查找->动态查找表->键树(无代码)
文字描述
键树定义
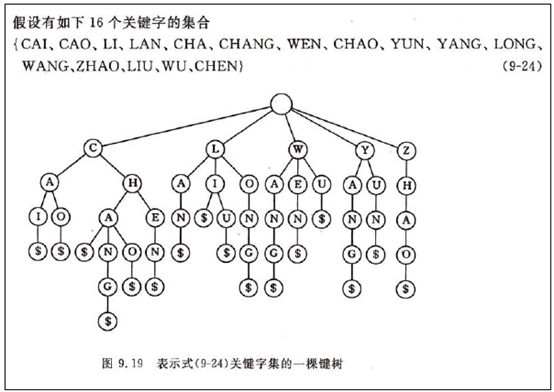
键树又叫数字查找树,它是一棵度大于或等于2的树,树中的每个结点中不是包含一个或几个关键字,而是只含有组成关键字的符号。例如,若关键字是数值,则结点中只包含一个数位;若关键字是单词,则结点中只包含一个字母字符。从根到叶子结点的字符组成的字符串表示一个关键字,叶子结点中的特殊符号$表示字符串的结束。在叶子结点中还含有指向该关键字记录的指针。
为了查找和插入方便,可以约定键树是有序树,即同一层中兄弟结点之间依所含符号自左至右有序,并约定$小于任何字符。
键树存储结构
(1)双链树
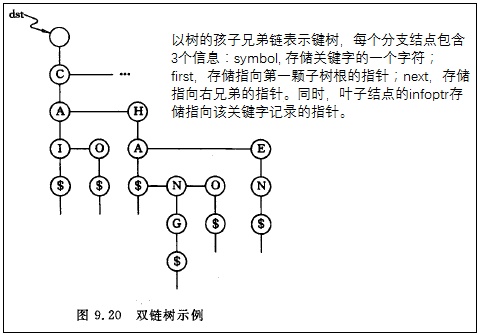
以树的孩子兄弟链表示键树,每个分支结点包含3个信息:symbol, 存储关键字的一个字符;first,存储指向第一颗子树根的指针;next,存储指向右兄弟的指针。同时,叶子结点的infoptr存储指向该关键字记录的指针。此时的键树又称为双链树。
双链树的查找:假设给定值K.ch(0,…,num-1),其中K.ch[0]至K.ch[num-2]表示待查关键字中num-1个字符,K.ch[num-1]为结束符$,从双链树的根指针出发,顺着根指针的first指针找到第一个子树的根结点,以K.ch[0]和此结点的symbol值比较,若相等,则顺first再比较下一个字符;若不相等,沿next顺序查找。若直至”空”仍比较不等,则查找不成功。
双链树的查找分析: 键树中每个结点的最大度d和关键字的“基”有关,若关键字是单词,则d=27;若关键字是数值,则d=11。键树的深度h则取决于关键字中字符或数位的个数。假设关键字为随机的(即关键字中每一位取基内任何值的概率相同),则在双链树中查找每一位的平均查找长度为(1+d)/2。又假设关键字中字符(或数位)的个数都相等,则在双链树中进行查找的平均查找长度为[h*(1+d)]/2
双链树的插入或删除: 双链树的插入或删除一个关键字,相当于在树中某个结点上插入或删除一颗子树。
(2)Trie树(trie这个词是从retrieve[检索]中取中间四个字符而来的)
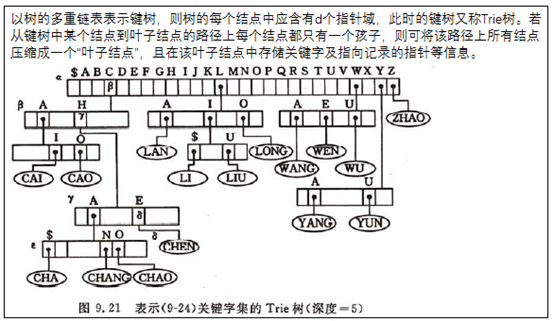
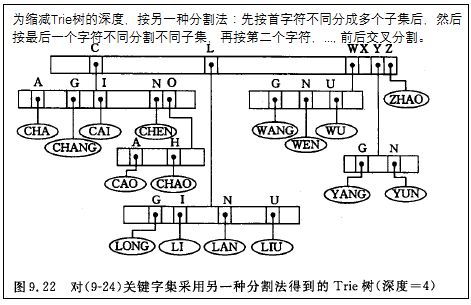
以树的多重链表表示键树,则树的每个结点中应含有d个指针域,此时的键树又称Trie树。若从键树中某个结点到叶子结点的路径上每个结点都只有一个孩子,则可将该路径上所有结点压缩成一个“叶子结点”,且在该叶子结点中存储关键字及指向记录的指针等信息。由此,在Trie树中只有两种结点:分支结点(含有d个指针域和一个指示该结点中非空指针域的个数的整数域)和叶子结点(含有关键字域和指向记录的指针域)。在分支结点中不设数据域,每个分支结点所表示的字符均由其双亲结点中(指向该结点)的指针所在位置决定。
Trie树的查找: 从根结点出发,沿和给定值相应的指针逐层向下,直到叶子结点,若叶子结点中的关键字和给定值相等,则查找成功,若分支结点中和给定值相应的指针为空,或叶子结点中的关键字和给定值不相等,则查找不成功。
Trie树的查找分析:从上述查找过程可知,在查找时走了一条从根到叶子结点的路径。由此,查找的时间依赖于树的深度。
示意图
算法分析
略
代码实现
略
查找->动态查找表->键树(无代码)的更多相关文章
- 查找->动态查找表->B+树(无代码)
文字描述 B+树定义 B+树是应文件系统所需而出的一种B-树的变型树.一棵m阶的B+树和m阶的B-树的差异在于: (1)有n棵子树的结点中含有n个关键字 (2)所有的叶子结点中包含了全部关键字的信息, ...
