XPath库详解
xpath入门
在上次我详细的讲了一下什么是xpath,具体了解可以先看下面这篇博客:https://www.cnblogs.com/yanjiayi098-001/p/12009963.html
使用xpath之前先安装lxml库
pip install lxml
先看一段简单的示例:
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first</a></li>
<li class="item-1"><a href="link2.html">second</a>
<li class="item-2"><a href="link3.html">third</li>
<li class="item-3"><a href="link4.html">fourth</a></li>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('utf-8'))
注意查看代码中的html片段,第二个li没有闭合,第三个li的a标签没有闭合
查看结果:
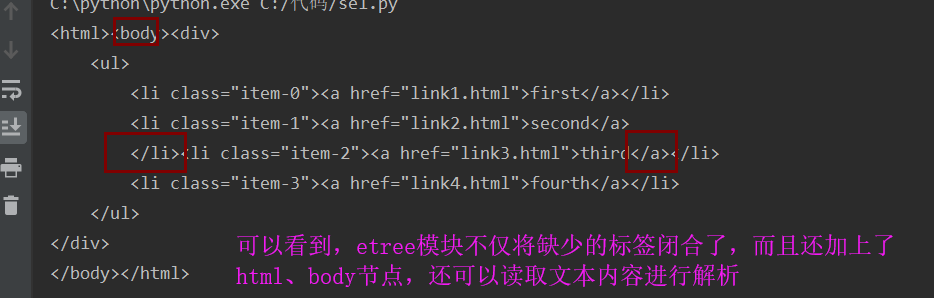
新建 hello.html
<div>
<ul>
<li class="item-0"><a href="link1.html">first</a></li>
<li class="item-1"><a href="link2.html">second</a></li>
<li class="item-2"><a href="link3.html">third</a></li>
<li class="item-3"><a href="link4.html">fourth</a></li>
</ul>
</div>
.py文件
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))
结果:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first</a></li>
<li class="item-1"><a href="link2.html">second</a></li>
<li class="item-2"><a href="link3.html">third</a></li>
<li class="item-3"><a href="link4.html">fourth</a></li>
</ul>
</div>
</body></html>
获取节点
获取所有节点
//*表示匹配所有节点
html = etree.parse('./hello.html', etree.HTMLParser())
result = html.xpath('//*')
print(result)
结果:
[<Element html at 0x252593df0c8>, <Element head at 0x252596a7c88>, <Element meta at 0x252596a7cc8>, <Element title at 0x252596a7d48>, <Element body at 0x252596a7f48>, <Element div at 0x252596b40c8>, <Element ul at 0x252596b4148>, <Element li at 0x252596b4188>, <Element a at 0x252596b41c8>, <Element li at 0x252596b4088>, <Element a at 0x252596b4208>, <Element li at 0x252596b4248>, <Element a at 0x252596b4288>, <Element li at 0x252596b42c8>, <Element a at 0x252596b4308>]
匹配指定节点,如获取所有li节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li')
print(result) # 所有li节点
print(result[0]) # 第一个li节点
结果:
[<Element li at 0x29d8c7f7bc8>, <Element li at 0x29d8c7f7c08>, <Element li at 0x29d8c7f7c88>, <Element li at 0x29d8c7f7f88>]
<Element li at 0x29d8c7f7bc8>
获取子节点
/表示匹配子节点
获取li节点的直接子节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a') # 获取所有li节点的直接子节点a
print(result)
结果:
[<Element a at 0x2305cda7c88>, <Element a at 0x2305cda7cc8>, <Element a at 0x2305cda7d48>, <Element a at 0x2305cda7f48>]
改成 // 可以这么写:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//div//a') # 获取div的所有后代a节点
print(result)
获取父节点
..表示匹配父节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
# 获取href属性为link2.html的a标签的父节点的class名
result = html.xpath('//a[@href="link2.html"]/../@class')
print(result)
# ['item-1'] #结果
属性匹配
@表示匹配属性
