Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition
Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition
ICCV 2019 (oral)
2019-08-01 15:08:19
Paper:https://arxiv.org/abs/1907.13369
1. Backgroud and Motivation:
本文提出一种基于多智能体强化学习的未裁剪视频识别模型,来自适应的从未裁剪视频中,截取出样本视频帧进行行为识别。具体的示意图如下所示:
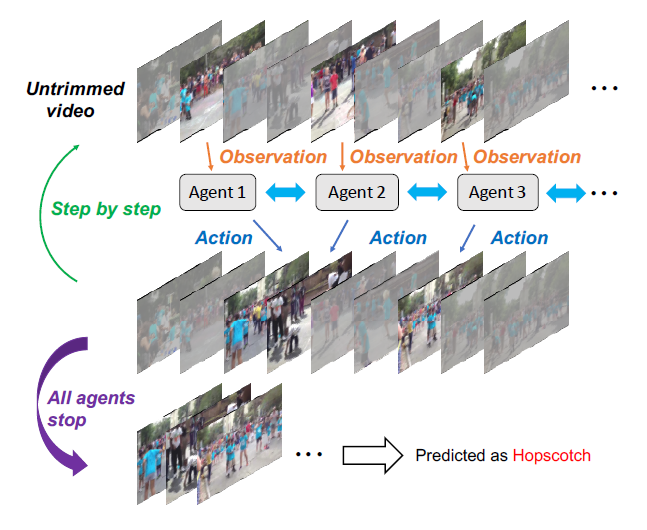
2. Architecture
2.1 Context-aware Observation Network:
这个 context-aware observation network 是一个基础的观测网络,随后是 context network。这个基础的观测网络是用于编码 选中的视频帧的视频信息,输出为 feature vector,作为 context network 的输入。与 single-agent 系统不同的是,multi-agent 的系统,每一个智能体的选择不仅依赖于 local environment state,而且受到 context information 的影响。所以,我们设计了一个 context-aware module,来维持一个 joint internal state of agents,用一个 RNN 网络将 history context information 进行总结。为了能够使之更加有效的工作,每一个智能体 only accesses context information from its 2M neighboring agents but not from all agents. 正式的来说,所有的时间步骤 t,智能体 a 观测到一个组合的状态 $s_t^a$ 及其 之前的 hidden state $h_{t-1}^a$ 作为 context module 的输入,然后产生其当前的 hidden states:

2.2 Policy Network:
作者采用 fc + softmax function 作为 policy network。在每一个时间步骤 t,每一个智能体 a,根据策略网络产生的概率分布, 选择一个动作 $u_t^a$ 来执行。动作集合是一个离散的空间 {moving ahead, moving back and staying}。并且设置一定的步幅。当所有的智能体都选择 staying 的时候,意味着该停止了。
2.3 Classification Network:
就是将选中的视频帧进行 action 的分类。
3. Objectives
本文将同时进行 奖励最大化的优化 以及 分类网络的优化。
3.1 MARL Objective:
Reward function: 奖励函数反应了 agents 选择动作的好坏。当所有的智能体都选择动作时,每一个时刻 t,每一个智能体基于分类的概率 $p_t^a$ 得到了其各自的奖励 $r_t^a$ 。给予 agent 奖励可以促使其知道更加具有信息量的 frame,从而一步一步的改善正确预测的概率。所以,作者设计了一个简单的奖励函数,鼓励模型增加其 confidence。特定的,对于第 t 个时间步骤来说,agent a 接收的奖励按照如下的方式进行计算:
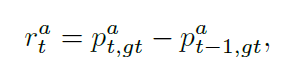
其中,$p_{t,c}^a$ 代表了智能体 a 在时刻 t 模型将其预测为 class c 的概率,gt 是视频的 ground truth label。所有的智能体共享同一个 reward function。考虑到序列决策的场景,考虑累积折扣回报是更加合适的,即:将来的奖励对当前的步骤贡献更小一些。特别的,在时刻 t,对于智能体 a 来说,折扣的回报可以计算如下:
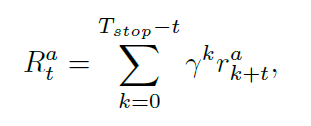
Policy Gradient: 服从 REINFORCE 算法,作者将目标函数设置为:
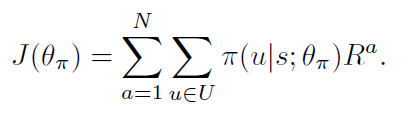
在本文的情况下,学习网络参数使其可以最大化上述公式,其梯度为:
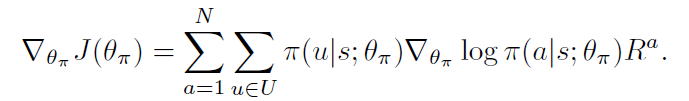
这变成了一个 non-trivial optimization problem, 由于 action sequence space 的维度过高。REINFORCE 通过蒙特卡洛采样的方式,进行梯度的估计:
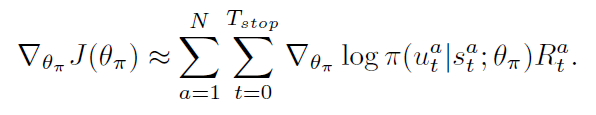
然后,我们可以利用随机梯度下降的方式,来最小化下面的损失:
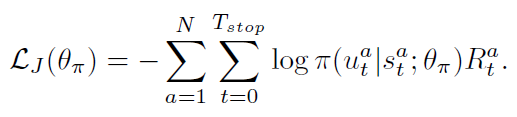
Maximum entropy:
