头部姿态估计 - Android
概括
通过Dlib获得当前人脸的特征点,然后通过旋转平移标准模型的特征点进行拟合,计算标准模型求得的特征点与Dlib获得的特征点之间的差,使用Ceres不断迭代优化,最终得到最佳的旋转和平移参数。
Android版本在原理上同C++版本:头部姿态估计 - OpenCV/Dlib/Ceres。
主要介绍在移植过程中遇到的问题。
使用环境
系统环境:Ubuntu 18.04
Java环境:JRE 1.8.0
使用语言:C++(clang), Java
编译工具:Android Studio 3.4.1
- CMake 3.10.2
- LLDB
- NDK 20.0
上述工具在Android Studio中SDK的管理工具里下载即可。
第三方工具
Dlib:用于获得人脸特征点
Ceres:用于进行非线性优化
源代码
https://github.com/Great-Keith/head-pose-estimation/tree/master/android/landmark-fitting
准备工作
第三方库的Android接口
Dlib
使用的GitHub上提供的现成接口:https://github.com/tzutalin/dlib-android
该项目还提供了具体的app样例:https://github.com/tzutalin/dlib-android-app/
我们所做的app就是建立在该app样例之上。
Ceres
具体使用可以参见前一篇随笔:Android平台使用Ceres Solver
总之最后我们整合Dlib和Ceres得到了我们app的基本框架:https://github.com/Great-Keith/dlib-android-app
增加前置摄像头转换
增设转换按钮
最初的样例dlib-android-app仅提供了后置摄像头,这对于单人测试很不方便,因此我们修改代码来实现一个切换前后摄像头的按钮。
首先找到相机视图res/layout/camera_connection_fragment.xml,在其右上角增加 Switch 按钮。
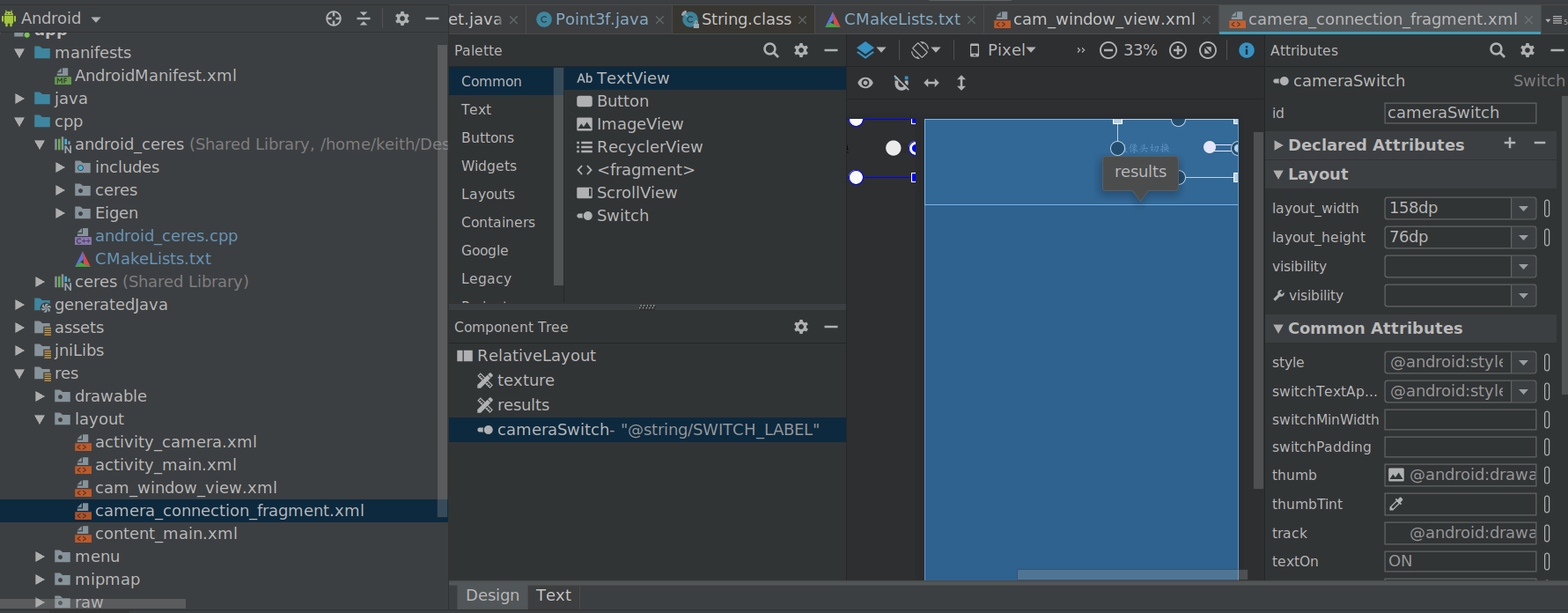
最后我们找到该app的实现细节,是通过自己新建一个CameraConnectionFragment类来替换原本的Fragment,从而实现的一系列操作。该类中setUpCameraOutputs方法实现了对相机的选择,其会便利移动设备上可用的所有相机,优先选择后置摄像头。
给该方法增加一个boolean b参数,用于选择摄像头:
if(b) {
// 只使用后置摄像头
// If facing back camera or facing external camera exist, we won't use facing front camera
if (num_facing_back_camera != null && num_facing_back_camera > 0) {
// 前置摄像头跳过(如果有后置摄像头)
// We don't use a front facing camera in this sample if there are other camera device facing types
if (facing != null && facing == CameraCharacteristics.LENS_FACING_FRONT) {
continue;
}
}
} else {
// 只使用前置摄像头
if (num_facing_front_camera != null && num_facing_front_camera > 0) {
// 前置摄像头跳过(如果有后置摄像头)
