Ambari 自定义服务集成原理介绍
之前,在 github 上开源了 ambari-Kylin 项目,可离线部署,支持 hdp 2.6+ 及 hdp 3.0+ 。github 地址为:https://github.com/841809077/ambari-Kylin ,欢迎 star 。
这段时间,陆续有不少朋友通过公众号联系到我,问我相关的集成步骤。今天正好休息,索性将 ambari 自定义服务集成的原理给大家整理出来。
它其实不难,但是网络上并没有多少这方面的资料分享,官方也很少,所以学习门槛就稍微高了一些。但你如果能持续关注我,我相信您能快速上手。
一、简述 ambari
ambari 是一个可视化管理 Hadoop 生态系统的一个开源服务,像 hdfs、yarn、mapreduce、zookeeper、hive、hbase、spark、kafka 等都可以使用 ambari 界面来统一安装、部署、监控、告警等。
对于未受 ambari 界面管理的服务,比如 Elasticsearch、Kylin、甚至是一个 jar 包,都可以利用 自定义服务集成相关技术 将 服务 集成到 ambari 界面里。这样,就可以通过 ambari 实现对 自定义服务 的 安装、配置、启动、监听启动状态、停止、指标监控、告警、快速链接 等很多操作,极其方便。
二、宏观了解自定义服务集成原理
对于安装过 ambari 的朋友可能比较熟悉,我们在部署 hdp 集群的时候,在界面上,会让我们选择 hdp stack 的版本,比如有 2.0、... 、2.6、3.0、3.1 等,每一个 stack 版本在 ambari 节点上都有对应的目录,里面存放着 hdp 各服务,像 hdfs、yarn、mapreduce、spark、hbase 这些,stack 版本高一些的,服务相对多一些。stack 版本目录具体在 ambari-server 节点的 /var/lib/ambari-server/resources/stacks/HDP 下,我们用 python 开发的自定义服务脚本就会放到这个目录下。

将自定义服务放到指定目录下,我们需要重启 ambari server 才能在 添加服务 界面加载出来我们的自定义服务,ambari 在安装自定义服务的过程中,也会将 python 开发的自定义服务脚本分发到 agent 节点上,由 agent 节点的 自定义服务脚本 来执行 安装、部署 步骤。
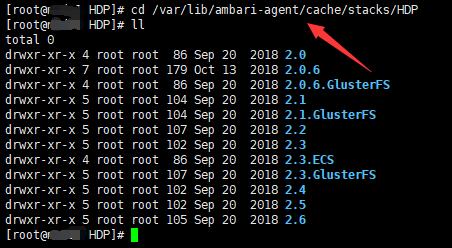
等通过 ambari 安装自定义服务之后,ambari 会在数据库(比如 mysql)相关表里将自定义服务相关信息进行保存,和记录其它 hdp 服务一样的逻辑。
三、微观了解自定义服务集成原理
