【自然语言处理】利用LDA对希拉里邮件进行主题分析
首先是读取数据集,并将csv中ExtractedBodyText为空的给去除掉
import pandas as pd
import re
import os dir_path=os.path.dirname(os.path.abspath(__file__))
data_path=dir_path+"/Database/HillaryEmails.csv"
df=pd.read_csv(data_path)
df=df[['Id','ExtractedBodyText']].dropna()
对于这些邮件信息,并不是所有的词都是有意义的,也就是先要去除掉一些噪声数据:
def clean_email_text(text):
text = text.replace('\n'," ") #新行,我们是不需要的
text = re.sub(r"-", " ", text) #把 "-" 的两个单词,分开。(比如:july-edu ==> july edu)
text = re.sub(r"\d+/\d+/\d+", "", text) #日期,对主体模型没什么意义
text = re.sub(r"[0-2]?[0-9]:[0-6][0-9]", "", text) #时间,没意义
text = re.sub(r"[\w]+@[\.\w]+", "", text) #邮件地址,没意义
text = re.sub(r"/[a-zA-Z]*[:\//\]*[A-Za-z0-9\-_]+\.+[A-Za-z0-9\.\/%&=\?\-_]+/i", "", text) #网址,没意义
pure_text = ''
# 以防还有其他特殊字符(数字)等等,我们直接把他们loop一遍,过滤掉
for letter in text:
# 只留下字母和空格
if letter.isalpha() or letter==' ':
pure_text += letter
# 再把那些去除特殊字符后落单的单词,直接排除。
# 我们就只剩下有意义的单词了。
text = ' '.join(word for word in pure_text.split() if len(word)>1)
return text
然后取出ExtractedBodyText的那一列,对每一行email进行噪声过滤,并返回一个对象:
docs = df['ExtractedBodyText']
docs = docs.apply(lambda s: clean_email_text(s))
然后我们呢把里面的email提取出来:
doclist=docs.values
接下来,我们使用gensim库来进行LDA模型的构建,gensim可用指令pip install -U gensim安装。但是,要注意输入到模型中的数据的格式。例如:将[[一条邮件字符串],[另一条邮件字符串], ...]转换成[[一,条,邮件,在,这里],[第,二,条,邮件,在,这里],[今天,天气,肿么,样],...]。对于英文的分词,只需要对空白处分割即可。同时,有些词语(不同于噪声)是没有意义的,我们要过滤掉那些没有意义的词语,这里简单的写一个停止词列表:
stoplist = ['very', 'ourselves', 'am', 'doesn', 'through', 'me', 'against', 'up', 'just', 'her', 'ours',
'couldn', 'because', 'is', 'isn', 'it', 'only', 'in', 'such', 'too', 'mustn', 'under', 'their',
'if', 'to', 'my', 'himself', 'after', 'why', 'while', 'can', 'each', 'itself', 'his', 'all', 'once',
'herself', 'more', 'our', 'they', 'hasn', 'on', 'ma', 'them', 'its', 'where', 'did', 'll', 'you',
'didn', 'nor', 'as', 'now', 'before', 'those', 'yours', 'from', 'who', 'was', 'm', 'been', 'will',
'into', 'same', 'how', 'some', 'of', 'out', 'with', 's', 'being', 't', 'mightn', 'she', 'again', 'be',
'by', 'shan', 'have', 'yourselves', 'needn', 'and', 'are', 'o', 'these', 'further', 'most', 'yourself',
'having', 'aren', 'here', 'he', 'were', 'but', 'this', 'myself', 'own', 'we', 'so', 'i', 'does', 'both',
'when', 'between', 'd', 'had', 'the', 'y', 'has', 'down', 'off', 'than', 'haven', 'whom', 'wouldn',
'should', 've', 'over', 'themselves', 'few', 'then', 'hadn', 'what', 'until', 'won', 'no', 'about',
'any', 'that', 'for', 'shouldn', 'don', 'do', 'there', 'doing', 'an', 'or', 'ain', 'hers', 'wasn',
'weren', 'above', 'a', 'at', 'your', 'theirs', 'below', 'other', 'not', 're', 'him', 'during', 'which']
然后我们将输入转换成gensim所需的格式,并过滤掉停用词:
texts = [[word for word in doc.lower().split() if word not in stoplist] for doc in doclist]
再将这所有的单词放入到一个词袋中,把每个单词用一个数字index指代:
from gensim import corpora, models, similarities
import gensim
dictionary = corpora.Dictionary(texts)

再分别统计每一篇email中每个词语在这个词袋中出现的次数,并返回一个列表:
corpus = [dictionary.doc2bow(text) for text in texts]

这个列表告诉我们,第14(从0开始是第一)个邮件中,一共6个有意义的单词(经过我们的文本预处理,并去除了停止词后)其中,51号单词出现1次,505号单词出现1次,以此类推。。。
最后,就可以开始构建我们的模型了:
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
print(lda.print_topic(10, topn=5))

可以看到,第11个主题最常用的单词,接下来,我们看下所有的主题:
for i in lda.print_topics(num_topics=20, num_words=5):
print(i)
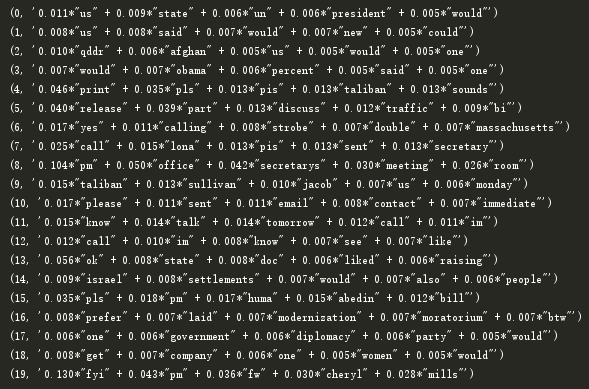
我们再看下第一篇email属于哪一个主题:
print(lda.get_document_topics(corpus[0]))