// We don't use a front facing camera in this sample if there are other camera device facing types
if (facing != null && facing == CameraCharacteristics.LENS_FACING_BACK) {
continue;
}
}
}
然后在初始化的过程中关联上我们的Switch按钮:
switchBtn = view.findViewById(R.id.cameraSwitch);
switchBtn.setOnCheckedChangeListener(new CompoundButton.OnCheckedChangeListener() {
@Override
public void onCheckedChanged(CompoundButton compoundButton, boolean b) {
closeCamera();
openCamera(textureView.getWidth(), textureView.getHeight(), b);
}
});
[NOTE] 通过openCamera将参数b传输给setUpCameraOutputs。
修复前置摄像头倒转
修改完后我们运行程序,会发现出现预显示窗口倒转的情况,因此我们需要对预显示窗口的显示进行翻转。
找到相机类处理捕捉到的画面的监听器OnGetImageListener,其中对捕捉到的画面进行处理的函数即为drawResizedBitmap,在最终绘制之前,增加矩阵翻转。
/* If using front camera, matrix should rotate 180 */
if(!switchBtn.isChecked()) {
matrix.postTranslate(-dst.getWidth() / 2.0f, -dst.getHeight() / 2.0f);
matrix.postRotate(180);
matrix.postTranslate(dst.getWidth() / 2.0f, dst.getHeight() / 2.0f);
}
final Canvas canvas = new Canvas(dst);
canvas.drawBitmap(src, matrix, null);
[NOTE] 在该类中没有办法直接获取CameraId来判断当前使用的相机是前置还是后置,因此我们通过之前的Switch按钮来进行判断。查阅可能可以使用的Camera类在API 21以后淘汰使用了。
主要过程
还是在相机的监听器当中,我们可以看到dlib获得的特征点数据,并进行绘制。
mInferenceHandler.post(
new Runnable() {
@Override
public void run() {
// ...
long startTime = System.currentTimeMillis();
List<VisionDetRet> results;
synchronized (OnGetImageListener.this) {
results = mFaceDet.detect(mCroppedBitmap);
}
long endTime = System.currentTimeMillis();
mTransparentTitleView.setText("Time cost: " + String.valueOf((endTime - startTime) / 1000f) + " sec");
// Draw on bitmap
if (results != null) {
for (final VisionDetRet ret : results) {
// 绘制人脸框和特征点
// ...
