Disruptor—核心概念及体验
本文基于最新的3.4.2的版本文档进行翻译,翻译自:
https://github.com/LMAX-Exchange/disruptor/wiki/Introduction
https://github.com/LMAX-Exchange/disruptor/wiki/Getting-Started
Disruptor简介
最好的方法去理解Disruptor就是将它和容易理解并且相似的队列,例如BlockingQueue。Disruptor其实就像一个队列一样,用于在不同的线程之间迁移数据,但是Disruptor也实现了一些其他队列没有的特性,如:
- 同一个“事件”可以有多个消费者,消费者之间既可以并行处理,也可以相互依赖形成处理的先后次序(形成一个依赖图);
- 预分配用于存储事件内容的内存空间;
- 针对极高的性能目标而实现的极度优化和无锁的设计;
Disruptor核心架构组件
- Ring Buffer:Ring Buffer在3.0版本以前被认为是Disruptor的核心组件,但是在之后的版本中只是负责存储和更新数据。在一些高级使用案例中用户也能进行自定义
- Sequence:Disruptor使用一组Sequence来作为一个手段来标识特定的组件的处理进度( RingBuffer/Consumer )。每个消费者和Disruptor本身都会维护一个Sequence。虽然一个 AtomicLong 也可以用于标识进度,但定义 Sequence 来负责该问题还有另一个目的,那就是防止不同的 Sequence 之间的CPU缓存伪共享(Flase Sharing)问题。
- Sequencer:Sequencer是Disruptor的真正核心。此接口有两个实现类 SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
- Sequence Barrier:保持Sequencer和Consumer依赖的其它Consumer的 Sequence 的引用。除此之外还定义了决定 Consumer 是否还有可处理的事件的逻辑。
- Wait Strategy:Wait Strategy决定了一个消费者怎么等待生产者将事件(Event)放入Disruptor中。
- Event:从生产者到消费者传递的数据叫做Event。它不是一个被 Disruptor 定义的特定类型,而是由 Disruptor 的使用者定义并指定。
- EventProcessor:持有特定的消费者的Sequence,并且拥有一个主事件循环(main event loop)用于处理Disruptor的事件。其中BatchEventProcessor是其具体实现,实现了事件循环(event loop),并且会回调到实现了EventHandler的已使用过的实例中。
- EventHandler:由用户实现的接口,用于处理事件,是 Consumer 的真正实现
- Producer:生产者,只是泛指调用 Disruptor 发布事件的用户代码,Disruptor 没有定义特定接口或类型。
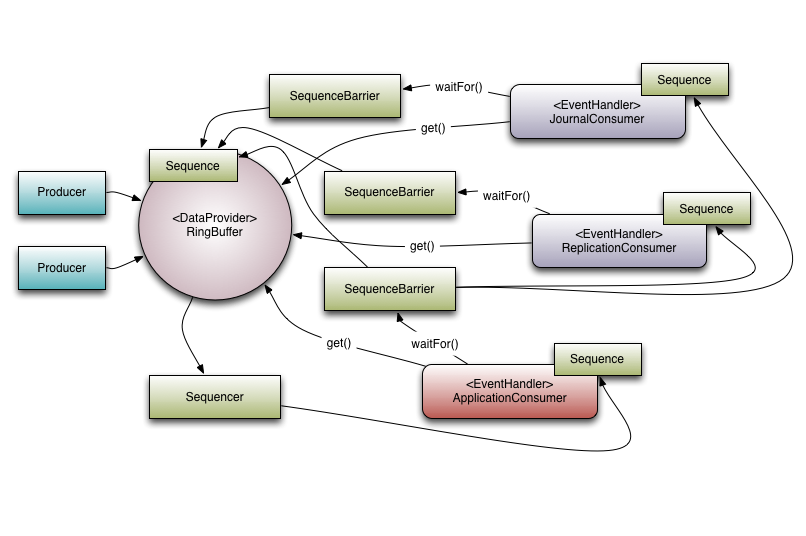
事件广播(Multicast Events)
这是Disruptor和队列最大的区别。当你有多个消费者监听了一个Disruptor,所有的事件将会被发布到所有的消费者中,相比之下队列的一个事件只能被发到一个消费者中。Disruptor这一特性被用来需要对同一数据进行多个并行操作的情况。如在LMAX系统中有三个操作可以同时进行:日志(将数据持久到日志文件中),复制(将数据发送到其他的机器上,以确保存在数据远程副本),业务逻辑处理。也可以使用WokrerPool来并行处理不同的事件。
消费者依赖关系图(Consumer Dependency Graph)
为了支持真实世界中的业务并行处理流程,Disruptor提供了多个消费者之间的协助功能。回到上面的LMAX的例子,我们可以让日志处理和远程副本赋值先执行完之后再执行业务处理流程,这个功能被称之为gating。gating发生在两种场景中。第一,我们需要确保生产者不要超过消费者。通过调用RingBuffer.addGatingConsumers()增加相关的消费者至Disruptor来完成。第二,就是之前所说的场景,通过构造包含需要必须先完成的消费者的Sequence的SequenceBarrier来实现。
引用上面的例子来说,有三个消费者监听来自RingBuffer的事件。这里有一个依赖关系图。ApplicationConsumer依赖JournalConsumer和ReplicationConsumer。这个意味着JournalConsumer和ReplicationConsumer可以自由的并发运行。依赖关系可以看成是从ApplicationConsumer的SequenceBarrier到JournalConsumer和ReplicationConsumer的Sequence的连接。还有一点值得关注,Sequencer与下游的消费者之间的关系。它的角色是确保发布不会包裹RingBuffer。为此,所有下游消费者的Sequence不能比ring buffer的Sequence小且不能比ring buffer 的大小小。因为ApplicationConsumers的Sequence是确保比JournalConsumer和ReplicationConsumer的Sequence小或等于,所以Sequencer只需要检查ApplicationConsumers的Sequence。在更为普遍的应用场景中,Sequencer只需要意识到消费者树中的叶子节点的的Sequence即可。
