Kafka 通过python简单的生产消费实现
使用CentOS6.5、python3.6、kafkaScala 2.10 - kafka_2.10-0.8.2.2.tgz (asc, md5)
一、下载kafka
下载地址
https://kafka.apache.org/downloads
里面包含zookeeper
二、安装Kafka
1、安装zookeeper
mkdir /root/kafka/
tar -vzxf kafka_2.10-0.8.2.2

cd /root/kafka/kafka_2.10-0.8.2.2
cat config/zookeeper.properties | grep -v '#' >> config/zk.properties
mkdir -p /home/kafka/zk
vi zk.properties
dataDir=/home/kafka/zk #因为zookeeper变更为zk,所以需要在这里修改一下
启动zookeeper(后台启动)
/root/kafka/kafka_2.10-0.8.2.2/bin/zookeeper-server-start.sh /root/kafka/kafka_2.10-0.8.2.2/config/zk.properties &
2、安装Kafka
cd /root/kafka/kafka_2.10-0.8.2.2
cat config/server.properties | grep -v '#' >> config/kafka_01.properties
启动Kafka(后台启动)
/root/kafka/kafka_2.10-0.8.2.2/bin/kafka-server-start.sh /root/kafka/kafka_2.10-0.8.2.2/config/kafka_01.properties &
三、新建Kafka topic
1、新建topic
cd /root/kafka/kafka_2.10-0.8.2.2
./bin/kafka-topics.sh --create --zookeeper 192.168.50.33:2181 --replication-factor 1 --partitions 1 --topic test
2、查看topic
./bin/kafka-topics.sh --list --zookeeper 192.168.50.33:2181
四、kafka生产者脚本
1、安装python的Kafka模块
pip3 install kafka-python(之前已安装)

2、kafka生产者脚本
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
import time
'''
使用kafka的生产模块
'''
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.producer = KafkaProducer(bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort
))
try:
parmas_message = json.dumps(params)
producer = self.producer
producer.send(self.kafkatopic, parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
print(e)
'''
测试consumer和producer
:return:
'''
# 测试生产模块
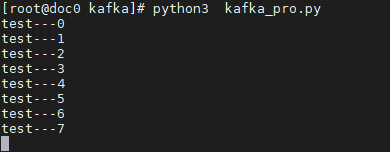
producer = Kafka_producer("127.0.0.1",9092,"test")
for i in range(1000000000000):
params = 'test---' + str(i)
print(params)
producer.sendjsondata(params)
time.sleep(1)
main()
import os
print(os.uname)
五、kafka消费者脚本
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
import time
'''
使用Kafka—python的消费模块
'''
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.consumer = KafkaConsumer(self.kafkatopic, group_id=self.groupid,
bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort))
try:
for message in self.consumer:
# print json.loads(message.value)
yield message
except KeyboardInterrupt as e:
print(e)
'''
测试consumer和producer
:return:
'''
# 测试消费模块
# 消费模块的返回格式为ConsumerRecord(topic=u'ranktest', partition=0, offset=202, timestamp=None,
# \timestamp_type=None, key=None, value='"{abetst}:{null}---0"', checksum=-1868164195,
# \serialized_key_size=-1, serialized_value_size=21)
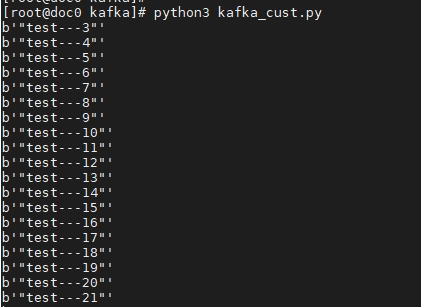
consumer = Kafka_consumer('127.0.0.1',
9092,
"test",
'test-python-test')
message = consumer.consume_data()
for i in message:
print(i.value)
main()
Kafka 通过python简单的生产消费实现的更多相关文章
- Python并发编程-生产消费模型
生产消费模型初步 #产生两个子进程,Queue可以在子进程之间传递消息 from multiprocessing import Queue,Process import random import t ...
