python爬取并批量下载图片
import requests
from lxml import etree
url='http://desk.zol.com.cn/meinv/'
add1='.html'
urls=[]
i = 0
for i in range(1,100):
urls.append(url+str(i)+add1)
for url in urls:
print("正在爬取"+url)
html=requests.get(url)
html.encoding='gb2312'#从网页源代码可知网页的编码形式为gb2312,因此设置解码方式为gb2312
txt=html.text#获取文本文件
txtx=etree.HTML(txt)
liss=txtx.xpath('/html/body/div/div/ul/li/a/img/@src')
for lis in liss:
con=requests.get(lis)
hhh=con.content#获取二进制文件
name='D:/picture/'+str(i)+'.jpg'
with open(name,'wb') as fp:
fp.write(hhh)
i=i+1
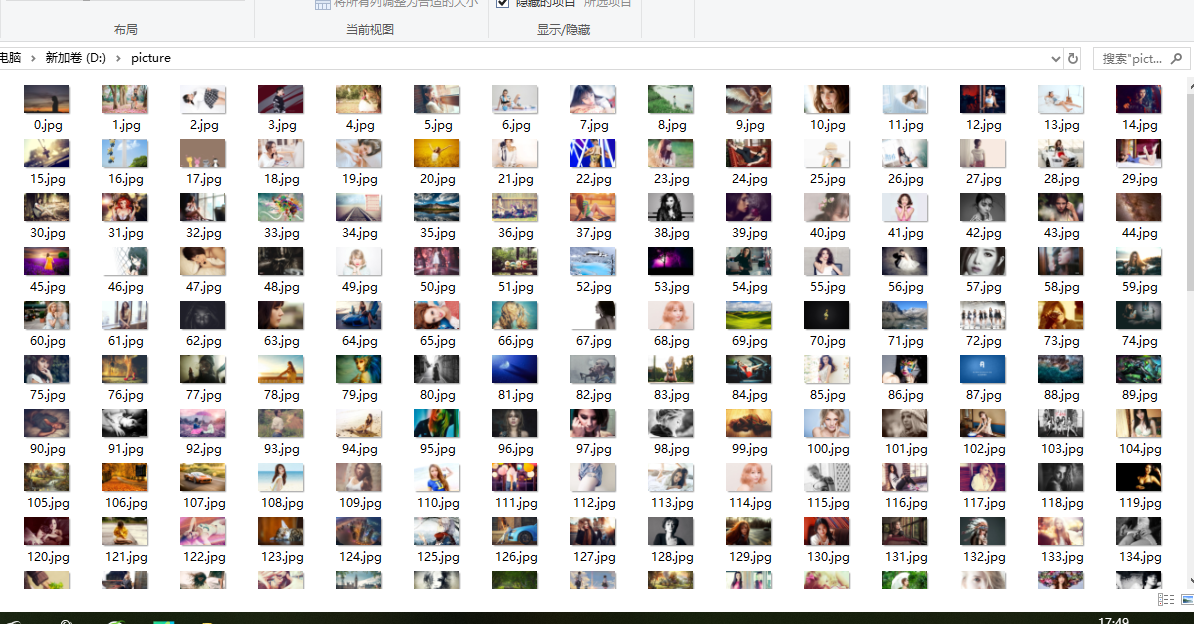
结果:
python爬取并批量下载图片的更多相关文章
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python爬取 | 唯美女生图片
这里只是代码展示,且复制后不能直接运行,需要配置一些设置才行,具体请查看下方链接介绍: Python爬取 | 唯美女生图片 from selenium import webdriver from fa ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- Python 爬取陈都灵百度图片
Python 爬取陈都灵百度图片 标签(空格分隔): 随笔 今天意外发现了自己以前写的一篇爬虫脚本,爬取的是我的女神陈都灵,尝试运行了一下发现居然还能用.故把脚本贴出来分享一下. import req ...
- python爬取网页文本、图片
从网页爬取文本信息: eg:从http://computer.swu.edu.cn/s/computer/kxyj2xsky/中爬取讲座信息(讲座时间和讲座名称) 注:如果要爬取的内容是多页的话,网址 ...
- Python爬取mn52网站美女图片以及图片防盗链的解决方法
防盗链原理 http标准协议中有专门的字段记录referer 一来可以追溯上一个入站地址是什么 二来对于资源文件,可以跟踪到包含显示他的网页地址是什么 因此所有防盗链方法都是基于这个Referer字段 ...
- python: 爬取[博海拾贝]图片脚本
练手代码,聊作备忘: # encoding: utf-8 # from __future__ import unicode_literals import urllib import urllib2 ...
- python爬取煎蛋网图片
``` py2版本: #-*- coding:utf-8 -*-#from __future__ import unicode_literimport urllib,urllib2,timeimpor ...
- Python: 爬取百度贴吧图片
练习之代码片段,以做备忘: # encoding=utf8 from __future__ import unicode_literals import urllib, urllib2 import ...
随机推荐
- nginx+awstats安装过程
awstats来来回回也装了好多遍了,每次都是现装现查,隐约的记得整个配置比较麻烦,中间有几个需要特别注意的地方,又记不得那些需要特殊对待,只能边找资料边回忆,最终还是搞出来了,在此分享给大家. 首先 ...
- addEventListener 第三个参数
addEventListener api target.addEventListener(type, listener[, options]); target.addEventListener(typ ...
- 解决 Firefox 下载文件名乱码扩展 ReDisposition
作者 muzuiget 发布 2013-03-13 19:23 标签 redisposition Firefox 下载文件名乱码问题由来已久,偶然一两次还可以手动改名,批量下载时简直要亲命,最终我 ...
- Mocks Aren't Stubs
Mocks Aren't Stubs The term 'Mock Objects' has become a popular one to describe special case objects ...
- 第三方文本框 在div中显示预览,让指定节点不受外部css影响
例如,富文本框中 ol li 但是我们往往全局样式时候会 让前面的数字不显示,但是富文本框时候,录入,我们需要显示,但是div中就不显示了 我们在预览页面中加上一个指定样式 然后后面 加上!im ...
- MapReduce实现矩阵乘法
简单回想一下矩阵乘法: 矩阵乘法要求左矩阵的列数与右矩阵的行数相等.m×n的矩阵A,与n×p的矩阵B相乘,结果为m×p的矩阵C.具体内容能够查看:矩阵乘法. 为了方便描写叙述,先进行如果: 矩阵A的行 ...
- html5 required属性的注意事项
实例 带有必填字段的表单: <form action="demo_form.asp" method="get"> Name: <input t ...
- Elasticsearch cat api的用法
文章转自:https://blog.csdn.net/wangpei1949/article/details/82287444
- Mongodb嵌套文档的改动-利用数组改动器更新数据
初学mongodb的可能和我一样有个疑问.mongodb是文档型的,那么假设一个文档嵌套另外一个文档,假设对这个嵌套文档进行增删改查呢. 就像例如以下这样:.怎样对auther里面的name进行增删改 ...
- IOS开发系列之阿堂教程:玩转IPhone客户端和Web服务端交互(客户端)实践
说到ios的应用开发,我们不能不提到web server服务端,如果没有服务端的支持,ios应用开发就没有多大意义了,因为从事过手机开发的朋友都知道(Android也一样),大量复杂业务的处理和数据库 ...