}
}
}
mWindow.setRGBBitmap(mCroppedBitmap);
mIsComputing = false;
}
});
我们选择在绘制人脸框和特征点的for循环中增加优化。
首先将特征点复制一份Point数组,用于作为传入参数。
/* Transform landmarks to array, which is needed by JNI */
Point[] tmp = landmarks.toArray(new Point[0]);
初始化好double x[]随后我们可以调用我们的CeresSolver类来进行处理,得到的最优解通过指针x返回。
CeresSolver.solve(x, tmp);
最后我们再调用两个方法来进行将三维特征点转化为二维的映射。
Point3f[] points3f = CeresSolver.transform(x);
Point[] points2d = CeresSolver.transformTo2d(points3f);
[NOTE] 项目中的二维点使用android.graphics.Point(对应C++中使用的dlib::point),而三维点使用我们自己建的一个类Point3f(对应C++中使用的dlib::vector<double, 3>)。
综上,我们实际上要实现的是一个提供Ceres支持的工具类CeresSolver,下面具体描述。
CeresSolver类与其JNI接口
初始化
我们需要读取标准模型特征点的三维坐标,该坐标存储于landmarks.txt文件中。对于Android工程,我们将该文件放在assets目录下。在CameraActivity初始化onCreate的时候顺带进行初始化:
CeresSolver.init(getResources().getAssets().open("landmarks.txt"));
该初始化具体过程如下:
public static void init(InputStream in) {
try {
InputStreamReader inputReader = new InputStreamReader(in);
BufferedReader bufReader = new BufferedReader(inputReader);
String line;
int i = 0;
while((line = bufReader.readLine()) != null) {
String[] nums = line.split(" ");
modelLandmarks[i] = new Point3f(Double.valueOf(nums[0]),
Double.valueOf(nums[1]),
Double.valueOf(nums[2]));
i++;
}
} catch (Exception e) {
Log.e(TAG, "Loading model landmarks from file failed.");
e.printStackTrace();
}
Log.i(TAG, "Loading model landmarks from file succeed.");
init_();
}
init_是一个JNI的函数,用于将CeresSolver类中读取的modelLandmark数据读取到本地变量``model_landmark,并提前读取一些jmethodID和jfieldID。
[NOTE] 其实也可以通过调用jmethodID或者jfieldID来获得Java类中的modelLandmark,但我目前不是很清楚两种方法之间在效率上的差异。
[NOTE] 将这些数据提前在cpp文件中读取并保存成静态变量,这个过程有一些问题,由于Java的垃圾回收机制,JNI中的静态类型,有些会失去关联(可能是指针?)。比如jfieldID的调用往往没有问题,但是jclass就会失效,因此jclass类型无法提前先初始化好。
解决最小二乘
同C++一样,提前定义好CostFunctor:
struct CostFunctor {
public:
explicit CostFunctor(JNIEnv *_env, jobjectArray _shape){
env = _env;
shape = _shape; }
bool operator()(const double* const x, double* residual) const {
/* Init landmarks to be transformed */
fitting_landmarks.clear();
for (auto &model_landmark : model_landmarks)
fitting_landmarks.push_back(model_landmark);
transform(fitting_landmarks, x);
std::vector<Point2d> model_landmarks_2d;
landmarks_3d_to_2d(fitting_landmarks, model_landmarks_2d);
/* Calculate the energe (Euclid distance from two points) */