根据属性值匹配节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
# 获取属性class值为item-0的li
result = html.xpath('//li[@class="item-0"]')
print(result)
# [<Element li at 0x2aa50947cc8>]
属性多值匹配
使用contains函数匹配

可以看出 contains函数表示意思是,第一个参数字符串包含第二个参数时,返回true
实际用起来可能会有点差异(由于结合了路径表达式和属性)
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="li"]/a/text()')
print(result)
# []
result = html.xpath('//li[contains(@class, "li")]/a/text()')
##选取class属性包含字符串"li"的节点
print(result)
# ['first item']
多属性匹配
需要匹配满足多个属性的节点,使用 and 运算符
from lxml import etree
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
# 通过class和name两个属性进行匹配
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result)
# ['first item']
文本获取
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
# 获取属性class值为item-0的li的子节点a的文本内容
result = html.xpath('//li[@class="item-0"]/a/text()')
print(result)
# ['first']
如果想要获取后代节点内部的所有文本,使用 //text()
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
# 获取所有li的后代节点中的文本
result = html.xpath('//li//text()')
print(result)
# ['first', 'second', 'third', 'fourth']
按序选择
根据节点所在的顺序进行提取
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
# 按索引排序
result = html.xpath('//li[1]/a/text()')
print(result)
# ['first']
# last 最后一个
result = html.xpath('//li[last()]/a/text()')
print(result)
# ['fourth']
# position 位置查找
result = html.xpath('//li[position()<3]/a/text()')
print(result)
# ['first', 'second']
# - 运算符
result = html.xpath('//li[last()-2]/a/text()')
print(result)
# ['second']
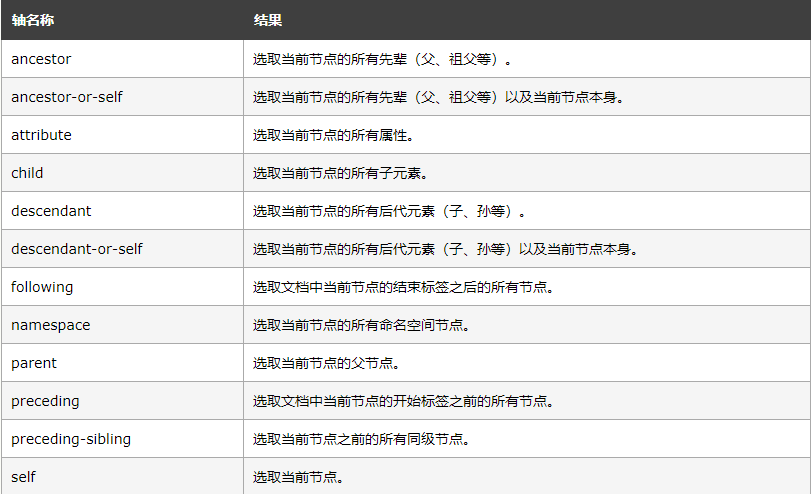
节点轴选择
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
# 所有祖先节点
result = html.xpath('//li[1]/ancestor::*')
print(result)
# [<Element html at 0x106e4be88>, <Element body at 0x106e4bf88>, <Element div at 0x106e4bfc8>, <Element ul at 0x106e6f048>]
# 祖先节点中的div
result = html.xpath('//li[1]/ancestor::div')
print(result)
# [<Element div at 0x106ce4fc8>]
# 第一个节点的所有属性
result = html.xpath('//li[1]/attribute::*')
print(result)
# ['item-0']
# 子节点
result = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(result)
# [<Element a at 0x107941fc8>]
# 后代节点中的a
result = html.xpath('//li[1]/descendant::a')
print(result)
# [<Element a at 0x10eeb7fc8>]
# 该节点后面所有节点中的第2个 从1开始计数
result = html.xpath('//li[1]/following::*[2]')
print(result)
# [<Element a at 0x10f188f88>]
# 该节点后面的所有兄弟节点
result = html.xpath('//li[1]/following-sibling::*')
print(result)
# [<Element li at 0x104b7f048>, <Element li at 0x104b7f088>, <Element li at 0x104b7f0c8>]
补充
xpath的运算符介绍

xpath轴
XPath库详解的更多相关文章
- Lua的协程和协程库详解
我们首先介绍一下什么是协程.然后详细介绍一下coroutine库,然后介绍一下协程的简单用法,最后介绍一下协程的复杂用法. 一.协程是什么? (1)线程 首先复习一下多线程.我们都知道线程——Thre ...
