ElasticSearch 笔记
ES集群脑裂出现的原因:
1:网络原因
内网一般不会出现此问题,可以监控内网流量状态。外网的网络出现问题的可能性大些。
2:节点负载
主节点即负责管理集群又要存储数据,当访问量大时可能会导致es实例反应不过来而停止响应,此时其他节点在向主节点发送消息时得不到主节点的响应就会认为主节点挂了,从而重新选择主节点。
3:回收内存
大规模回收内存时也会导致es集群失去响应。
两节点集群脑裂的预防:
在一个两节点集群,你可以添加一个新节点并把 node.data 参数设置为“false”。这样这个节点不会保存任何分片,但它仍然可以被选为主(默认行为)。因为这个节点是一个无数据节点,所以它可以放在一台便宜服务器上。现在你就有了一个三节点的集群,可以安全的把minimum_master_nodes设置为2,避免脑裂而且仍然可以丢失一个节点并且不会丢失数据。
结论
脑裂问题很难被彻底解决。在elasticsearch的问题列表里仍然有关于这个的问题, 描述了在一个极端情况下正确设置了minimum_master_nodes的参数时仍然产生了脑裂问题。 elasticsearch项目组正在致力于开发一个选主算法的更好的实现,但如果你已经在运行elasticsearch集群了那么你需要知道这个潜在的问题。
对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
部落节点:部落节点可以跨越多个集群,它可以接收每个集群的状态,然后合并成一个全局集群的状态,它可以读写所有节点上的数据。
Elasticseach查询分为两种,结构化查询和全文查询;
solr使用zk作为分布式管理器, elasticsearch自己维护分布式管理(脑裂问题)
Z 阶曲线通过交织点的坐标值的二进制表示来简单地计算多维度中的点的z值。一旦将数据被加到该排序中,任何一维数据结构,例如二叉搜索树,B树,跳跃表或(具有低有效位被截断)哈希表 都可以用来处理数据。通过 Z 阶曲线所得到的顺序可以等同地被描述为从四叉树的深度优先遍历得到的顺序。
这也是 Geohash 的另外一个优点,搜索查找邻近点比较快。
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
Kafka是可靠的分布式日志存储服务。用简单的话来说,你可以把Kafka当作可顺序写入的一大卷磁带, 可以随时倒带,快进到某个时间点重放
ELK一般部署:
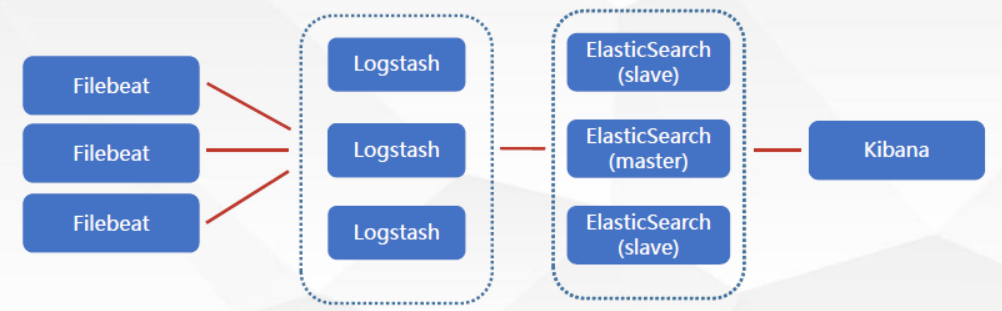
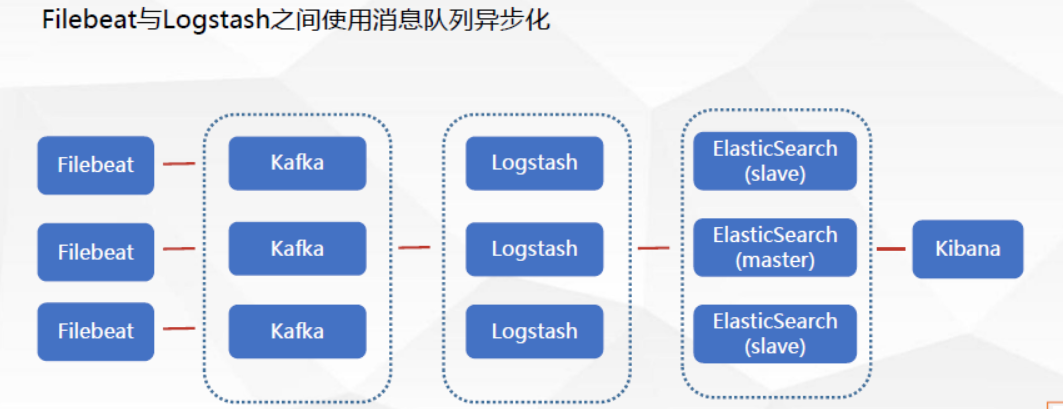
ELK海量日志部署:
Filebeat支持异步话, 增加消息队列机制Kafka
ElasticSearch 笔记的更多相关文章
- Elasticsearch笔记九之优化
Elasticsearch笔记九之优化 ).get(); } curl命令可以在linux中建立一个定时任务每天执行一次,同样java代码也可以建立一个定时器来执行. 2:内存设置之前介绍过es集群有 ...
