python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息
(1)分析网页源码
打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果
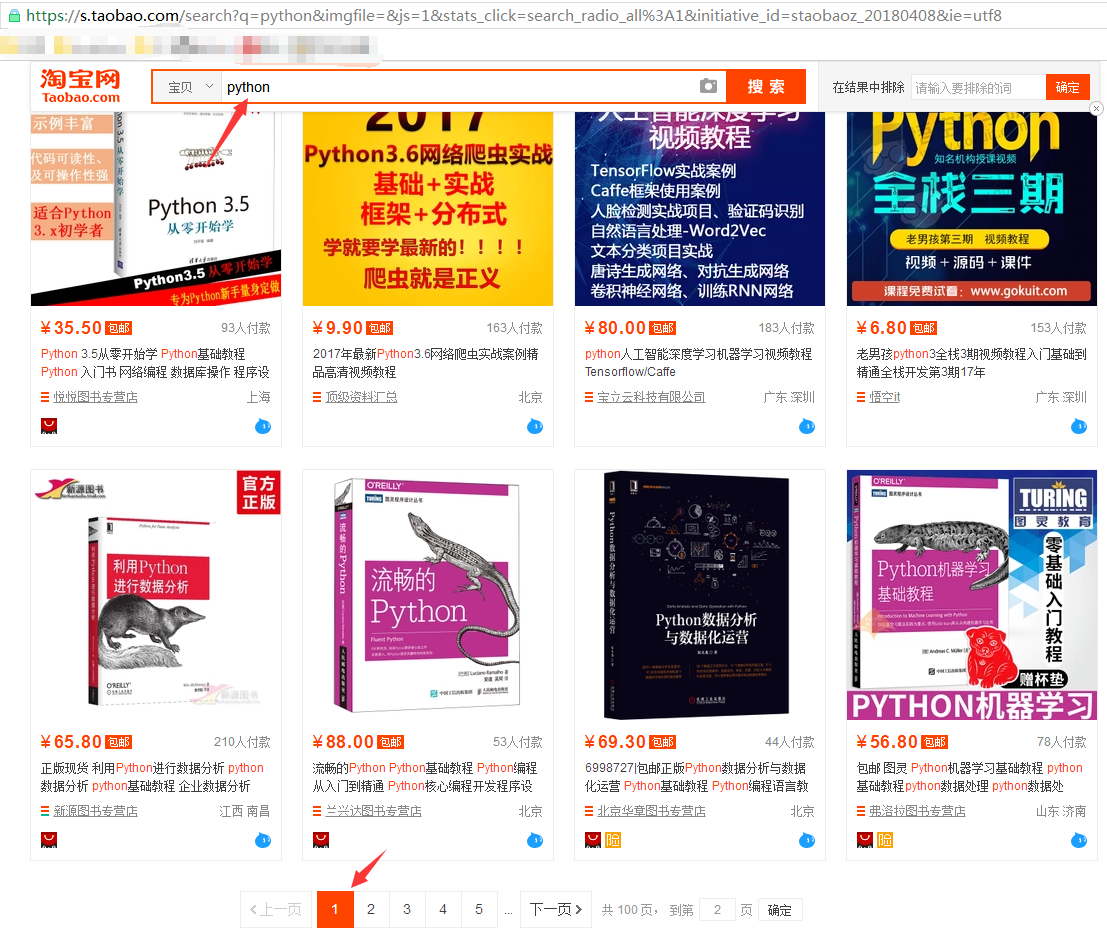
从url连接中可以得到搜索商品的关键字是“q=”,所以我们要用的起始url为:https://s.taobao.com/search?q=python
然后翻页,先跳到第二页,url变为:

再跳到第三页,url变为:

经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44)
所以可以根据关键字“s=”,来设置爬取的深度(爬取多少页)
右键查看源码:

分析商品名称和商品价格分别由哪个关键字控制:
商品名称可能的关键字是“title”和“raw_title”,进一步多看几个商品的名称,发现选取“raw_title”比较合适;商品价格自然就是“view_price”(通过比对淘宝商品展示页面);
所以商品名称和商品价格分别是以 "raw_title":"名称" 和 "view_price":"价格",这样的键/值对的形式展示的。
(2)分析如何实现
与上一个例子爬取“最好大学排名”不同,淘宝商品信息不像之前的大学信息是以HTML格式嵌入的,这里的商品信息并未以HTML标签的形式处理数据,而是直接以脚本语言放进来的,所以不需要用BeautifulSoup来解析,直接用正则表达式提取 关键字信息即可
(3)提取信息
写个demo,看看是如何一步步解析信息的
# coding:utf-8 import requests
import re goods = '水杯'
url = 'https://s.taobao.com/search?q=' + goods r = requests.get(url=url, timeout=10)
html = r.text tlist = re.findall(r'\"raw_title\"\:\".*?\"', html) # 正则提取商品名称
plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) # 正则提示商品价格 print(tlist)
print(plist)
print(type(plist)) # 正则表达式提取出的商品名称和商品价格都是以列表形式存储数据的

去掉列表中的键,只留下值,也就是去掉每组数据的“raw_title”和“view_price”
print('第一个商品的键值对信息:', tlist[0]) # 查看第一个商品的键值对信息
a = tlist[0].split(':')[1] # 使用split()方法以":"为切割点,将商品的键值分开,提取值,即商品名称
print('第一个商品的名称', a)
print(type(a)) # 查看a的类型
b = eval(a) # 使用eval()函数,去掉字符串的引号
print('把商品名称去掉引号后', b) # 查看去掉引号后的效果
print(type(b)) # 查看b的类型