事件预分配(Event Preallocation)
Disruptor的一个目标之一是被用在低延迟的环境中。在一个低延迟系统中有必要去减少和降低内存的占用。在基于Java的系统中,需要减少由于GC导致的停顿次数(在低延迟的C/C++系统中,由于内存分配器的争用,大量的内存分配也会导致问题)。
为了满足这点,用户可以在Disruptor中为事件预分配内存。所以EventFactory是用户来提供,并且Disruptor的Ring Buffer每个entry中都会被调用。当将新的数据发布到Disruptor中时,Disruptor的API将会允许用户持有所构造的对象,以便用户可以调用这些对象的方法和更新字段到这些对象中。Disruptor将确保这些操作是线程安全。
可选择的无锁
无锁算法实现的Disruptor的所有内存可见性和正确性都使用内存屏障和CAS操作实现。只仅仅一个场景BlockingWaitStrategy中使用到了lock。而这仅仅是为了使用Condition,以便消费者线程能被park住当在等待一个新的事件到来的时候。许多低延迟系统都使用自旋(busy-wait)来避免使用Condition造成的抖动。但是自旋(busy-wait)的数量变多时将会导致性能的下降,特别是CPU资源严重受限的情况下。例如,在虚拟环境中的Web服务器。
Disruptor使用
我们使用一个简单的例子来体验一下Disruptor。生产者会传递一个long类型的值到消费者,消费者接受到这个值后会打印出这个值。
定义Event
public class LongEvent
{
private long value;
public void set(long value)
{
this.value = value;
}
}
为了使用Disruptor的内存预分配event,我们需要定义一个EventFactory:
import com.lmax.disruptor.EventFactory;
public class LongEventFactory implements EventFactory<LongEvent>
{
public LongEvent newInstance()
{
return new LongEvent();
}
}
为了让消费者处理这些事件,所以我们这里定义一个事件处理器,负责打印event:
import com.lmax.disruptor.EventHandler;
public class LongEventHandler implements EventHandler<LongEvent>
{
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("Event: " + event);
}
}
使用Translators发布事件
在Disruptor的3.0版本中,由于加入了丰富的Lambda风格的API,可以用来帮组开发人员简化流程。所以在3.0版本后首选使用Event Publisher/Event Translator来发布事件。
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.EventTranslatorOneArg;
public class LongEventProducerWithTranslator
{
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducerWithTranslator(RingBuffer<LongEvent> ringBuffer)
{
this.ringBuffer = ringBuffer;
}
private static final EventTranslatorOneArg<LongEvent, ByteBuffer> TRANSLATOR =
new EventTranslatorOneArg<LongEvent, ByteBuffer>()
{
public void translateTo(LongEvent event, long sequence, ByteBuffer bb)
{
event.set(bb.getLong(0));
}
};
public void onData(ByteBuffer bb)
{
ringBuffer.publishEvent(TRANSLATOR, bb);
}
}
这种方法的另一个优点是可以将translator代码放入一个单独的类中,并且可以轻松地对它们进行独立的单元测试。
使用过时的API发布事件
import com.lmax.disruptor.RingBuffer;
public class LongEventProducer
{
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer)
{
this.ringBuffer = ringBuffer;
}
public void onData(ByteBuffer bb)
{
long sequence = ringBuffer.next(); // Grab the next sequence
try
{
