(x)
hess = 1 / np.cosh(x)**2
return grad, hess
具体参考:kaggle 讨论
三、分类
前提:已经处理完所有数据,现在开始训练.
#Import libraries:
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn import cross_validation, metrics #Additional scklearn functions
from sklearn.grid_search import GridSearchCV #Perforing grid search import matplotlib.pylab as plt
%matplotlib inline
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4 train = pd.read_csv('train_modified.csv')
target = 'Disbursed'
IDcol = 'ID'
两种XGBoost:
- xgb - 直接引用xgboost。接下来会用到其中的“cv”函数。
- XGBClassifier - 是xgboost的sklearn包。这个包允许我们像GBM一样使用Grid Search 和并行处理。
test_results = pd.read_csv('test_results.csv')
def modelfit(alg, dtrain, dtest, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
'''
功能:训练,测试,输出AUC,画出重要特征的功能
参数:alg是分类器,dtrain是训练集(包括label),dtest是测试集(不包括label),predictors是要参与训练的特征(不包括label),
useTrainCV是是否要交叉验证,cv_folds是交叉验证的折数,early_stopping_rounds是到指定次数就停止继续迭代
'''
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
xgtest = xgb.DMatrix(dtest[predictors].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='auc', early_stopping_rounds=early_stopping_rounds, show_progress=False)
alg.set_params(n_estimators=cvresult.shape[0])
#训练
alg.fit(dtrain[predictors], dtrain['Disbursed'],eval_metric='auc')
#预测
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#输出accuracy、AUC分数
print "\nModel Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob)
#预测测试集,输出测试集的AUC分数
dtest['predprob'] = alg.predict_proba(dtest[predictors])[:,1]
results = test_results.merge(dtest[['ID','predprob']], on='ID')
print 'AUC Score (Test): %f' % metrics.roc_auc_score(results['Disbursed'], results['predprob'])
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
注意xgboost的sklearn包没有“feature_importance”这个量度,但是get_fscore()函数有相同的功能。
调参步骤:
选择较高的学习速率(learning rate)。一般情况下,学习速率的值为0.1。但是,对于不同的问题,理想的学习速率有时候会在0.05到0.3之间波动。选择对应于此学习速率的理想决策树数量。XGBoost有一个很有用的函数“cv”,这个函数可以在每一次迭代中使用交叉验证,并返回理想的决策树数量。
对于给定的学习速率和决策树数量,进行决策树特定参数调优(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。在确定一棵树的过程中,我们可以选择不同的参数,待会儿我会举例说明。
xgboost的正则化参数的调优。(lambda, alpha)。这些参数可以降低模型的复杂度,从而提高模型的表现。
降低学习速率,确定理想参数。
- max_depth = 5 :这个参数的取值最好在3-10之间。我选的起始值为5,但是你也可以选择其它的值。起始值在4-6之间都是不错的选择。
- min_child_weight = 1:在这里选了一个比较小的值,因为这是一个极不平衡的分类问题。因此,某些叶子节点下的值会比较小。
- gamma = 0: 起始值也可以选其它比较小的值,在0.1到0.2之间就可以。这个参数后继也是要调整的。
- subsample, colsample_bytree = 0.8: 这个是最常见的初始值了。典型值的范围在0.5-0.9之间。
- scale_pos_weight = 1: 这个值是因为类别十分不平衡。
- 注意,上面这些参数的值只是一个初始的估计值,后继需要调优。这里把学习速率就设成默认的0.1。然后用xgboost中的cv函数来确定最佳的决策树数量。前文中的函数可以完成这个工作。
参考文献:
【2】Complete Guide to Parameter Tuning in XGBoost (with codes in Python)
【3】xgboost调参(很全)
【5】机器学习算法之XGBoost(非常详细)
Xgboost调参总结的更多相关文章
- xgboost 调参参考
XGBoost的参数 XGBoost的作者把所有的参数分成了三类: 1.通用参数:宏观函数控制. 2.Booster参数:控制每一步的booster(tree/regression). 3.学习目标参 ...