- Elasticsearch笔记八之脑裂
Elasticsearch笔记八之脑裂 概述: 一个正常es集群中只有一个主节点,主节点负责管理整个集群,集群的所有节点都会选择同一个节点作为主节点所以无论访问那个节点都可以查看集群的状态信息. 而脑 ...
- Elasticsearch笔记七之setting,mapping,分片查询方式
Elasticsearch笔记七之setting,mapping,分片查询方式 setting 通过setting可以更改es配置可以用来修改副本数和分片数. 1:查看,通过curl或浏览器可以看到副 ...
- Elasticsearch笔记二之Curl工具基本操作
Elasticsearch笔记二之Curl工具基本操作 简介: Curl工具是一种可以在命令行访问url的工具,支持get和post请求方式.-X指定http请求的方法,-d指定要传输的数据. 创建索 ...
- 白日梦的Elasticsearch笔记(一)基础篇
目录 一.导读 1.1.认识ES 1.2.安装.启动ES.Kibana.IK分词器 二.核心概念 2.1.Near Realtime (NRT) 2.2.Cluster 2.3.Node 2.4.In ...
- Elasticsearch笔记
资料 官网: http://www.elasticsearch.org 中文资料:http://www.learnes.net/ .Net驱动: http://nest.azurewebsites.n ...
- Elasticsearch笔记六之中文分词器及自定义分词器
中文分词器 在lunix下执行下列命令,可以看到本来应该按照中文"北京大学"来查询结果es将其分拆为"北","京","大" ...
- Elasticsearch笔记四之配置参数与核心概念
在es根目录下有一个config目录,在此目录下有两个文件分别是elasticsearch.yml和logging.yml. logging.yml是日志文件,es也是使用log4j来记录日志的,我在 ...
- Elasticsearch笔记三之版本控制和插件
版本控制 1:关系型数据库使用的是悲观锁,数据被读取后就被锁定其他的线程就无法对其进行修改. 2:ex使用的是乐观锁,数据被读取后其他程序还可以对其进行修改,而执行修改时发现此数据已经被修改则修改就会 ...
- Elasticsearch笔记五之java操作es
Java操作es集群步骤1:配置集群对象信息:2:创建客户端:3:查看集群信息 1:集群名称 默认集群名为elasticsearch,如果集群名称和指定的不一致则在使用节点资源时会报错. 2:嗅探功能 ...
随机推荐
- 20165305 苏振龙《Java程序设计》第九周学习总结
第十三章 Java网络编程 学习了解用于网络编程的类,了解URL.Socket.InetAddress和DatagramSocket类在网络编程中的重要作用 使用URL创建对象的应用程序称作客户端程序 ...
- 20165215 2017-2018-2 《Java程序设计》第3周学习总结
20165215 2017-2018-2 <Java程序设计>第3周学习总结 教材学习内容总结 编程语言历经面向机器语言.面向过程语言.面向对象语言三个发展阶段. 面向对象语言的三个特点: ...
- tcpdump 命令
tcpdump命令高级网络 tcpdump命令是一款sniffer工具,它可以打印所有经过网络接口的数据包的头信息,也可以使用-w选项将数据包保存到文件中,方便以后分析. 选项 -a:尝试将网络和广播 ...
- [转载] Oracle之内存结构(SGA、PGA)
2011-05-10 14:57:53 分类: Linux 一.内存结构 SGA(System Global Area):由所有服务进程和后台进程共享: PGA(Program Global Area ...
- 前端框架VUE----模板字符串
传统的JavaScript语言,输出模板通常是这样的写的. 1 $('#result').append( 2 'There are <b>' + basket.count + '</ ...
- 利用vue写filter时 当传入是一个对象时注意
vue或angular 写filter时,传入的是对象时一定注意,不能直接改变对象的值,因为在使用该filter的页面上,若传入的对象其他值发生变化,该filter也会重新运行,这样可能会报错,如下例 ...
- redis的常用命令01
启动redis的命令: redis-server redis.windows.conf把redis设置成windows下的服务的命令:输入命令后刷新会出现redis的服务:redis-server - ...
- jquery photoClip支持手机端,PC端 本地裁剪图片后上传插件
支持手机,PC最好的是jquery photoClip插件,下载地址&示例:https://github.com/topoadmin/photoClip demo.html 代码: <! ...
- 使用v-bind处理class与style
普通的css引入: 变量引入: 通过定义一个变量fontColor来通过v-bind来进行绑定在h3z的class中 <!--变量引入--> <h3 :class="fon ...
- Iris Classification on PyTorch
Iris Classification on PyTorch code # -*- coding:utf8 -*- from sklearn.datasets import load_iris fro ...