for(unsigned long i=0; i<LANDMARK_NUM; i++) {
jobject point = env->GetObjectArrayElement(shape, static_cast<jsize>(i));
long tmp1 = env->GetIntField(point, getX2d) - model_landmarks_2d.at(i).x;
long tmp2 = env->GetIntField(point, getY2d) - model_landmarks_2d.at(i).y;
residual[i] = sqrt(tmp1 * tmp1 + tmp2 * tmp2);
}
return true;
}
private:
JNIEnv *env;
jobjectArray shape; /* 3d landmarks coordinates got from dlib */
};
基本与C++相同,唯一不同的地方是shape的类型直接使用的JNI中的类型jobjectArray,并且需要使用到调用,因此需要在初始化的时候导入JNIEnv环境。
其余在调用部分就和C++部分基本相同,所有的JNI函数都需要注意在参数传入和传出的时候进行类型的转变。
坐标转化
涉及三维点旋转和平移的转化以及三维点转二维点的转化,同C++中的涉及。
需要另外提供JNI接口给Java中的类使用,主要涉及jobject的方法调用、成员访问等等。当然,也可以在Java中实现这些方法,感觉效率会更高一些。这一部分具体可以看源代码,其中有详细的注释。
信息打印(Debug)
在Android项目中,输出的消息很多,debug的难度是比较大的,因此需要灵活使用打印信息来获得所需要的信息。其中Java程序中可以使用android.util.Log来进行输出,可以在logcat或者run中进行查看。具体比如:
Log.i(TAG, String.format("After Solve x: %f %f %f %f %f %f",
x[0], x[1], x[2], x[3], x[4], x[5]));
在JNI的cpp文件中,定义如下宏定义来进行输出:
#define TAG "CERES-CPP"
#define LOGD(...) __android_log_print(ANDROID_LOG_DEBUG, TAG,__VA_ARGS__)
#define LOGI(...) __android_log_print(ANDROID_LOG_INFO, TAG,__VA_ARGS__)
#define LOGW(...) __android_log_print(ANDROID_LOG_WARN, TAG,__VA_ARGS__)
#define LOGE(...) __android_log_print(ANDROID_LOG_ERROR, TAG,__VA_ARGS__)
#define LOGF(...) __android_log_print(ANDROID_LOG_FATAL, TAG,__VA_ARGS__)
使用该Log需要在CMakeLists.txt中需要链接log库。
结果测试
进入相机界面,并进行摄像头的切换。

这边可以看到,刚打开的时候,这个求解得到的点是非常混乱的,这是由于初始值没有设置好,在经过一段时间后就会进入正常状态。
*[NOTE] 后来我在读入的模型特征点的时候加入一个缩放系数(1/100),效果得到很好的改善。
实时效果

总结
因为整体逻辑在C++已经实现了,所以复制这个逻辑的过程并不困难。难点主要是在JNI的使用上,没有接触过NDK的我在将Ceres移植到安卓平台上花费了大量的时间,最后写了Android平台使用Ceres Solver总结了这个过程。当这一部分完成之后,后面的过程就快了起来,但关于JNI的很多特性,跟Java息息相关,还需要更多的摸索。
进一步可以优化
- 初始值选择问题;
- 去除app中的识别行人模块;
- 优化使用Ceres求解最小二乘的过程;
- 前后摄像头显示区别;
- 优化接口,使其更据扩展性。
头部姿态估计 - Android的更多相关文章
- 头部姿态估计 - OpenCV/Dlib/Ceres
基本思想 通过Dlib获得当前人脸的特征点,然后通过旋转平移标准模型的特征点进行拟合,计算标准模型求得的特征点与Dlib获得的特征点之间的差,使用Ceres不断迭代优化,最终得到最佳的旋转和平移参数. ...
- 使用unity3d和tensorflow实现基于姿态估计的体感游戏
使用unity3d和tensorflow实现基于姿态估计的体感游戏 前言 之前做姿态识别,梦想着以后可以自己做出一款体感游戏,然而后来才发现too young.但是梦想还是要有的,万一实现了呢.趁着p ...
- Facebook提出DensePose数据集和网络架构:可实现实时的人体姿态估计
https://baijiahao.baidu.com/s?id=1591987712899539583 选自arXiv 作者:Rza Alp Güler, Natalia Neverova, Ias ...