- 机器学习--Xgboost调参
Xgboost参数 'booster':'gbtree', 'objective': 'multi:softmax', 多分类的问题 'num_class':10, 类别数,与 multisoftma ...
- 【转载】XGBoost调参
General Parameters: Guide the overall functioning Booster Parameters: Guide the individual booster ( ...
- xgboost 调参 !
https://jessesw.com/XG-Boost/ http://blog.csdn.net/u010414589/article/details/51153310
- xgboost调参
The overall parameters have been divided into 3 categories by XGBoost authors: General Parameters: G ...
- xgboost调参过程
from http://blog.csdn.net/han_xiaoyang/article/details/52665396
- xgboost使用调参
欢迎关注博主主页,学习python视频资源 https://blog.csdn.net/q383700092/article/details/53763328 调参后结果非常理想 from sklea ...
- XGBoost和LightGBM的参数以及调参
一.XGBoost参数解释 XGBoost的参数一共分为三类: 通用参数:宏观函数控制. Booster参数:控制每一步的booster(tree/regression).booster参数一般可以调 ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录10.27 - TF-IDF模型调参 / 数据可视化
TF-IDF模型调参 1. 调TfidfVectorizer的参数 ngram_range, min_df, max_df: 上一篇博客调了ngram_range这个参数,得出了ngram_range ...
随机推荐
- 一、在windows环境下修改pip镜像源的方法(以python3为例)
在windows环境下修改pip镜像源的方法(以python3为例) 1.在windows文件管理器中,输入 %APPDATA% 2.会定位到一个新的目录下,在该目录下新建pip文件夹,然后到pip文 ...
- Tomcat8配置用户名密码
配置内容: 1.vim tomcat-user.xml 添加以下内容 <role rolename="manager-gui"/> <role rolenam ...
- Flask web开发之路十三
g对象 ### 保存全局变量的g属性:g:global1. g对象是专门用来保存用户的数据的.2. g对象在一次请求中的所有的代码的地方,都是可以使用的. 项目结构: g_demo.py文件代码: f ...
- day9 九、函数
一.函数 1.函数:可以完成特定功能的代码块,函数就是存放代码块的容器 2.定义函数的语法: 函数四部分:(函数执行的本质:执行函数体,得到函数返回值) ①函数名 ②函数体 ③返回值 ④参数 用def ...
- vue项目打包后一片空白及资源引入的路径报错解决办法
网上很多说自己的VUE项目通过Webpack打包生成的list文件,放到HBulider打包后,通过手机打开一片空白.这个主要原因是路径的问题. 1.记得改一下config下面的index.js中bu ...
- qs.parse()、qs.stringify()使用方法
qs是一个npm仓库所管理的包,可通过npm install qs命令进行安装. 1. qs.parse()将URL解析成对象的形式 const Qs = require('qs'); let url ...
- C和C指针小记(五)-指针类型
1.指针常量(pointer constant) 一般是没有这个概念的,指针类型的常量理解起来可以看着指针类型的常量,常用 0xff123456 表示,我们一般不会这么做.因为程序员一般无法事先知道计 ...
- 优化网站设计(七):避免在CSS中使用表达式
前言 网站设计的优化是一个很大的话题,有一些通用的原则,也有针对不同开发平台的一些建议.这方面的研究一直没有停止过,我在不同的场合也分享过这样的话题. 作为通用的原则,雅虎的工程师团队曾经给出过35个 ...
- winform excel导入--自带office.interop.excel方式
用npoi方式,遇到一个问题,有的excel用加密软件(盖章,只读等)生成的解析不了,所以换成自带的方式,可以解决. 需要引用系统自带Microsoft.office.interop.excel pu ...
- Multiple SSH keys for different accounts on Github or Gitlab
[inside this square brackets give a name to the followed acc.] name = github_username email = github ...