- Kafka(三)Kafka的高可用与生产消费过程解析
一 Kafka HA设计解析 1.1 为何需要Replication 在Kafka在0.8以前的版本中,是没有Replication的,一旦某一个Broker宕机,则其上所有的Partition数据 ...
- Kafka创建&查看topic,生产&消费指定topic消息
启动zookeeper和Kafka之后,进入kafka目录(安装/启动kafka参考前面一章:https://www.cnblogs.com/cici20166/p/9425613.html) 1.创 ...
- 【Apache Kafka】二、Kafka安装及简单示例
(一)Apache Kafka安装 1.安装环境与前提条件 安装环境:Ubuntu16.04 前提条件: ubuntu系统下安装好jdk 1.8以上版本,正确配置环境变量 ubuntu系统下安 ...
- kafka生产消费原理笔记
一.什么是kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性 ...
- kafka之三:kafka java 生产消费程序demo示例
kafka是吞吐量巨大的一个消息系统,它是用scala写的,和普通的消息的生产消费还有所不同,写了个demo程序供大家参考.kafka的安装请参考官方文档. 首先我们需要新建一个maven项目,然后在 ...
- 【java并发编程】Lock & Condition 协调同步生产消费
一.协调生产/消费的需求 本文内容主要想向大家介绍一下Lock结合Condition的使用方法,为了更好的理解Lock锁与Condition锁信号,我们来手写一个ArrayBlockingQueue. ...
- Python 简单入门指北(二)
Python 简单入门指北(二) 2 函数 2.1 函数是一等公民 一等公民指的是 Python 的函数能够动态创建,能赋值给别的变量,能作为参传给函数,也能作为函数的返回值.总而言之,函数和普通变量 ...
- Kafka实战-简单示例
1.概述 上一篇博客<Kafka实战-Kafka Cluster>中,为大家介绍了Kafka集群的安装部署,以及对Kafka集群Producer/Consumer.HA等做了相关测试,今天 ...
随机推荐
- Python知识点图片
- 微信H5页面前端开发,大多数人都会遇到的几个兼容性坑
最近给公司微信公众号,写了微信h5业务页面,总结分享一下前端开发过程中的几个兼容性坑,项目直接拿的公司页面,所以下文涉及图片都模糊处理了. 1.ios端兼容input光标高度 问题详情描述:input ...
- dubbo中使用动态代理
dubbo的动态代理也是只能代理接口 源码入口在JavassistProxyFactory中 public class JavassistProxyFactory extends AbstractPr ...
- get merge --no-ff和git merge区别、git fetch和git pull的区别
get merge --no-ff和git merge区别 git merge -–no-ff可以保存你之前的分支历史.能够更好的查看 merge历史,以及branch 状态. git merge则不 ...
- python多线程爬取世纪佳缘女生资料并简单数据分析
一. 目标 作为一只万年单身狗,一直很好奇女生找对象的时候都在想啥呢,这事也不好意思直接问身边的女生,不然别人还以为你要跟她表白啥的,况且工科出身的自己本来接触的女生就少,即使是挨个问遍,样本量也 ...
- ADO.NET 四(DataReader)
DataReader 类概述 DataReader 类对应MSSQLSERVER在 System.Data.SqlClient 命名空间中,对应的类是 SqlDataReader,主要用于读取表中的查 ...
- C# Java的加密的各种折腾
24位加密 Java public class DESUtil { private static final String KEY_ALGORITHM = "DESede"; pr ...
- JS中BOM和DOM常用的事件
总结:window对象 ● window.innerHeight - 浏览器窗口的内部高度 ● window.innerWidth - 浏览器窗口的内部宽度 ● window.open() - 打开新 ...
- PHP/Python---百钱百鸡简单实现及优化
公鸡5块钱一只,母鸡3块钱一只,小鸡一块钱3只,用100块钱买一百只鸡,问公鸡,母鸡,小鸡各要买多少只? 今天看到这题很简单 ,但是随手写出来后发现不是最优的
- UGUI image
1.创建UI->image 如何将图片在导入到场景中:将图片资源导入unity后,找到要导入的图片,将Texture Type改为“Sprite(2D and UI)”精灵模式,然后点击Appl ...