为了避免让策略迅速变的 deterministic,研究者考虑将 entropy regularization 技术引入到 DRL 算法中,以鼓励探索。更大的熵,agent 就会更加偏向于探索其他动作。所以,我们利用 policy 的 entropy 来进行正则:
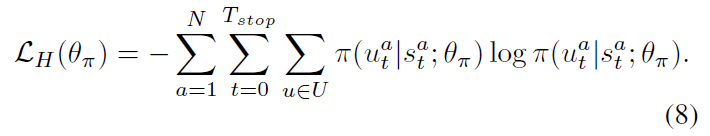
所以,MARL 总得损失是上述两个损失函数的加和:
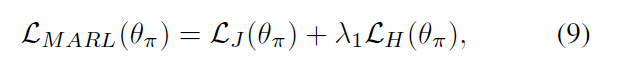
3.2 Classification Objective :
作者用 Cross-entropy loss 来最小化 gt 和 prediction p 之间的 KL-散度:
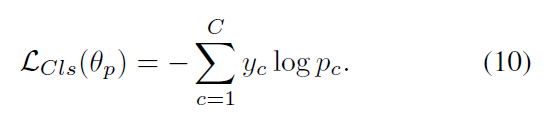
最终,我们优化组合损失,即:
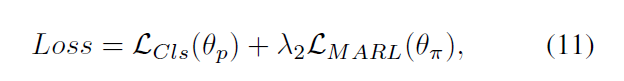
4. Experiments:


==
Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition的更多相关文章
- [转]Deep Reinforcement Learning Based Trading Application at JP Morgan Chase
Deep Reinforcement Learning Based Trading Application at JP Morgan Chase https://medium.com/@ranko.m ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
- (zhuan) Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Evolution Strategies as a Scalable Alternative to Reinforcement Learning this blog from: https://blo ...
随机推荐
- Github强制找回管理员账号密码
步骤: 1. 登录Github所在的服务器,切换用户为git:su git 2. 进入Github的Rails控制台:gitlab-rails console production 3. 查看超级管理 ...
- Clickhouse高可用配置总结
1. 简述 Clickhouse默认是多分片单副本集群,分布式表的配置是每个分片只有一份,如果某个节点挂掉的话,则会直接导致写入或查询异常:Clickhouse是具有高可用特性的,即每个分片具有2个或 ...
- [转]sqlserver判断字符串是否是数字
sql2005有个函数ISNUMERIC(expression)函数:当expression为数字时,返回1,否则返回0.这只是一个菜鸟级的解决办法,大多数情况比较奏效. eg: 1 select I ...
- Kotlin反射实践操作详解
继续对反射进行实战. 获取构造方法: 先定义一个主构造方法,2个次构造方法,接下来咱们用反射来获取一下构造方法: 其结果: [fun <init>(kotlin.Int, kotlin.S ...
- vs code c/c++编程配置文件
之前的C语言课程老师只讲了C没有接触C++,但是觉得C++挺重要的,而且python和java再去转exe有点麻烦,所以还是学一下C++. 问过朋友推荐了几个IDE,最后他用的是visual stud ...
- 微信小程序~下拉刷新PullDownRefresh
一.onPullDownRefresh回调 代码: // http://itlao5.com onPullDownRefresh: function () { console.log('onPul ...
- 《exception》第九次团队作业:Beta冲刺与验收准备(大结局)
一.项目基本介绍 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 Exception 作业学习目标 1.掌握软件黑盒测试技术:2.学会编制软件项目 ...
- ZOJ - 3157:Weapon (几何 逆序对)
pro:给定平面上N条直线,保证没有直线和Y轴平行. 求有多少交点的X坐标落在(L,R)开区间之间,注意在x=L或者R处的不算. sol:求出每条直线与L和R的交点,如果A直线和B直线在(L,R)相交 ...
- if语句的嵌套:从键盘输入3个实数,求其最大值。
#include<stdio.h>void main(){ float a,b,c,max; scanf("%f%f%f",&a,&b,&c); ...
- [Javascript] Sort by multi factors
For example, we have a 2D arrays; const arys = [ [], [], [] ]; We want to sort by the number first, ...