属于第四个主题的概率是0.95
相关代码和数据:链接: https://pan.baidu.com/s/1sl1I5IeQFDHjVwf2a0C89g 提取码: xqqf
【自然语言处理】利用LDA对希拉里邮件进行主题分析的更多相关文章
- centos下利用mail命令进行邮件发送
centos下默认自带mail命令: 可以用如下命令查看存放位置: which mail 结果如下: 如果没有安装可以使用 如下命令安装 yum -y install mailx 利用mail命令进行 ...
- JavaMail(二):利用JavaMail发送复杂邮件
上一篇文章我们学习了利用JavaMail发送简单邮件,这篇文章我们利用JavaMail发送稍微复杂一点的邮件(包含文本.图片.附件).这里只贴出核心代码,其余代码可参考JavaMail(一):利用Ja ...
- Android利用tcpdump抓包,用wireshark分析包。
1.前言 主要介绍在android手机上如何利用tcpdump抓包,用wireshark分析包. android tcpdump官网: http://www.androidtcpdump.com/ t ...
- 利用 Memory Dump Diagnostic for Java (MDD4J) 分析内存管理问题
利用 Memory Dump Diagnostic for Java (MDD4J) 分析内存管理问题(2) 启动和理解 MDD4J[size=1.0625]为了充分理解如何使用 MDD4J,您需要了 ...
- 前端性能优化之利用 Chrome Dev Tools 进行页面性能分析
背景 我们经常使用 Chrome Dev Tools 来开发调试,但是很少知道怎么利用它来分析页面性能,这篇文章,我将详细说明怎样利用 Chrome Dev Tools 进行页面性能分析及性能报告数据 ...
- LDA模型应用实践-希拉里邮件主题分类
#coding=utf8 import numpy as np import pandas as pd import re from gensim import corpora, models, si ...
- 自然语言处理基础与实战(8)- 主题模型LDA理解与应用
本文主要用于理解主题模型LDA(Latent Dirichlet Allocation)其背后的数学原理及其推导过程.本菇力求用简单的推理来论证LDA背后复杂的数学知识,苦于自身数学基础不够,因此文中 ...
- django实现利用mailgun进行收发邮件
django窗口类运用和邮件收发 运用django窗口类来完成表单html 1 具体你看网址: https://www.cnblogs.com/guguobao/p/9322027.html 利用窗口 ...
- 如何利用sendmail发送外部邮件?
在写监控脚本时,为了更好的监控服务器性能,如磁盘空间.系统负载等,有必要在系统出现瓶颈时,及时向管理员进行报告.在这里通常采用邮件报警,同时,邮件设置为收到邮件,即向指定手机号码发送短信.这样可以实现 ...
随机推荐
- Poco XMLconfiguration 解析xml配置文件
环境: Centos7 GCC: 7.3.0 准备需要读取的xml文件: <config> <prop1>1.23</prop1> <prop2>2.3 ...
- 代码审计-YXcms1.4.7
题外: 今天是上班第一天,全都在做准备工作,明天开始正式实战做事. 看着周围稍年长的同事和老大做事,自己的感觉就是自己还是差的很多很多,自己只能算个废物. 学无止境,我这样的垃圾废物就该多练,保持战斗 ...
- 关于参加AWD攻防比赛心得体会
今天只是简单写下心得和体会 平时工作很忙 留给学习的时间更加珍少宝贵. 重点说下第二天的攻防比赛吧 . 三波web题 .涉及jsp,php,py. 前期我们打的很猛.第一波jsp的题看到有首页预留后 ...
- OD 逆向工具常用快捷键
F2:设置断点,只要在光标定位的位置(上图中灰色条)按F2键即可,再按一次F2键则会删除断点. F8:单步步过.每按一次这个键执行一条反汇编窗口中的一条指令,遇到 CALL 等子程序不进入其代码. F ...
- Beanutils.copyProperties( )使用详情总结
Beanutils.copyProperties( ) 一.简介: BeanUtils提供对Java反射和自省API的包装.其主要目的是利用反射机制对JavaBean的属性进行处理.我们知道,一个 ...
- Pathon中numpy模块
目录 numpy模块 切割矩阵 矩阵元素替换 矩阵的合并 通过函数创建矩阵 fromstring/fromfunctions 矩阵的运算 常用矩阵运函数 矩阵的点乘 矩阵的逆 矩阵的其他操作 nump ...
- postman使用实例
以下以一个登录接口为例,介绍一下postman是如何发请求的. 先执行Pre-request Scripts(预处理) - body - tests(进行断言) postman中变量的引用: {{}}
- collectionView reloadData走了不执行cellForItemAtIndexPath
有可能是sizeForItemAtIndexPath方法中的前几个cell没有设置大小, 这里必须设置, 哪怕是设置一个很小的值
- 小白学 Python(8):基础流程控制(下)
人生苦短,我选Python 前文传送门 小白学 Python(1):开篇 小白学 Python(2):基础数据类型(上) 小白学 Python(3):基础数据类型(下) 小白学 Python(4):变 ...
- 介绍Webflux
介绍Webflux 关于WebFlux 我们知道传统的Web框架,比如说:struts2,springmvc等都是基于Servlet API与Servlet容器基础之上运行的,在Servlet3.1之 ...