URI与URL详解
URL 与 URI
很多人会混淆这两个名词。
URL:(Uniform/Universal Resource Locator 的缩写,统一资源定位符)。
URI:(Uniform Resource Identifier 的缩写,统一资源标识符)(代表一种标准)。
关系:
URI 属于 URL 更高层次的抽象,一种字符串文本标准。
就是说,URI 属于父类,而 URL 属于 URI 的子类。URL 是 URI 的一个子集。
二者的区别在于,URI 表示请求服务器的路径,定义这么一个资源。而 URL 同时说明要如何访问这个资源(http://)。
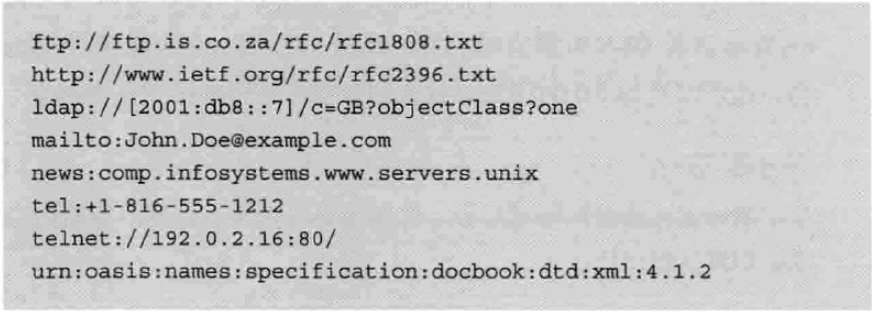

URI 示例
大家把浏览器地址栏里访问网站的地址认为是URL就好了,也就是以HTTP/HTTPS开头的URI子集。
端口 与 URL标准格式
何为端口?端口(Port),相当于一种数据的传输通道。用于接受某些数据,然后传输给相应的服务,而电脑将这些数据处理后,再将相应的回复通过开启的端口传给对方。
端口的作用:因为 IP 地址与网络服务的关系是一对多的关系。所以实际上因特网上是通过 IP 地址加上端口号来区分不同的服务的。
端口是通过端口号来标记的,端口号只有整数,范围是从0 到65535。
URL 标准格式
通常而言,我们所熟悉的 URL 的常见定义格式为:
scheme://host[:port#]/path/.../[;url-params][?query-string][#anchor]
scheme //有我们很熟悉的http、https、ftp以及著名的ed2k,迅雷的thunder等。
host //HTTP服务器的IP地址或者域名
port# //HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如tomcat的默认端口是8080 http://localhost:8080/
path //访问资源的路径
url-params //所带参数
query-string //发送给http服务器的数据
anchor //锚点定位
Java中对URI的操作类
@Test
public void uriTest() throws Exception{
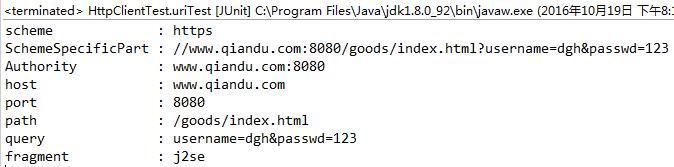
URI uri = new URI("https://www.qiandu.com:8080/goods/index.html?username=dgh&passwd=123#j2se");
System.out.println("scheme : " + uri.getScheme());
System.out.println("SchemeSpecificPart : " + uri.getSchemeSpecificPart());
System.out.println("Authority : " + uri.getAuthority());
System.out.println("host : " + uri.getHost());
System.out.println("port : " + uri.getPort());
System.out.println("path : " + uri.getPath());
System.out.println("query : " + uri.getQuery());
System.out.println("fragment : " + uri.getFragment());
}
运行上面的代码,然后得到如下的结果:
 Java中对URL的操作
Java中对URL的操作
@Test
public void urlTest() throws Exception{
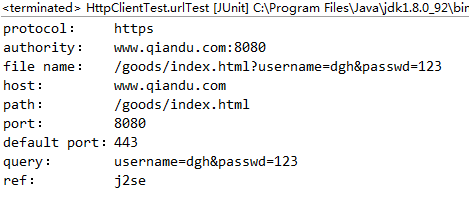
URL url = new URL("https://www.qiandu.com:8080/goods/index.html?username=dgh&passwd=123#j2se");
System.out.println("URL: " + url.toString());
System.out.println("protocol: " + url.getProtocol());
System.out.println("authority: " + url.getAuthority());
System.out.println("file name: " + url.getFile());
System.out.println("host: " + url.getHost());
System.out.println("path: " + url.getPath());
System.out.println("port: " + url.getPort());
System.out.println("default port:" + url.getDefaultPort());
System.out.println("query: " + url.getQuery());
System.out.println("ref: " + url.getRef());
}
运行上面的代码,得到以下结果:
 UserInfo属性
UserInfo属性
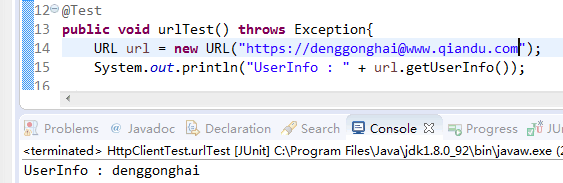
其实关于资源定位的时候还有一种写法,就是类似于sftp://tomcat@www.qiandu.com///app/index.pdf就是在主机名前面有类似于xxx@的东西,其实这种表示就:用户@主机名或者用户@IP。@前面表示登录主机的用户,也就是UserInfo了。
URI与URL详解的更多相关文章
- 基础篇-http协议《http 简介、url详解、request》
目录 一.http 简介 二.url 详解 三.request 1.get 和 post 2.请求方法 3.request 组成 4.请求头 5.get 请求参数 6.post 请求参数 7.post ...