利用for循环,把每个商品的名称和价格组成一个列表,然后把这写列表再追加到一个大列表中:
goodlist = []
for i in range(len(tlist)):
title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号
price = eval(plist[i].split(':')[1])
goodlist.append([title, price]) # 把每个商品的名称和价格组成一个小列表,然后把所有商品组成的列表追加到一个大列表中
print(goodlist)

完整代码:
# coding: utf-8 import requests
import re # def getHTMLText(url):
# try:
# r = requests.get(url, timeout=30)
# r.raise_for_status()
# r.encoding = r.apparent_encoding
# return r.text
# except:
# return ""
#
#
# def parsePage(ilt, html):
# try:
# plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
# tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
# for i in range(len(plt)):
# price = eval(plt[i].split(':')[1])
# title = eval(tlt[i].split(':')[1])
# ilt.append([price, title])
# except:
# print()
#
#
# def printGoodsList(ilt):
# tplt = "{:4}\t{:8}\t{:16}"
# print(tplt.format("序号", "价格", "商品名称"))
# count = 0
# for t in ilt:
# count = count + 1
# print(tplt.format(count, t[0], t[1]))
#
#
# def main():
# goods = '高达'
# depth = 3
# start_url = 'https://s.taobao.com/search?q=' + goods
# infoList = []
# for i in range(depth):
# try:
# url = start_url + '&s=' + str(44 * i)
# html = getHTMLText(url)
# parsePage(infoList, html)
# except:
# continue
# printGoodsList(infoList)
#
#
# main() def get_html(url):
"""获取源码html"""
try:
r = requests.get(url=url, timeout=10)
r.encoding = r.apparent_encoding
return r.text
except:
print("获取失败") def get_data(html, goodlist):
"""使用re库解析商品名称和价格
tlist:商品名称列表
plist:商品价格列表"""
tlist = re.findall(r'\"raw_title\"\:\".*?\"', html)
plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
for i in range(len(tlist)):
title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号
price = eval(plist[i].split(':')[1])
goodlist.append([title, price]) def write_data(list, num):
# with open('E:/Crawler/case/taob2.txt', 'a') as data:
# print(list, file=data)
for i in range(num): # num控制把爬取到的商品写进多少到文本中
u = list[i]
with open('E:/Crawler/case/taob.txt', 'a') as data:
print(u, file=data) def main():
goods = '水杯'
depth = 3 # 定义爬取深度,即翻页处理
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i) # 因为淘宝显示每页44个商品,第一页i=0,一次递增
html = get_html(url)
get_data(html, infoList)
except:
continue
write_data(infoList, len(infoList)) if __name__ == '__main__':
main()

python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件的更多相关文章
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- python爬虫实例,一小时上手爬取淘宝评论(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- Python 爬虫实例(9)—— 搜索 爬取 淘宝
# coding:utf- import json import redis import time import requests session = requests.session() impo ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
随机推荐
- 使用Excel批量给数据添加单引号和逗号
表格制作过程如下: A2表格暂时为空,模板建立完成以后,用来放置原始数据: 在B2表格内输入公式: ="'"&A2&"'"&" ...
- oracle12c的日志查看
查看GI日志:切换到grid用户 查看DB日志:切换到oracle的目录下 执行[oracle@swnode1 ~]$ adrci [oracle@swnode1 ~]$ adrci ADRCI: R ...
- bzoj 2115 Xor - 线性基 - 贪心
题目传送门 这是个通往vjudge的虫洞 这是个通往bzoj的虫洞 题目大意 问点$1$到点$n$的最大异或路径. 因为重复走一条边后,它的贡献会被消去.所以这条路径中有贡献的边可以看成是一条$1$到 ...
- web site optimization
@ 如果有很多图片(比如web服务器的页面上有多个小图片),通常是没有必要记录文件的访问时间的,这样就可以减少写磁盘的I/O,这个要如何配置 @ 首先,修改文件系统的配置文件/etc/fstab ,然 ...
- IDEA安装与破解
今天下午偶然在知乎上看到IDEA和eclipse的软件分析,所以装了一个IDEA,不过肯定是破解,不会购买激活码 IDEA官网:http://www.jetbrains.com/idea/ 安装教程: ...
- 【python35.1--EasyGui界面】
一.什么是EasyGUI EasyGUI是python中一个非常简单的GUI编程模块,不同于其他的GUI生成器,它不是事件驱动的,相反,所有的GUI交互都是通过简地函数调用就可以实现(意思是:函数调用 ...
- Redis 安装,配置以及数据操作
Nosql介绍 Nosql:一类新出现的数据库(not only sql)的特点 不支持SQL语法 存储结构跟传统关系型数据库中那种关系表完全不同,nosql中存储的数据都是k-v形式 Nosql的世 ...
- bzoj 1735: [Usaco2005 jan]Muddy Fields 泥泞的牧场 最小点覆盖
链接 1735: [Usaco2005 jan]Muddy Fields 泥泞的牧场 思路 这就是个上一篇的稍微麻烦版(是变脸版,其实没麻烦) 用边长为1的模板覆盖地图上的没有长草的土地,不能覆盖草地 ...
- 【做题】TCSRM601 Div1 500 WinterAndSnowmen——按位考虑&dp
原文链接https://www.cnblogs.com/cly-none/p/9695526.html 题意:求有多少对集合\(S,T\)满足:\(S \subseteq \{1,2...n \}, ...
- oracle 之 创,增,删,改操作
--创建表 (包含其中的数据) create table TableName as select * from TableName --插入数据 insert into TableName(列,列.. ...