一个自定义服务暂且将它定义为一个项目,项目名称须为大写,使用 python 编写。该项目框架有那么几个必不可少的文件或目录,分别是:
metainfo.xml 文件:描述了对整个项目的约束配置,是一个 核心 文件。
configuration 目录:里面放置一个或多个 xml 文件,用于将该服务的配置信息展示在前端页面,也可以在ambari 页面上对服务的一些配置做更改,如下图所示:

package 目录:里面包含 scripts 文件夹,该目录下存放着 python 文件,用于对服务的安装、配置、启动、停止等操作。自定义服务 python 脚本依赖的模块是 resource_management 。该模块分布在不同的目录下,但内容是一致的,如下图所示:

除了上述必不可少的目录或文件之外,还有一些文件可以丰富我们自定义服务的功能。比如:
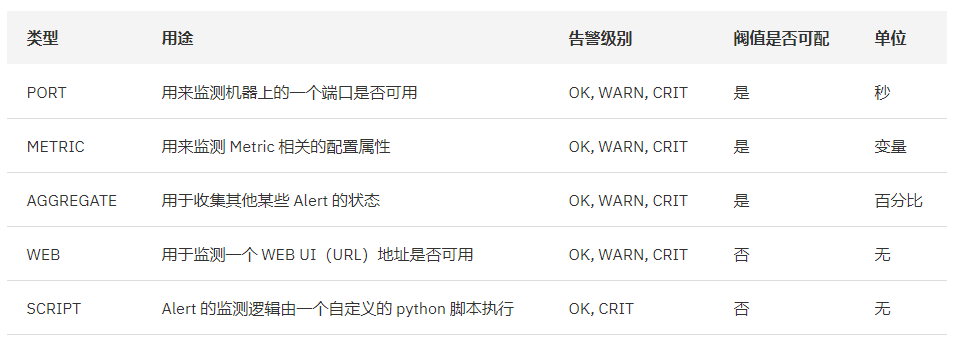
alerts.json 文件:描述 ambari 对服务的 告警 设置。告警类型有 WEB、Port、Metric、Aggregate 和 Script ,如下图所示:
quicklinks.json 文件:用于生成快速链接,实现 url 的跳转。可支持多个 url 展示。
role_command_order.json 文件:决定各个服务组件之间的启动顺序,详情可参考:https://841809077.github.io/2018/09/26/role_command_order.html
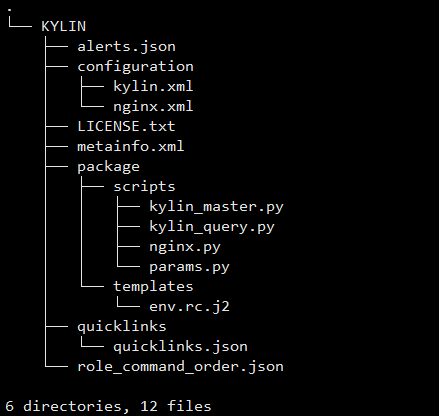
如下图所示,这是自定义服务 KYLIN 的项目框架:
四、课程宣传
ambari 自定义服务集成的细节有很多,但是官方网站上并没有太多的篇幅去介绍这一块知识,只能自己慢慢摸索。幸亏有公司的支持和个人的努力,我已经将 自定义服务 的大部分知识点掌握,特绘制相关的知识脑图,具体如下:
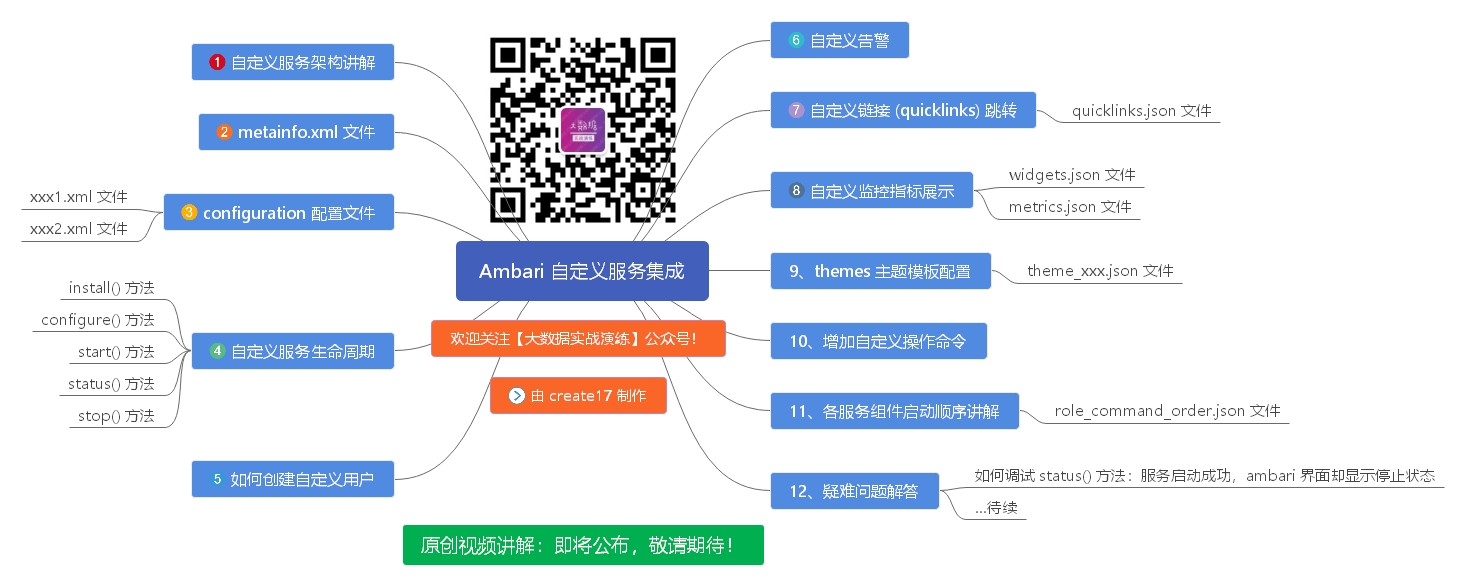
后面我会利用业余时间将上述脑图中的 12 项录制成视频,节约大家学习成本。如果大家有这方面的需求,可以关注我的公众号,加我好友,一起讨论技术与人生。

Ambari 自定义服务集成原理介绍的更多相关文章
- DNS服务基础原理介绍
FQDN 全称域名 localhost(主机名或者是别名).localdomain(域名) FQDN=主机名.域名 根域 . 顶级域名 .com .n ...
- PIE加载自定义服务数据详细介绍
这段时间我一直在研究如何用PIE加载在线地图服务,遇到了许多问题,多亏了技术员小姐姐的帮助,才让我能正确加载ArcGIS Online在线服务.天地图在线地图和谷歌在线地图.我是根据博客园PIE官方博 ...