LongEvent event = ringBuffer.get(sequence); // Get the entry in the Disruptor
// for the sequence
event.set(bb.getLong(0)); // Fill with data
}
finally
{
ringBuffer.publish(sequence);
}
}
}
这里我们需要把发布包裹在try/finally代码块中。如果某个请求的 sequence 未被提交,将会堵塞后续的发布操作或者其它的 producer。特别地在多生产中如果没有提交Sequence,那么会造成消费者停滞,导致只能重启消费者才能恢复。
整合
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void main(String[] args) throws Exception
{
// The factory for the event
LongEventFactory factory = new LongEventFactory();
// Specify the size of the ring buffer, must be power of 2.
int bufferSize = 1024;
// Construct the Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(factory, bufferSize, DaemonThreadFactory.INSTANCE);
// Connect the handler
disruptor.handleEventsWith(new LongEventHandler());
// Start the Disruptor, starts all threads running
disruptor.start();
// Get the ring buffer from the Disruptor to be used for publishing.
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
producer.onData(bb);
Thread.sleep(1000);
}
}
}
我们也可以使用Java 8的函数式编程来写这个例子:
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void main(String[] args) throws Exception
{
// Specify the size of the ring buffer, must be power of 2.
int bufferSize = 1024;
// Construct the Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);
// Connect the handler
disruptor.handleEventsWith((event, sequence, endOfBatch) -> System.out.println("Event: " + event));
// Start the Disruptor, starts all threads running
disruptor.start();
// Get the ring buffer from the Disruptor to be used for publishing.
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);
Thread.sleep(1000);
}
}
}
使用函数式编程我们可以发现很多的类都不需要了,如:handler,translator等。
上面的代码还可以再简化一下:
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence) -> event.set(bb.getLong(0)));
Thread.sleep(1000);
}
不过这样将实例化一个对象去持有ByteBuffer bb变量传入lambda的值。这会产生不必要的垃圾。因此,如果要求低GC压力,则应首选将参数传递给lambda的调用。
提升性能的两个参数
如果想要让Disruptor拥有更好的性能这里有两个选项可以调整,wait strategy 和 producer的类型。
单生产者 vs 多生产者
最好的方法在并发环境下提高性能是坚持单独写原则( Single Writer Principle)。如果你的业务场景中只有一个线程写入数据到Disruptor,那么你可以设置成单生产者来提升性能:
public class LongEventMain
{
public static void main(String[] args) throws Exception
{
//.....
// Construct the Disruptor with a SingleProducerSequencer
Disruptor<LongEvent> disruptor = new Disruptor(
factory, bufferSize, DaemonThreadFactory.INSTANCE, ProducerType.SINGLE, new BlockingWaitStrategy());
//.....
