Spark系列-核心概念
一. Spark核心概念
- Master,也就是架构图中的Cluster Manager。Spark的Master和Workder节点分别Hadoop的NameNode和DataNode相似,是一种主从结构。Master是集群的领导者,负责协调和管理集群内的所有资源(接收调度和向WorkerNode发送指令)。从大类上来分Master分为local和cluster两大类
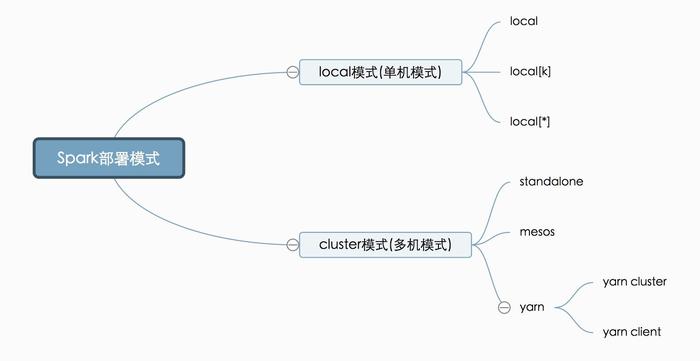
- local:也就是本地模式,所有计算都在一台服务器上完成,通常用于本地开发调试。思维导图中
- local:表示启动一个线程,所有的计算都在这个线程中完成
- local[k]:启动k个worker线程
- local[*]:按照当前服务器的cpu核数来启动
- cluster:也就是集群模式,由多台服务器并行执行。
- standalone:spark自带的资源管理器
- mesos:由mesos来管理
- yarn:通常和MapReduce作业一样,资源共享,所以使用的最多。(yarn cluster:所有调度资源都在集群上运行,yarn client:出了spark driver和master进程,其余都在集群上)
- local:也就是本地模式,所有计算都在一台服务器上完成,通常用于本地开发调试。思维导图中
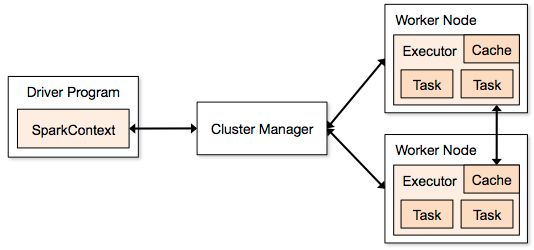
- Worker,也就是WorkderNode,负责执行Master所发送的指令,来具体分配资源并执行任务
- Driver:一个Spark job运行前会启动一个Driver进程,也就是作业的主进程,负责解析和生成各个Stage,并调度Task到Executor上
- Executer:负责执行作业。如图中所以,Executer是分步在各个Worker Node上,接收来自Driver的命令并加载Task
- SparkContext:程序运行调度的核心,高层调度去DAGScheduler划分程序的每个阶段,底层调度器TaskScheduler划分每个阶段具体任务
- DAGScheduler:负责高层调度,划分stage并生产DAG有向无环图
- TaskScheduler:负责具体stage内部的底层调度,具体task的调度和容错
- Job:每次Action都会触发一次Job,一个Job可能包含一个或多个stage
- Stage:用来计算中间结果的Tasksets。分为ShuffleMapStage和ResultStage,出了最后一个Stage是ResultStage外,其他都是ShuffleMapStage。ShuffleMapStage会产生中间结果,是以文件的方式保存在集群当中,以便能够在不同stage种重用
- Task:任务执行的工作单位,每个Task会被发送到一个节点上,每个Task对应RDD的一个partition.
- RDD:是以partition分片的不可变,Lazy级别数据集合
- 算子
- Transformation:由DAGScheduler划分到pipeline中,是Lazy级别的,不会触发任务的执行
- Action:会触发Job来执行pipeline中的运算
Spark系列-核心概念的更多相关文章
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
- Spark系列-SparkSQL实战
Spark系列-初体验(数据准备篇) Spark系列-核心概念 Spark系列-SparkSQL 之前系统的计算大部分都是基于Kettle + Hive的方式,但是因为最近数据暴涨,很多Job的执行时 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- ZooKeeper 系列(一)—— ZooKeeper核心概念详解
一.Zookeeper简介 二.Zookeeper设计目标 三.核心概念 3.1 集群角色 3.2 会话 3.3 数据节点 3.4 节点 ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- ZooKeeper系列(一)—— ZooKeeper 简介及核心概念
一.Zookeeper简介 Zookeeper 是一个开源的分布式协调服务,目前由 Apache 进行维护.Zookeeper 可以用于实现分布式系统中常见的发布/订阅.负载均衡.命令服务.分布式协调 ...
- Storm 系列(二)—— Storm 核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的 Storm 流处理程序被称为 Storm topology(拓扑).它是一个是由 Spouts 和 Bolts 通过 Stre ...
随机推荐
- out参数ref参数params 可变参数
1.我们在主函数中调用其他函数,我们管主函数为调用者,其他函数为被调用者. 如果被调用者,想要得到调用者的值:传参 使用静态字段来模拟全局变量 在方法外类里写字段 public static _na ...
- SpringMVC中数据转换
SpringMVC中接收到的数据都是String形式,然后再根据反射机制将String转换成对应的类型.如果此时想接收一个Date类型,那么我们可以定义一个转换器来完成. 例如,我们有下面的Emp类: ...
- 彻底弄懂HTTP缓存机制及原理(转载)
https://www.cnblogs.com/chenqf/p/6386163.html 前言 Http 缓存机制作为 web 性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系 ...
- vue + element ui 阻止表单输入框回车刷新页面
问题 在 vue+element ui 中只有一个输入框(el-input)的情况下,回车会提交表单. 解决方案 在 el-form 上加上 @submit.native.prevent 这个则会阻止 ...
- python学习之老男孩python全栈第九期_day013知识点总结
# l = [1,2,3]# 索引# 循环 for # list # dic # str # set # tuple # f = open() # range() # enumerate'''prin ...
- HDU4336 Card Collector(期望 状压 MinMax容斥)
题意 题目链接 \(N\)个物品,每次得到第\(i\)个物品的概率为\(p_i\),而且有可能什么也得不到,问期望多少次能收集到全部\(N\)个物品 Sol 最直观的做法是直接状压,设\(f[sta] ...
- JS基础(四)之jQuery
31.jQuery(http://jquery.com/)是一个快速.简洁的JavaScript框架. 它封装了JavaScript常用的功能代码,提供一种便捷的JavaScript设计模式,优化HT ...
- input pattern中常用的正则表达式
常用的正则表达式 pattern的用法,只是列出来一些常用的正则: 信用卡 [0-9]{13,16} 银联卡 ^62[0-5]\d{13,16}$ Visa: ^4[0-9]{12}(?:[0-9]{ ...
- Android View的事件分发机制和滑动冲突解决方案
这篇文章会先讲Android中View的事件分发机制,然后再介绍Android滑动冲突的形成原因并给出解决方案.因水平有限,讲的不会太过深入,只希望各位看了之后对事件分发机制的流程有个大概的概念,并且 ...
- ES6入门——类的概念
1.Class的基本用法 概述 JavaScript语言的传统方式是通过构造函数,定义并生成新对象.这种写法和传统的面向对象语言差异很大,下面是一个例子: function Point(x, y) { ...