- Fiddler抓包6-get请求(url详解)
前言 上一篇介绍了Composer的功能,可以模拟get和post请求,get请求有些是不带参数的,这种比较容易,直接放到url地址栏就行.有些get请求会带有参数,本篇详细介绍url地址格式. 一. ...
- Fiddler抓包6-get请求(url详解)【转载】
本篇转自博客:上海-悠悠 原文地址:http://www.cnblogs.com/yoyoketang/tag/fiddler/ 前言 上一篇介绍了Composer的功能,可以模拟get和post请求 ...
- 3、get请求(url详解)
前言 上一篇介绍了Composer的功能,可以模拟get和post请求,get请求有些是不带参数的,这种比较容易,直接放到url地址栏就行.有些get请求会带有参数,本篇详细介绍url地址格式. 一. ...
- URI与URN与URL详解
当没有URI时 什么是URI和URN和URL URI详解 Uniform Resource Identifier 统一资源标识符 URI的组成 案例: https://tools.ietf.org/h ...
- 【基础进阶】URL详解与URL编码
作为前端,每日与 URL 打交道是必不可少的.但是也许每天只是单纯的用,对其只是一知半解,随着工作的展开,我发现在日常抓包调试,接口调用,浏览器兼容等许多方面,不深入去理解URL与URL编码则会踩到很 ...
- URL详解与URL编码
作为前端,每日与 URL 打交道是必不可少的.但是也许每天只是单纯的用,对其只是一知半解,随着工作的展开,我发现在日常抓包调试,接口调用,浏览器兼容等许多方面,不深入去理解URL与URL编码则会踩到很 ...
- HTTP协议之url详解
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接.URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息 URL,全称是U ...
- URL详解
浏览器因特网资源:URL是浏览器寻找信息时所需的资源位置,通过URL,应用程序才能找到并使用共享因特网上大量的数据资源. 大部分URL都遵循一种标准的格式: ①HTTP协议(http://或者http ...
随机推荐
- 读《PMI 分析手册》
目录 读<PMI 分析手册> 官方 PMI 基本概况 官方制造业 PMI 官方非制造业 PMI 综合 PMI 产出指数 PMI 分析框架 PMI 与经济周期 官方 PMI 分析 参考研报 ...
- excel绘制多列 其中一列作为横坐标 ; 数值拟合
excel绘制多列,其中最左列作为横纵坐标: 选中很多列,然后,,点击菜单栏的“插入”->“图标” -->在弹出的“插入图表”对话框中选择“X Y(散点图)”,默认是条形图. 左边的列会 ...
- 转载:Linux命令行快捷键
常用 Ctrl + 左右键:在单词之间跳转 Ctrl + A:跳到本行的行首 Ctrl + E:跳到页尾 Ctrl + U:删除当前光标前面的所有文字(还有剪切功能) Ctrl + K:删除当前光标后 ...
- [转帖]进程状态的转换与PCB详解
进程状态的转换与PCB详解 https://blog.csdn.net/qq_34666857/article/details/102852747 挺好的 之前没好好学习. 返回主目录 之前的 ...
- 概率dp - Uva 10900 So you want to be a 2n-aire?
So you want to be a 2n-aire? Problem's Link Mean: 玩一个答题赢奖金的游戏,一开始有1块钱,玩n次,每次赢的概率为t~1之间的某个实数. 给定n和t,求 ...
- Sitecore 8.2 防火墙规则的权威指南
如今,使用多层安全保护您的数据不再是奢侈品; 这是不容谈判的.此外,您需要确保Sitecore解决方案保持运行并与集成服务(例如SQL,Mongo,Solr)通信,同时保持相同的安全级别. 让我们假设 ...
- Python做一个计时器的动画
一.问题在做连连看的时候需要加一个计时器的动画,这样就完成了计时功能的设计. 二.解决主要思路: 1.先产生一个画布,用深颜色填充满. 2.产生一个新的矩阵用来覆盖画布,背景用白色,就可以渲染出来递减 ...
- 计算标准差——Python
计算标准差 题目描述: 编写一个函数计算一系列数的标准差. ...
- c#winform简单实现Mysql数据库的增删改查的语句
通过简单的SQL语句实现对数据库的增删改查. 窗口如下: 定义打开与关闭连接函数,方便每次调用: 增加指令: 删除指令: 修改指令: 查找指令: 表格情况:
- [Windows] - DNS防污染工具Pcap_DNSProxy
最近试过非常多的DNS防污染工具(包括:dnsforwarder.dnsforwarder.dnscrypt-proxy.SimpleDNSCrypt等),感觉这个Pcap_DNSProxy简单.快捷 ...