}
}
性能测试:
Multiple Producer
Run 0, Disruptor=26,553,372 ops/sec
Run 1, Disruptor=28,727,377 ops/sec
Run 2, Disruptor=29,806,259 ops/sec
Run 3, Disruptor=29,717,682 ops/sec
Run 4, Disruptor=28,818,443 ops/sec
Run 5, Disruptor=29,103,608 ops/sec
Run 6, Disruptor=29,239,766 ops/sec
Single Producer
Run 0, Disruptor=89,365,504 ops/sec
Run 1, Disruptor=77,579,519 ops/sec
Run 2, Disruptor=78,678,206 ops/sec
Run 3, Disruptor=80,840,743 ops/sec
Run 4, Disruptor=81,037,277 ops/sec
Run 5, Disruptor=81,168,831 ops/sec
Run 6, Disruptor=81,699,346 ops/sec
等待策略
BlockingWaitStrategy
Disruptor的默认策略是BlockingWaitStrategy。在BlockingWaitStrategy内部是使用锁和condition来控制线程的唤醒。BlockingWaitStrategy是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现
SleepingWaitStrategy
SleepingWaitStrategy 的性能表现跟 BlockingWaitStrategy 差不多,对 CPU 的消耗也类似,但其对生产者线程的影响最小,通过使用LockSupport.parkNanos(1)来实现循环等待。一般来说Linux系统会暂停一个线程约60µs,这样做的好处是,生产线程不需要采取任何其他行动就可以增加适当的计数器,也不需要花费时间信号通知条件变量。但是,在生产者线程和使用者线程之间移动事件的平均延迟会更高。它在不需要低延迟并且对生产线程的影响较小的情况最好。一个常见的用例是异步日志记录。
YieldingWaitStrategy
YieldingWaitStrategy是可以使用在低延迟系统的策略之一。YieldingWaitStrategy将自旋以等待序列增加到适当的值。在循环体内,将调用Thread.yield(),以允许其他排队的线程运行。在要求极高性能且事件处理线数小于 CPU 逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。
BusySpinWaitStrategy
性能最好,适合用于低延迟的系统。在要求极高性能且事件处理线程数小于CPU逻辑核心树的场景中,推荐使用此策略;例如,CPU开启超线程的特性。
清除Ring Buffer中的对象
通过Disruptor传递数据时,对象的生存期可能比预期的更长。为避免发生这种情况,可能需要在处理事件后清除事件。如果只有一个事件处理程序,则需要在处理器中清除对应的对象。如果您有一连串的事件处理程序,则可能需要在该链的末尾放置一个特定的处理程序来处理清除对象。
class ObjectEvent<T>
{
T val;
void clear()
{
val = null;
}
}
public class ClearingEventHandler<T> implements EventHandler<ObjectEvent<T>>
{
public void onEvent(ObjectEvent<T> event, long sequence, boolean endOfBatch)
{
// Failing to call clear here will result in the
// object associated with the event to live until
// it is overwritten once the ring buffer has wrapped
// around to the beginning.
event.clear();
}
}
public static void main(String[] args)
{
Disruptor<ObjectEvent<String>> disruptor = new Disruptor<>(
() -> ObjectEvent<String>(), bufferSize, DaemonThreadFactory.INSTANCE);
disruptor
.handleEventsWith(new ProcessingEventHandler())
.then(new ClearingObjectHandler());
}
Disruptor—核心概念及体验的更多相关文章
- disruptor 核心概念 二
一.Disruptor图解 二.disruptor核心概念 1.RingBuffer到底是啥?正如名字所说的一样,他是一个环(首尾相接的环)它用做在不同上下文(线程)间传递数据的buffer Ring ...
- 高性能环形队列框架 Disruptor 核心概念
高性能环形队列框架 Disruptor Disruptor 是英国外汇交易公司LMAX开发的一款高吞吐低延迟内存队列框架,其充分考虑了底层CPU等运行模式来进行数据结构设计 (mechanical s ...
