从SpringBoot构建十万博文聊聊缓存穿透

前言
在博客系统中,为了提升响应速度,加入了 Redis 缓存,把文章主键 ID 作为 key 值去缓存查询,如果不存在对应的 value,就去数据库中查找 。这个时候,如果请求的并发量很大,就会对后端的数据库服务造成很大的压力。
造成原因
- 业务自身代码或数据出现问题
- 恶意攻击、爬虫造成大量空的命中,会对数据库造成很大压力
博客架构
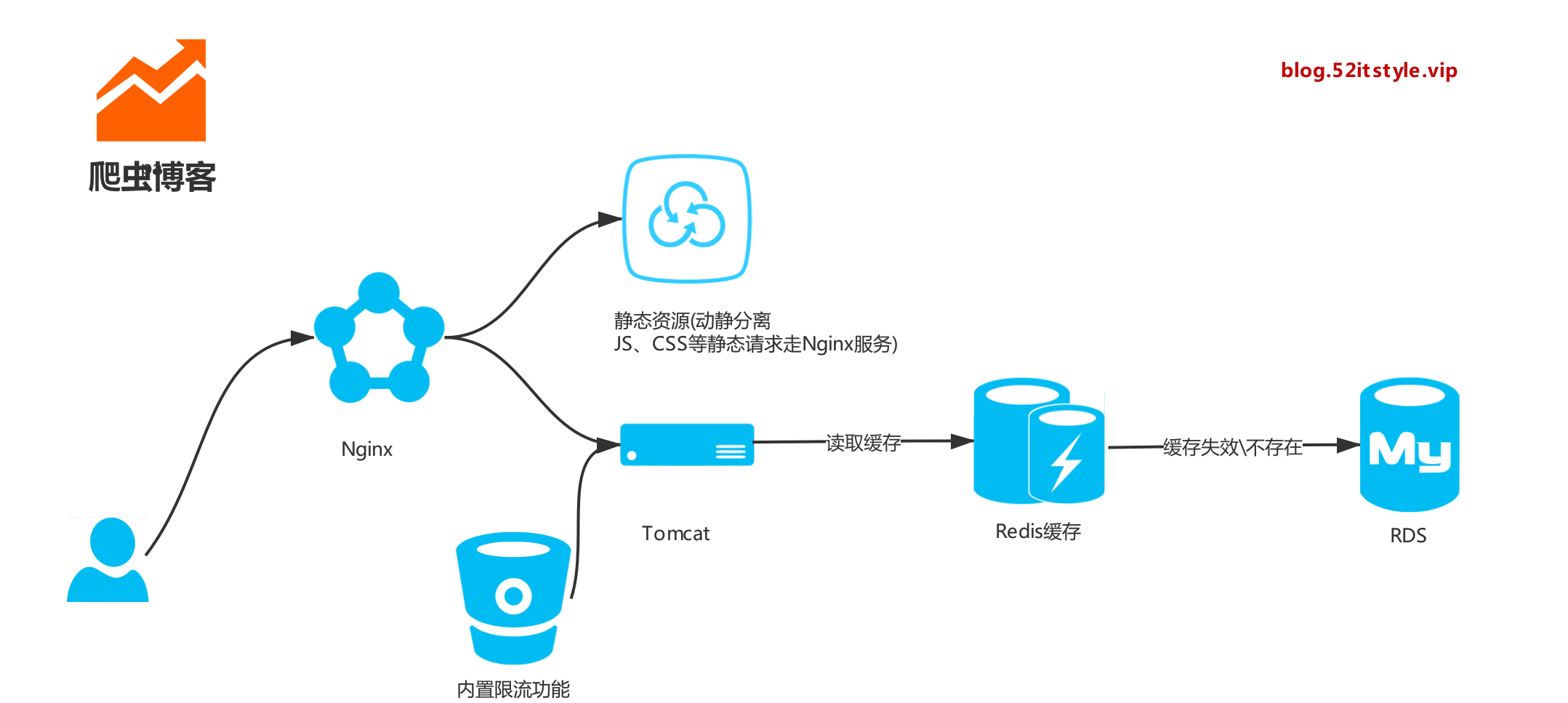
案例分析
由于文章的地址是这样子的:
https://blog.52itstyle.top/49.html
大家很容易猜出,是不是还有 50、51、52 甚至是十万+?如果是正儿八经的爬虫,可能会读取你的总页数。但是有些不正经的爬虫或者人,还真以为你有十万+博文,然后就写了这么一个脚本。
for num in range(1,1000000):
//爬死你,开100个线程
解决方案
设置布隆过滤器,预先将所有文章的主键 ID 哈希到一个足够大的 BitMap 中,每次请求都会经过 BitMap 的拦截,如果 Key 不存在,直接返回异常。这样就避免了对 Redis 缓存以及底层数据库的查询压力。
这里我们使用谷歌开源的第三方工具类来实现:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
编写布隆过滤器:
/**
* 布隆缓存过滤器
*/
@Component
public class BloomCacheFilter {
public static BloomFilter<Integer> bloomFilter = null;
@Autowired
private DynamicQuery dynamicQuery;
/**
* 初始化
*/
@PostConstruct
public void init(){
String nativeSql = "SELECT id FROM blog";
List<Object> list = dynamicQuery.query(nativeSql,new Object[]{});
bloomFilter = BloomFilter.create(Funnels.integerFunnel(), list.size());
list.forEach(blog ->bloomFilter.put(Integer.parseInt(blog.toString())));
}
/**
* 判断key是否存在
* @param key
* @return
*/
public static boolean mightContain(long key){
return bloomFilter.mightContain((int)key);
}
}
然后,每一次查询之前做一次 Key 值校验:
/**
* 博文
*/
@RequestMapping("{id}.shtml")
public String page(@PathVariable("id") Long id, ModelMap model) {
if(BloomCacheFilter.mightContain(id)){
Blog blog = blogService.getById(id);
model.addAttribute("blog",blog);
return "article";
}else{
return "error";
}
}
效率
那么,在数据量很大的情况下,效率如何呢?我们来做个实验,以 100W 为基数。
public static void main(String[] args) {
int capacity = 1000000;
int key = 6666;
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity);
for (int i = 0; i < capacity; i++) {
bloomFilter.put(i);
}