- Python--urllib3库详解1
Python--urllib3库详解1 Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3.Urllib3提供了很多pyt ...
- Struts标签库详解【3】
struts2标签库详解 要在jsp中使用Struts2的标志,先要指明标志的引入.通过jsp的代码的顶部加入以下的代码: <%@taglib prefix="s" uri= ...
- STM32固件库详解
STM32固件库详解 emouse原创文章,转载请注明出处http://www.cnblogs.com/emouse/ 应部分网友要求,最新加入固件库以及开发环境使用入门视频教程,同时提供例程模板 ...
- MySQL5.6的4个自带库详解
MySQL5.6的4个自带库详解 1.information_schema详细介绍: information_schema数据库是MySQL自带的,它提供了访问数据库元数据的方式.什么是元数据呢?元数 ...
- php中的PDO函数库详解
PHP中的PDO函数库详解 PDO是一个“数据库访问抽象层”,作用是统一各种数据库的访问接口,与mysql和mysqli的函数库相比,PDO让跨数据库的使用更具有亲和力:与ADODB和MDB2相比,P ...
- STM32 HAL库详解 及 手动移植
源: STM32 HAL库详解 及 手动移植
- 爬虫入门之urllib库详解(二)
爬虫入门之urllib库详解(二) 1 urllib模块 urllib模块是一个运用于URL的包 urllib.request用于访问和读取URLS urllib.error包括了所有urllib.r ...
- Python爬虫系列-Urllib库详解
Urllib库详解 Python内置的Http请求库: * urllib.request 请求模块 * urllib.error 异常处理模块 * urllib.parse url解析模块 * url ...
随机推荐
- Java三大特征--多态
1.定义 允许不同类的对象对同一消息做出响应,即同一消息可以根据发送对象的不同而采用多种不同的行为方式. 2.存在条件 2.1存在继承关系 2.2子类重写了父类方法 2.3父类类型的变量指向子类对象的 ...
- python 获取主机名称和ip地址
python2.7 #!/usr/bin/env python # Python Network Programming Cookbook -- Chapter - # This program is ...
- 八、linux文件系统上的特殊权限 SUID 、GUID、Sticky
安全上下文 前提:进程有属主和属组,文件有属主和属组 任何一个可执行程序文件能不能启动为进程:取决发起者对程序文件是否拥有执行权限 启动为进程之后,其进程的属主为发起者:进程的属组为发起者所属的组 进 ...
- 【CF589 E】Another Filling the Grid
一个很套路的容斥裸题,这里记录一下scb 的切题过程 Description 有一个 \(n\times n\) 的矩阵,你需要往每格里填一个 \([1,k]\) 的整数,使得每一行.每一列的最小值都 ...
- gitlab配置邮箱postfix(新用户激活邮件)
亲测可用 https://www.cnblogs.com/yoyoketang/p/10287345.html
- Spring Cloud|高可用的Eureka集群服务
Eureka,作为spring cloud的服务发现与注册中心,在整个的微服务体系中,处于核心位置.单一的eureka服务,显然不能满足高可用的实际生产环境,这就要求我们配置一个能够应对各种突发情况, ...
- Flutter安装
下载右边的安装包以获取最新版本 stable 的 Flutter SDK 将压缩包解压,然后把其中的 flutter 目录整个放在你预想的 Flutter SDK 安装目录中(比如 C:\src\fl ...
- ORM SQLAlchemy - 建立一个关系 relationship
relationship函数是sqlalchemy对关系之间提供的一种便利的调用方式, backref参数则对关系提供反向引用的声明 1 背景 如没有relationship,我们只能像下面这样调用关 ...
- 安装 PostgreSQL 时丢失 libintl-8.dll 解决方案
发表于 2013 年 11 月 13 日 修订于 2018 年 05 月 05 日 PostgreSQL 比 MySQL 有更多的高级特性,而且微信支付的数据库也是基于 PostgreSQL ...
- TypeError: Data location must be "memory" for return parameter in function, but none was given.
在用truffle编译智能合约时,报错 TypeError: Data location must be "memory" for return parameter in fu ...