- 图解Disruptor框架(二):核心概念
图解Disruptor框架(二):核心概念 概述 上一个章节简单的介绍了了下Disruptor,这节就是要好好的理清楚Disruptor中的核心的概念.并且会给出个HelloWorld的小例子. 在正 ...
- Javascript本质第一篇:核心概念
很多人在使用Javascript之前都至少使用过C++.C#或Java,面向对象的编程思想已经根深蒂固,恰好Javascript在语法上借鉴了Java,虽然方便了Javascript的入门,但要深入理 ...
- JS核心概念
Javascript本质第一篇:核心概念 很多人在使用Javascript之前都至少使用过C++.C#或Java,面向对象的编程思想已经根深蒂固,恰好Javascript在语法上借鉴了Java,虽 ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
- Flink SQL 核心概念剖析与编程案例实战
本次,我们从 0 开始逐步剖析 Flink SQL 的来龙去脉以及核心概念,并附带完整的示例程序,希望对大家有帮助! 本文大纲 一.快速体验 Flink SQL 为了快速搭建环境体验 Flink SQ ...
- .NET WebSockets 核心原理初体验
上个月我写了<.NET gRPC核心功能初体验>, 里面使用gRPC双向流做了一个打乒乓球的Demo, 实时双向这两个标签是不是很熟悉,对, WebSockets也可以做实时双向通信. 本 ...
- 领域驱动设计(DDD)部分核心概念的个人理解
领域驱动设计(DDD)是一种基于模型驱动的软件设计方式.它以领域为核心,分析领域中的问题,通过建立一个领域模型来有效的解决领域中的核心的复杂问题.Eric Ivans为领域驱动设计提出了大量的最佳实践 ...
随机推荐
- HDU-3478Catch二分图的否命题
HDU-3478Catch 题意:考虑Thief能否: 由于我推着推着就想到必须要三点可以互通,和二分图的结论正好相反,所以就试了一发, 真没想到thief的初始位置是不用考虑的. 下面是ac代码: ...
- Educational Codeforces Round 44#985DSand Fortress+二分
传送门:送你去985D: 题意: 你有n袋沙包,在第一个沙包高度不超过H的条件下,满足相邻两个沙包高度差小于等于1的条件下(注意最小一定可以为0),求最少的沙包堆数: 思路: 画成图来说,有两种可能, ...
- hud 3555 Bomb 数位dp
Bomb Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) Total Subm ...
- 深入浅出TypeScript(4)- 使用接口和类型别名
在TypeScript中,为了可以约束对象定义,提供了两个新的特性,接口和类型别名. TypeScript中的接口 在强类型语言中,都有接口的概念,那么TypeScript中的接口是如何使用的呢? 接 ...
- JS执行机制详解,定时器时间间隔的真正含义
壹 ❀ 引 通过结果倒推过程是我们常用的思考模式,我在上一篇学习promise笔记中,有少量关于promise执行顺序的例子,通过倒推,我成功让自己对于js执行机制的理解一塌糊涂,js事件机制,事件 ...
- html/css中相对定位relative和绝对定位absolute的用法
一.相对定位(position:relative) 1.相对定位:将盒子的position属性设置为relative:可通过left.top.right.bottom设置偏移量. 相对定位基础用法示例 ...
- SpringBoot + JPA问题汇总
实体类有继承父类,但父类没有单独标明注解 异常表现 Caused by: org.hibernate.AnnotationException: No identifier specified for ...
- SecureCRT安装及破解
### SecureCRT简介 > SecureCRT是一款支持SSH(SSH1和SSH2)的终端仿真程序,简单地说是Windows下登录UNIX或Linux服务器主机的软件. > &g ...
- C++ lambda的演化
翻译自https://www.bfilipek.com/2019/02/lambdas-story-part1.html与https://www.bfilipek.com/2019/02/lambda ...
- 最佳内存缓存框架Caffeine
Caffeine是一种高性能的缓存库,是基于Java 8的最佳(最优)缓存框架. Cache(缓存),基于Google Guava,Caffeine提供一个内存缓存,大大改善了设计Guava's ca ...