/**返回计算机最精确的时间,单位纳妙 */
long start = System.nanoTime();
if (bloomFilter.mightContain(key)) {
System.out.println("成功过滤到" + key);
}
long end = System.nanoTime();
System.out.println("布隆过滤器消耗时间:" + (end - start));
}
布隆过滤器消耗时间:281299,约等于 0.28 毫秒,匹配速度是不是很快?
错判率
万事万物都有所均衡,既然效率如此之高,肯定其它方面定有所牺牲,通过测试我们发现,过滤器有 3% 的错判率,也就是说,本来没有的文章,有可能通过校验被访问到,然后报错!
public static void main(String[] args) {
int capacity = 1000000;
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity);
for (int i = 0; i < capacity; i++) {
bloomFilter.put(i);
}
int sum = 0;
for (int i = capacity + 20000; i < capacity + 30000; i++) {
if (bloomFilter.mightContain(i)) {
sum ++;
}
}
//0.03
DecimalFormat df=new DecimalFormat("0.00");//设置保留位数
System.out.println("错判率为:" + df.format((float)sum/10000));
}
通过源码阅读,发现 3% 的错判率是系统写死的。
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03D);
}
当然我们也可以通过传参,降低错判率。测试了一下,查询速度稍微有一丢丢降低,但也只是零点几毫秒级的而已。
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity,0.01);
那么如何做到零错判率呢?答案是不可能的,布隆过滤器,错判率必须大于零。为了保证文章 100% 的访问率,正常情况下,我们可以关闭布隆校验,只有才突发情况下开启。比如,可以通过阿里的动态参数配置 Nacos 实现。
@NacosValue(value = "${bloomCache:false}", autoRefreshed = true)
private boolean bloomCache;
//省略部分代码
if(bloomCache||BloomCacheFilter.mightContain(id)){
Blog blog = blogService.getById(id);
model.addAttribute("blog",blog);
return "article";
}else{
return "error";
}
小结
缓存穿透大多数情况下都是恶意攻击导致的空命中率。虽然十万博客还没有被百度收录,每天也就寥寥的几十个IP,但是梦想还是有的,万一实现了呢?所以,还是要做好准备的!
源码
https://gitee.com/52itstyle/spring-boot-blog
从SpringBoot构建十万博文聊聊缓存穿透的更多相关文章
- 从SpringBoot构建十万博文聊聊限流特技
前言 在开发十万博客系统的的过程中,前面主要分享了爬虫.缓存穿透以及文章阅读量计数等等.爬虫的目的就是解决十万+问题:缓存穿透是为了保护后端数据库查询服务:计数服务解决了接近真实阅读数以及数据库服务的 ...
- 从SpringBoot构建十万博文聊聊Tomcat集群监控
前言 在十万博文终极架构中,我们使用了Tomcat集群,但这并不能保证系统不会出问题,为了保证系统的稳定运行,我们还需要对 Tomcat 进行有效的运维监控手段,不至于问题出现或者许久一段时间才知道. ...
