Spark 基础操作
1. Spark 基础
2. Spark Core
3. Spark SQL
4. Spark Streaming
5. Spark 内核机制
6. Spark 性能调优
1. Spark 基础
1.1 Spark 中的相应组件
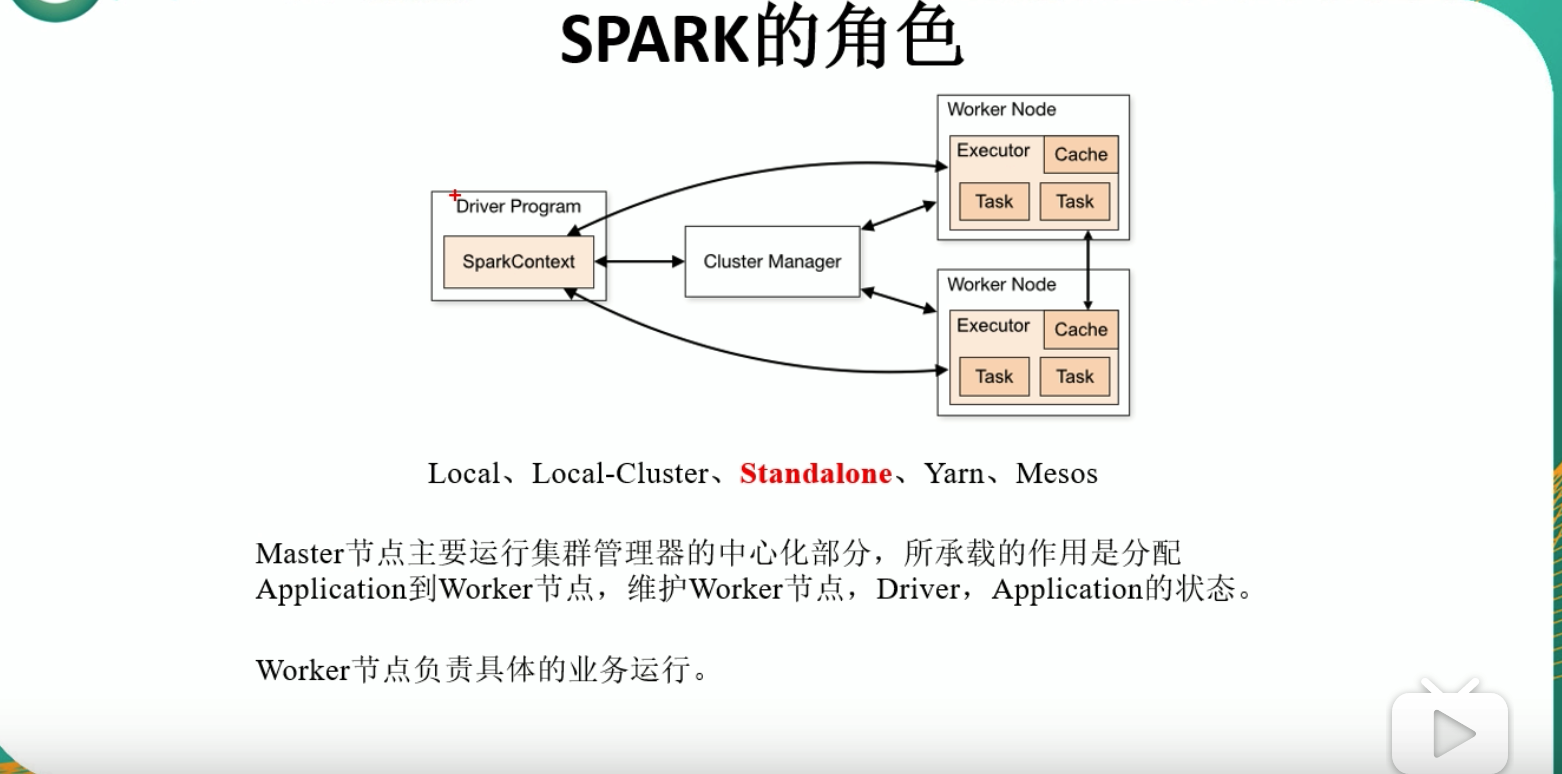
1.2 Standalone 模式安装
// 1. 准备安装包(见下方参考资料): spark-2.1.3-bin-hadoop2.7.tgz
// 2. 修改配置文件
// 2.1 spark-env.sh.template
mv spark-env.sh.template spark-env.sh
SPARK_MASTER_HOST=IP地址
SPARK_MASTER_PORT=7077
// 3. 启动
sbin/start-all.sh
// 4. 浏览器访问
http://IP地址:8080
// 5. 测试官方案例
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://IP地址:7077 --executor-memory 1G --total-executor-cores 2 ./examples/jars/spark-examples_2.11-2.1.3.jar 100
// 6. 使用 Spark Shell 测试 WordCount
bin/spark-shell --master spark://10.110.147.193:7077
sc.textFile("./RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
1.2.1 提交应用程序概述
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://IP地址:7077 --executor-memory 1G --total-executor-cores 2 ./examples/jars/spark-examples_2.11-2.1.3.jar 100--class: 应用程序的启动类,例如,org.apache.spark.examples.SparkPi;--master: 集群的master URL;deploy-mode: 是否发布你的驱动到worker节点(cluster)或者作为一个本地客户端(client);--conf: 任意的Spark配置属性,格式:key=value,如果值包含空格,可以加引号"key=value";application-jar:打包好的应用 jar,包含依赖,这个URL在集群中全局可见。比如hdfs://共享存储系统,如果是file://path,那么所有节点的path都包含同样的jar;application-arguments: 传给main()方法的参数;
1.3 JobHistoryServer 配置
- 修改
spark-defaults.conf.template名称:mv spark-defaults.conf.template spark-defaults.conf; - 修改