- PCL学习(五)如何在mesh模型上sample更多点及三维物体姿态估计
---恢复内容开始--- 最近在做关于物体姿态估计的项目 基本思路就是 我们在估计物体的pose的时候,需要用分割得到的点云与模型库中的模型做匹配 1.通过基于RANSANC的SAC-IA将点云和模型 ...
- CVPR2020文章汇总 | 点云处理、三维重建、姿态估计、SLAM、3D数据集等(12篇)
作者:Tom Hardy Date:2020-04-15 来源:CVPR2020文章汇总 | 点云处理.三维重建.姿态估计.SLAM.3D数据集等(12篇) 1.PVN3D: A Deep Point ...
- CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等
CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等 CVPR 2020中选论文放榜后,最新开源项目合集也来了. 本届CPVR共接收6656篇论文,中选1470篇,&q ...
- 快速人体姿态估计:CVPR2019论文阅读
快速人体姿态估计:CVPR2019论文阅读 Fast Human Pose Estimation 论文链接: http://openaccess.thecvf.com/content_CVPR_201 ...
- 相机姿态估计(Pose Estimation)
(未完待续.....) 根据针孔相机模型,相机成像平面一点的像素坐标p和该点在世界坐标系下的3D坐标P有$p=KP$的关系,如果用齐次坐标表示则有: $$dp=KP$$ 其中d是空间点深度(为了将p的 ...
- openpose-opencv 的body数据多人体姿态估计
介绍 opencv除了支持常用的物体检测模型和分类模型之外,还支持openpose模型,同样是线下训练和线上调用.这里不做特别多的介绍,先把源代码和数据放出来- 实验模型获取地址:https://gi ...
随机推荐
- 并发编程-concurrent指南-ReadWriteLock-ReentrantReadWriteLock(可重入读写锁)
几个线程都申请读锁,都能获取: import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.ReentrantRea ...
- BZOJ 1067:[SCOI2007]降雨量(RMQ+思维)
http://www.lydsy.com/JudgeOnline/problem.php?id=1067 题意:…… 思路:首先我们开一个数组记录年份,一个记录降雨量,因为年份是按升序排列的,所以我们 ...
- 快速搭建 Windows Kubernetes
背景 接上一篇 Windows 应用容器 后,想要快速且便利的部署与管理它们,可以借助容器编排工具.对于 Windows 容器,在今天 Service Fabric 会是个更为成熟的选择,在业界有更多 ...
- java word转html 报错 org/apache/poi/xwpf/usermodel/IRunBody
最终解决的办法是修改jar包版本,一定要对应上. <dependency> <groupId>org.apache.poi</groupId> <artifa ...
- elasticsearch与ms sql server数据同步
MS SQL Server Download Elasticsearch Install Elasticsearch Follow instructions on https://www.elasti ...
- Atom常用插件、快键键、使用技巧
atom 中间有一条白色的虚线,怎么去掉? Settings/Packages/wrap-guide disable 自动换行 File-Settings-Editor-Soft Wrap(打勾即可) ...
- (转)代码结构中Dao,Service,Controller,Util,Model是什么意思?
作者:技能树IT修真院链接:https://www.zhihu.com/question/58410621/answer/623496434来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- 基于Actor模型的CQRS、ES解决方案分享
开场白 大家晚上好,我是郑承良,跟大家分享的话题是<基于Actor模型的CQRS/ES解决方案分享>,最近一段时间我一直是这个话题的学习者.追随者,这个话题目前生产环境落地的资料少一些,分 ...
- Android studio 3.4.1 使用 bootstrap 中的组件实例
电脑环境: ubuntu18.04 + Android studio 3.4.1 + bootsrtap4 Android studio中板式设计主要使用的 XML 布局文件,而在bootstrap中 ...
- Jira 使用手册
Date Revision version Description author 2018-06-14 V1.0.0 Isaac Zhang 2018-06-22 V1.0.1 1,添加git提交操作 ...