- Android系统在新进程中启动自定义服务过程(startService)的原理分析
在编写Android应用程序时,我们一般将一些计算型的逻辑放在一个独立的进程来处理,这样主进程仍然可以流畅地响应界面事件,提高用户体验.Android系统为我们提供了一个Service类,我们可以实现 ...
- elasticsearch学习笔记--原理介绍
前言:上一篇中我们对ES有了一个比较大概的概念,知道它是什么,干什么用的,今天给大家主要讲一下他的工作原理 介绍:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户 ...
- Java[4] Jetty工作原理介绍(转)
转自:https://www.ibm.com/developerworks/cn/java/j-lo-jetty/ Jetty 的工作原理以及与 Tomcat 的比较 Jetty 应该是目前最活跃也是 ...
- kafka集群原理介绍
目录 kafka集群原理介绍 (一)基础理论 二.配置文件 三.错误处理 kafka集群原理介绍 @(博客文章)[kafka|大数据] 本系统文章共三篇,分别为 1.kafka集群原理介绍了以下几个方 ...
- zz《分布式服务架构 原理、设计与实战》综合
这书以分布式微服务系统为主线,讲解了微服务架构设计.分布式一致性.性能优化等内容,并介绍了与微服务系统紧密联系的日志系统.全局调用链.容器化等. 还是一样,每一章摘抄一些自己觉得有用的内容,归纳整理, ...
- Redis之哨兵机制(sentinel)——配置详解及原理介绍
说到Redis不得不提哨兵模式,那么究竟哨兵是什么意思?为什么要使用哨兵呢? 接下来一一为您讲解: 1.为什么要用到哨兵 哨兵(Sentinel)主要是为了解决在主从(master-slave)复制架 ...
- 03 Yarn 原理介绍
Yarn 原理介绍 大纲: Hadoop 架构介绍 YARN 产生的背景 YARN 基础架构及原理 Hadoop的1.X架构的介绍 在1.x中的NameNodes只可能有一个,虽然可以通过Se ...
随机推荐
- nyoj 517-最小公倍数 (python range(start, end) range(length))
517-最小公倍数 内存限制:64MB 时间限制:1000ms 特判: No 通过数:2 提交数:11 难度:3 题目描述: 为什么1小时有60分钟,而不是100分钟呢?这是历史上的习惯导致. 但也并 ...
- Centos下的MySQL安装及配置
里使用的是VMware虚拟机和Centos7系统 虚拟机安装这里不多讲,网上教程很多了,这里就介绍下虚拟机的网络配置. 虚拟机网络配置 Centos网络连接模式这里设置为桥接模式,不用勾选复制物理网络 ...
- aws msk
1. 建立3个私网子网 2. 建立msk
- Flex实现web版图片查看器
项目需求: 在web端实现图片浏览,具有放大.缩小.滚轴放大缩小.移动.旋转以及范围控制. 成果图:
- H3C交换机console登录配置 v7
一.通过con口只需输入password登陆交换机. [H3C]user-interface aux 0 设置认证方式为密码验证方式 [H3C-ui-aux0] authentication-mode ...
- 面试官:CPU百分百!给你一分钟,怎么排查?有几种方法?
Part0 遇到了故障怎么办? 在生产上,我们会遇到各种各样的故障,遇到了故障怎么办? 不要慌,只有冷静才是解决故障的利器. 下面以一个例子为例,在生产中碰到了CPU 100%的问题怎么办? 在生产中 ...
- 【2018寒假集训 Day2】【动态规划】维修栅栏
维修栅栏 问题描述: 小z最近当上了农场主!不过,还没有来得及庆祝,一件棘手的问题就摆在了小z的面前.农场的栅栏,由于年久失修,出现了多处破损.栅栏是由n块木板组成的,每块木板可能已经损坏也可能没有损 ...
- The absolute uri: [http://java.sun.com/jsp/jstl/core] cannot be resolved in either web.xml or the jar files deployed with this application] with root cause异常处理及解释
1.问题描述: 在web的jsp文件中想用jstl这个标准库,在运行的时候很自然的引用jar包如下: <dependency> <groupId>javax.servlet.j ...
- SpringBoot学习(七)—— springboot快速整合Redis
目录 Redis缓存 简介 引入redis缓存 代码实战 Redis缓存 @ 简介 redis是一个高性能的key-value数据库 优势 性能强,适合高度的读写操作(读的速度是110000次/s,写 ...
- 几种常见设计模式在项目中的应用<Singleton、Factory、Strategy>
一.前言 前几天阅读一框架文档,里面有一段这样的描述 “从对象工厂中………” ,促使写下本文.尽管一些模式简单和简单,但是常用.有用. 结合最近一个项目场景回顾一下里面应用到的一些模式<Sing ...