- 从SpringBoot构建十万博文聊聊高并发文章浏览量设计
前言 在经历了,缓存.限流.布隆穿透等等一系列加强功能,十万博客基本算是成型,网站上线以后也加入了百度统计来见证十万+ 的整个过程. 但是百度统计并不能对每篇博文进行详细的浏览量统计,如果做一些热点博 ...
- SpringBoot开发案例之打造十万博文Web篇
前言 通过 Python 爬取十万博文之后,最重要的是要让互联网用户访问到,那么如何做呢? 选型 从后台框架.前端模板.数据库连接池.缓存.代理服务.限流等组件多个维度选型. 后台框架 SpringB ...
- SpringBoot微服务电商项目开发实战 --- Redis缓存雪崩、缓存穿透、缓存击穿防范
最近已经推出了好几篇SpringBoot+Dubbo+Redis+Kafka实现电商的文章,今天再次回到分布式微服务项目中来,在开始写今天的系列五文章之前,我先回顾下前面的内容. 系列(一):主要说了 ...
- springboot中redis的缓存穿透问题
什么是缓存穿透问题?? 我们使用redis是为了减少数据库的压力,让尽量多的请求去承压能力比较大的redis,而不是数据库.但是高并发条件下,可能会在redis还没有缓存的时候,大量的请求同时进入,导 ...
- 从.Net到Java学习第七篇——SpringBoot Redis 缓存穿透
从.Net到Java学习系列目录 场景描述:我们在项目中使用缓存通常都是先检查缓存中是否存在,如果存在直接返回缓存内容,如果不存在就直接查询数据库然后再缓存查询结果返回.这个时候如果我们查询的某一个数 ...
- Redis基础用法、高级特性与性能调优以及缓存穿透等分析
一.Redis介绍 Redis是一个开源的,基于内存的结构化数据存储媒介,可以作为数据库.缓存服务或消息服务使用.Redis支持多种数据结构,包括字符串.哈希表.链表.集合.有序集合.位图.Hype ...
- redis的缓存穿透、击穿、雪崩以及实用解决方案
今天来聊聊redis的缓存穿透.击穿.雪崩以及解决方案,其中解决方案包括类似于布隆过滤器这种网上一搜一大片但是实际生产部署有一定复杂度的,也有基于spring注解通过一行代码就能解决的,其中各有优劣, ...
随机推荐
- .Net进程外session配置
配置步骤: 1.开启 ASP.NET状态服务:cmd状态下:services.msc 2.配置web.config文件,在system.web下加入如下配置 <sessionState mode ...
- JDBC连接mysql数据库操作
一.创建所需对象,并进行初始化 Connection connection=null; Statement statement=null; PreparedStatement pst; ResultS ...
- 最近学习了HBase
HBase是什么 最近学习了HBase,正常来说写这篇文章,应该从DB有什么缺点,HBase如何弥补DB的缺点开始讲会更有体感,但是本文这些暂时不讲,只讲HBase,把HBase相关原理和使用讲清楚, ...
- 2. python Mac 安装 dlib
在macOS上: 从Mac App Store安装 XCode(或安装XCode命令行工具)(最低版本是:xcode8 以上) 有 homebrew 安装 有 CMAKE 安装 基础包 :numpy ...
- 浅谈 Attention 机制的理解
什么是注意力机制? 注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制.例如人的视觉在处理一张图片时,会通过快速扫描全局图像,获得需要重点关注的目 ...
- 《Graph Attention Network》阅读笔记
基本信息 论文题目:GRAPH ATTENTION NETWORKS 时间:2018 期刊:ICLR 主要动机 探讨图谱(Graph)作为输入的情况下如何用深度学习完成分类.预测等问题:通过堆叠这种层 ...
- springboot之mybatisplus,mp的简单理解
这是一张简单的service的继承图.可以看到我们的执行类,即XxxServiceImpl的继承关系. 从上到下,ServiceImpl和BaseMapper是一个依赖关系,ServiceImpl和I ...
- 《ElasticSearch6.x实战教程》之分词
第四章-分词 下雨天留客天留我不留 本打算先介绍"简单搜索",对ES的搜索有一个直观的感受.但在写的过程中发现分词无论如何都绕不过去.term查询,match查询都与分词息息相关, ...
- 渐进式web应用开发---promise式数据库(五)
在前面的一篇文章中,我们已经实现了使用indexedDB实现ajax本地数据存储的功能,详情,请看这篇文章.现在我们需要把上面的一篇文章中的代码使用promise结构来重构下.我们为什么需要使用pro ...
- 史上最全IO流详解,看着一篇足矣
一:要了解IO,首先了解File类 File类里面的部分常量,方法 No. 方法或常量 类型 描述 1 public static final String pathSeparator 常量 表示路径 ...