spark-defaults.conf文件,开启 Log:spark.eventLog.enabled true;spark.eventLog.dir hdfs://IP地址:9000/directory;- 注意:HDFS 上的目录需要提前存在;
- 修改
spark-env.sh文件,添加如下配置:export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://IP地址:9000/directory";
- 开启历史服务:
sbin/start-history-server.sh; - 执行上面的程序:
org.apache.spark.examples.SparkPi; - 访问:
http//IP地址:4000;
1.4 Spark HA 配置
- zookeeper 正常安装并启动;
- 修改
spark-env.sh文件,添加如下配置:- 注释掉:
SPARK_MASTER_HOST=IP地址;SPARK_MASTER_PORT=7077
export SPARK_DEAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=IP地址1, IP地址2, IP地址3 -Dspark.deploy.zookeeper.dir=/spark"
- 注释掉:
1.5 Yarn 模式安装
- 修改 hadoop 配置文件
yarn-site.xml,添加如下内容:
<!--是否启动一个线程,检查每个任务正在使用的物理内容量,如果任务超出分配值,则直接将其杀掉,默认为true-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程,检查每个任务正在使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 修改
spark-env.sh,添加如下配置:YARN_CONF_DIR=/opt/module/hadoop-2.8.5/etc/hadoopHADOOP_CONF_DIR=/opt/module/hadoop-2.8.5/etc/hadoop
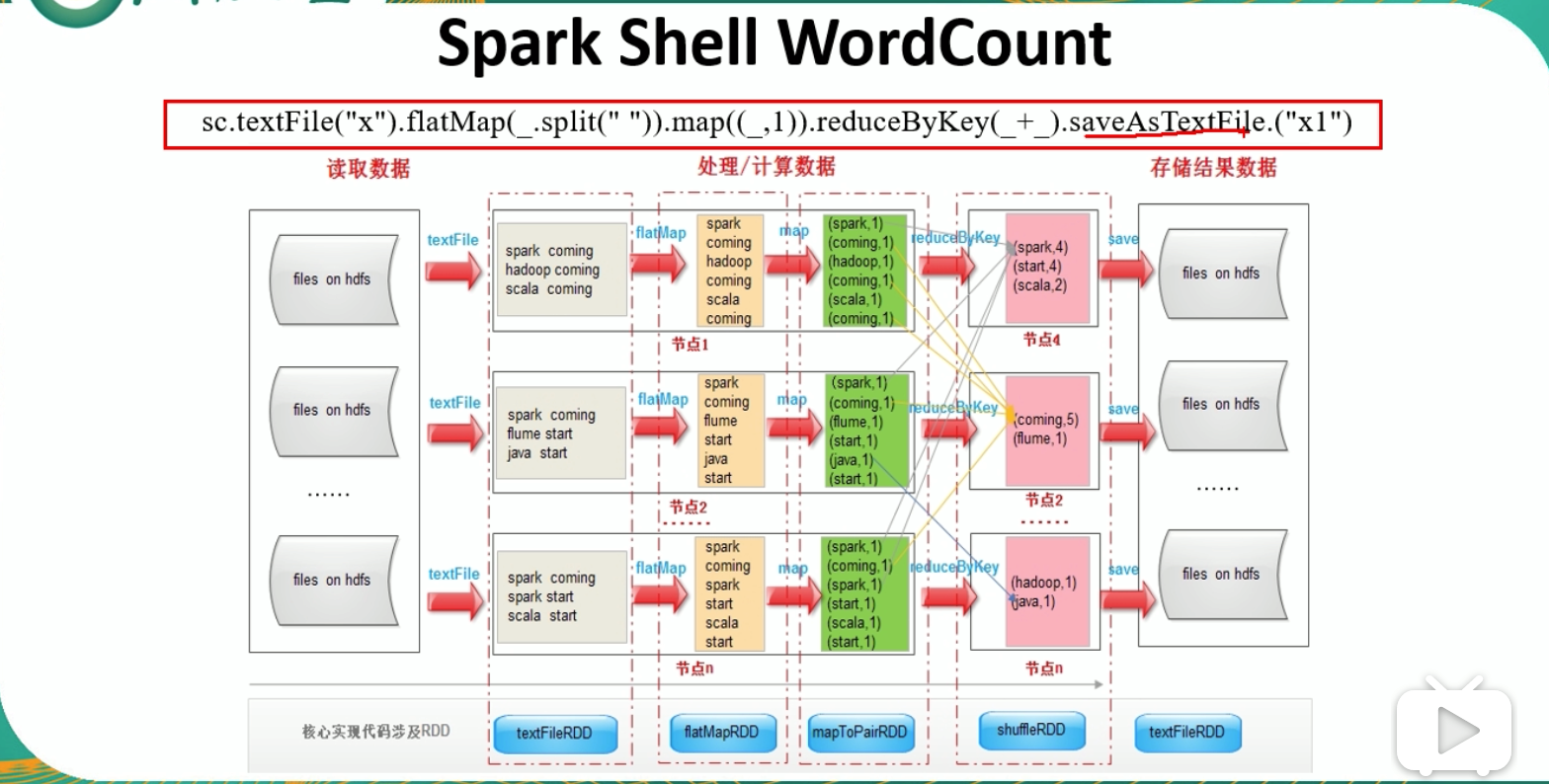
1.6 Spark Shell WordCount 流程
sc.textFile("文件地址").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).saveAsTextFile.("输出结果")
1.6 Eclipse 编写 WordCount 程序
// ===== 1. 创建 Maven Project
// ===== 2. 导入依赖 pom.xml
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.3</version>
</dependency>
</dependencies>
<build>
<finalName>WordCount</finalName>
<plugins>