- 查找->动态查找表->二叉排序树
文字描述 二叉排序树的定义 又称二叉查找树,英文名为Binary Sort Tree, 简称BST.它是这样一棵树:或者是一棵空树:或者是具有下列性质的二叉树:(1)若它的左子树不空,则左子树上所有结 ...
- 查找->动态查找表->哈希表
文字描述 哈希表定义 在前面讨论的各种查找算法中,都是建立在“比较”的基础上.记录的关键字和记录在结构中的相对位置不存在确定的关系,查找的效率依赖于查找过程中所进行的比较次数.而理想的情况是希望不经过 ...
- 查找->动态查找表->平衡二叉树
文字描述 平衡二叉树(Balanced Binary Tree或Height-Balanced Tree) 因为是俄罗斯数学家G.M.Adel’son-Vel’skii和E.M.Landis在1962 ...
- C语言数据结构基础学习笔记——动态查找表
动态查找表包括二叉排序树和二叉平衡树. 二叉排序树:也叫二叉搜索树,它或是一颗空树,或是具有以下性质的二叉树: ①若左子树不空,则左子树上所有结点的值均小于它的根结点的值: ②若右子树不空,则右子树上 ...
- 查找->静态查找表->次优查找(静态树表)
文字描算 之前分析顺序查找和折半查找的算法性能都是在“等概率”的前提下进行的,但是如果有序表中各记录的查找概率不等呢?换句话说,概率不等的情况下,描述查找过程的判定树为何类二叉树,其查找性能最佳? 如 ...
- 查找(顺序表&有序表)
[1]查找概论 查找表是由同一类型是数据元素(或记录)构成的集合. 关键字是数据元素中某个数据项的值,又称为键值. 若此关键字可以唯一标识一个记录,则称此关键字为主关键字. 查找就是根据给定的某个值, ...
- 查找->静态查找表->折半查找(有序表)
文字描述 以有序表表示静态查找表时,可用折半查找算法查找指定元素. 折半查找过程是以处于区间中间位置记录的关键字和给定值比较,若相等,则查找成功,若不等,则缩小范围,直至新的区间中间位置记录的关键字等 ...
- 查找->静态查找表->分块查找(索引顺序表)
文字描述 分块查找又称为索引顺序查找,是顺序查找的一种改进方法.在此查找算法中,除表本身外, 还需要建立一个”索引表”.索引表中包括两项内容:关键字项(其值为该字表内的最大关键字)和指针项(指示该子表 ...
随机推荐
- [转]Ubuntu 16.04安装有道词典
原文:https://www.cnblogs.com/scplee/archive/2016/05/13/5489024.html 以前用Ubuntu 14.04 的时候,直接下载有道词典官方deb安 ...
- 解决Redis之MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist o...
解决Redis之MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist o... ...
- Java多线程系列——线程池原理之 ThreadPoolExecutor
ThreadPoolExecutor 简介 ThreadPoolExecutor 是线程池类. 通俗的讲,它是一个存放一定数量线程的线程集合.线程池允许多个线程同时运行,同时运行的线程数量就是这个线程 ...
- 奋斗STM32V3版ADC例程
https://wenku.baidu.com/view/a60b2042c850ad02de8041b7.html
- too many open files
压测遇到这个问题,每次都查,记录一下: 系统分配文件数太少,临时修改方案: ulimit -n 2048 永久配置: vim /etc/security/limits.conf 底部配置: # End ...
- ffmpeg 移植到 android 并使用
同步更新至个人blog:http://dxjia.cn/2015/07/ffmpeg-porting-to-android/ 空闲做了个小应用,从视频里截图,然后再将截图拼接为一个gif动画: 起初使 ...
- Android控件源码分析--AndroidResideMenu菜单
说明 早上看到一篇文章介绍了ResideMenu得使用,这是一个类似SlidingMenu的控件,感觉有点高尚大,反正我之前没见过,本着凑热闹的好奇心,立马clone把玩下,项目地址奉上: https ...
- [Laravel] 14 - REST API: Laravel from scratch
前言 一.基础 Ref: Build a REST API with Laravel API resources Goto: [Node.js] 08 - Web Server and REST AP ...
- 4、一、Introduction(入门):3、System Permissions(系统权限)
3.System Permissions(系统权限) Android is a privilege-separated operating system, in which each applic ...
- 大杂烩 -- equals、hashCode联系与区别
基础大杂烩 -- 目录 -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- Equals 1.默认情况(没有覆盖equals方 ...