<!--java 的编译版本 1.8-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.17</version>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>test-compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<archive>
<manifest>
<mainClass>com.noodles.WordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>jar-with-dependencies</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
// ===== 3. 创建 Maven Module
// ===== 4. 创建 Scala Class: WordCount
object WordCount {
def main(args:Array[String]): Unit = {
// 1. 创建配置信息
val conf = new SparkConf().setAppName("wc")
// 2. 创建 sparkcontext
val sc = new SparkContext(conf)
// 3. 处理逻辑
// 读取数据
val lines = sc.textFile(args(0))
val words = lines.flatMap(_.split(" "))
val k2v = words.map((_, 1))
val result = k2v.reduceByKey(_+_)
// 输出
// result.collect()
// 将输出结果保存到文件
result.saveAsTextFile(args(1))
// 4. 关闭连接
sc.stop()
}
}
**参考资料:**
- [spark-2.1.3-bin-hadoop2.7.tgz下载](https://archive.apache.org/dist/spark/spark-2.1.3/)
- [eclipse的maven、Scala环境搭建](https://blog.csdn.net/u014353787/article/details/50166789)
Spark 基础操作的更多相关文章
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- List基础操作
/** * List基础操作 * Created by zhen on 2018/11/14. */ object ListDemo { def main(args: Array[String]) { ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- 【一】Spark基础
Spark基础 什么是spark 也是一个分布式的并行计算框架 spark是下一代的map-reduce,扩展了mr的数据处理流程. Spark架构原理图解 RDD[Resilient Distrib ...
- Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作 8.1. 有类型操作 8.2. 无类型转换 8.5. Column 对象 9. 缺失值处理 10. 聚合 11. 连接 8. Dataset ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
- StructuredStreaming基础操作和窗口操作
一.流式DataFrames/Datasets的结构类型推断与划分 ◆ 默认情况下,基于文件源的结构化流要求必须指定schema,这种限制确保即 使在失败的情况下也会使用一致的模式来进行流查询. ◆ ...
- python基础操作以及hdfs操作
目录 前言 基础操作 hdfs操作 总结 一.前言 作为一个全栈工程师,必须要熟练掌握各种语言...HelloWorld.最近就被"逼着"走向了python开发之路, ...
- MYSQL基础操作
MYSQL基础操作 [TOC] 1.基本定义 1.1.关系型数据库系统 关系型数据库系统是建立在关系模型上的数据库系统 什么是关系模型呢? 1.数据结构可以规定,同类数据结构一致,就是一个二维的表格 ...
随机推荐
- 在Modelsim中使用dsp 48e进行仿真
在Modelsim中使用DSP 48E仿真时,需要用到glbl模块,它的调用方法如下所示: vlog -incr GND.v VCC.v FDRE.v DSP48E.vvlog -incr glbl. ...
- org.apache.ibatis.cache.CacheException: Error serializing object
异常: 十二月 26, 2017 3:38:05 下午 org.apache.jasper.servlet.TldScanner scanJars 信息: At least one JAR was s ...
- django celery 异步执行任务遇到的坑
部署后,任务没有持久化,所有用supervisor 进行进程管理 安装 pip install supervisor 创建 配置文件 [program:testplatform-flower] com ...
- webpack4-用之初体验
众所周知,webpack进入第4个大版本已经有2个月的时间了,而且webpack团队升级更新的速度也是非常的惊人 在写下如下内容的时候webpack已经出到了4.6的版本了,剑指5.0应该是指日可待了 ...
- Mac和window生成ssh和查看ssh key
一.MAC系统 mac 系统开始就已经为我们安装了ssh 如果没有安装,首先安装 打开终端:$ ssh -v 查看ssh版本 OpenSSH_6.2p2, OSSLShim 0.9.8r 8 Dec ...
- [转]MyEclipse基础学习:Java EE Learning Center
我就不翻译了,直接给出Java EE学习中心的原文链接: Java EE Learning Center 另外,给出MyEclipse IDE 环境中Apache Tomcat server服务器正常 ...
- 乌龙茶生产过程中挥发性成分吲哚的形成 | Formation of Volatile Tea Constituent Indole During the Oolong Tea Manufacturing Process
吲哚是啥?在茶叶成分中的地位?乌龙茶?香气,重要的前体,比如色氨酸Trp.IAA. Indole is a characteristic volatile constituent in oolong ...
- Java 什么是静态内部类
#定义 Java语言允许在类中再定义类,这种在其它类内部定义的类就叫内部类. 有static关键字修饰的内部类. 比如:Pattern类中的Node类. public class Outer { pr ...
- 蓝牙BLE: GATT Profile 简介(GATT 与 GAP)
一. 引言 现在低功耗蓝牙(BLE)连接都是建立在 GATT (Generic Attribute Profile) 协议之上.GATT 是一个在蓝牙连接之上的发送和接收很短的数据段的通用规范,这些很 ...
- Alibaba Java Diagnostic Tool Arthas/Alibaba Java诊断利器Arthas
Arthas 用户文档 — Arthas 3.1.0 文档https://alibaba.github.io/arthas/ alibaba/arthas: Alibaba Java Diagnost ...