CompletionService异步非阻塞获取并行任务执行结果
第1部分 问题引入
《Java并发编程实践》一书6.3.5节CompletionService:Executor和BlockingQueue,有这样一段话:
"如果向Executor提交了一组计算任务,并且希望在计算完成后获得结果,那么可以保留与每个任务关联的Future,然后反复使用get方法,同时将参数timeout指定为0,从而通过轮询来判断任务是否完成。这种方法虽然可行,但却有些繁琐。幸运的是,还有一种更好的方法:完成服务CompletionService。"
这是什么意思呢?通过一个例子,分别使用繁琐的做法和CompletionService来完成,清晰的对比能让我们更好的理解上面的一段话和CompletionService这个API提供的初衷。
第2部分 实例
考虑这样的场景,有5个Callable任务分别返回5个整数,然后我们在main方法中按照各个任务完成的先后顺序,在控制台打印返回结果。
public class ReturnAfterSleepCallable implements Callable<Integer>{
private int sleepSeconds;
private int returnValue;
public ReturnAfterSleepCallable(int sleepSeconds,int returnValue){
this.sleepSeconds = sleepSeconds;
this.returnValue = returnValue;
}
@Override
public Integer call() throws Exception {
System.out.println("begin to execute ");
TimeUnit.SECONDS.sleep(sleepSeconds);
return returnValue;
}
}
1.轮询的做法
通过一个List来保存每个任务返回的Future,然后轮询这些Future,直到每个Future都已完成。我们不希望出现因为排在前面的任务阻塞导致后面先完成的任务的结果没有及时获取的情况,所以在调用get方式时,需要将超时时间设置为0。
public class TraditionalTest {
public static void main(String[] args){
int taskSize = 5;
ExecutorService executor = Executors.newFixedThreadPool(taskSize);
List<Future<Integer>> futureList = new ArrayList<Future<Integer>>();
for(int i= 1; i<=taskSize; i++){
int sleep = taskSize -1;
int value = i;
//向线程池提交任务
Future<Integer> future = executor.submit(new ReturnAfterSleepCallable(sleep, value));
//保留每个任务的Future
futureList.add(future);
}
// 轮询,获取完成任务的返回结果
while(taskSize > 0){
for (Future<Integer> future : futureList){
Integer result = null;
try {
result = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//任务已经完成
if(result!=null){
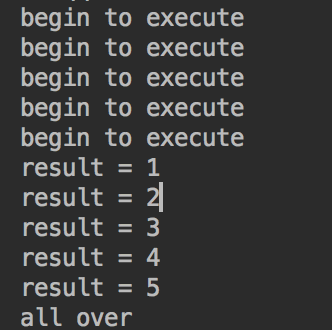
System.out.println("result = "+result);
//从future列表中删除已经完成的任务
futureList.remove(future);
taskSize --;
break;
}
}
}
// 所有任务已经完成,关闭线程池
System.out.println("all over ");
executor.shutdown();
}
}
执行结果:
2.使用CompletionService
public class CompletionServiceTest {
public static void main(String[] args){
int taskSize = 5;
ExecutorService executor = Executors.newFixedThreadPool(taskSize);
// 构建完成服务
CompletionService<Integer> completionService = new ExecutorCompletionService<Integer>(executor);
for (int i=1;i<= taskSize; i++){
// 睡眠时间
int sleep = taskSize - i;
// 返回结果
int value = i;
//向线程池提交任务
completionService.submit(new ReturnAfterSleepCallable(sleep, value));
try {
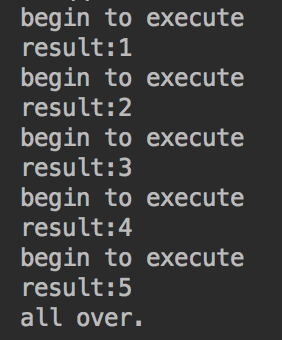
System.out.println("result:"+completionService.take().get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
System.out.println("all over. ");
executor.shutdown();
}
}
执行结果:
第3部分 源码分析
首先看一下 构造方法:
public ExecutorCompletionService(Executor executor) {
if (executor == null)
throw new NullPointerException();
this.executor = executor;
this.aes = (executor instanceof AbstractExecutorService) ?
(AbstractExecutorService) executor : null;
//创建阻塞队列
this.completionQueue = new LinkedBlockingQueue<Future<V>>();
}
构造法方法主要初始化了一个阻塞队列,用来存储已完成的task任务。 ExecutorCompletionService是CompletionService的实现,融合了线程池Executor和阻塞队列BlockingQueue的功能。可以推测,按照任务的完成顺序获取结果,就是通过阻塞队列实现的,阻塞队列刚好具有这样的性质:阻塞和有序。
然后看一下 completionService.submit 方法:
public Future<V> submit(Callable<V> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<V> f = newTaskFor(task);
//将我们的callable任务包装成QueueingFuture
executor.execute(new QueueingFuture(f));
return f;
}
可以看到,callable任务被包装成QueueingFuture,而 QueueingFuture是 FutureTask的子类,所以最终执行了FutureTask中的run()方法。来看一下该方法:
public void run() {
//判断执行状态,保证callable任务只被运行一次
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
//这里回调我们创建的callable对象中的call方法
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
//处理执行结果
set(result);
}
} finally {
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
可以看到在该 FutureTask 中执行run方法,最终回调自定义的callable中的call方法,执行结束之后,通过 set(result) 处理执行结果:
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
//设置执行结果v,并标记线程执行状态为:NORMAL
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL);
//完成执行,将执行结果添加到队列
finishCompletion();
}
}
继续跟进finishCompletion()方法,在该方法中找到 done()方法:
protected void done() { completionQueue.add(task); }
可以看到该方法只做了一件事情,就是将执行结束的task添加到了队列中,只要队列中有元素,我们调用take()方法时就可以获得执行的结果。
到这里就已经清晰了,异步非阻塞获取执行结果的实现原理其实就是通过队列来实现的,FutureTask将执行结果放到队列中,先进先出,线程执行结束的顺序就是获取结果的顺序。
CompletionService异步非阻塞获取并行任务执行结果的更多相关文章
- 多线程异步非阻塞之CompletionService
引自:https://www.cnblogs.com/swiftma/p/6691235.html 上节,我们提到,在异步任务程序中,一种常见的场景是,主线程提交多个异步任务,然后希望有任务完成就处理 ...
- Tornado异步非阻塞的使用以及原理
Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快.得利于其 非阻塞的方式和对 epoll 的运用,Tornado ...
- 03: 自定义异步非阻塞tornado框架
目录:Tornado其他篇 01: tornado基础篇 02: tornado进阶篇 03: 自定义异步非阻塞tornado框架 04: 打开tornado源码剖析处理过程 目录: 1.1 源码 1 ...
- python---tornado补充(异步非阻塞)
一:正常访问(同一线程中多个请求是同步阻塞状态) import tornado.ioloop import tornado.web import tornado.websocket import da ...
- Tornado之自定义异步非阻塞的服务器和客户端
一.自定义的异步非阻塞的客户端 #!/usr/bin/env python # -*- coding: utf8 -*- # __Author: "Skiler Hao" # da ...
- 利用tornado使请求实现异步非阻塞
基本IO模型 网上搜了很多关于同步异步,阻塞非阻塞的说法,理解还是不能很透彻,有必要买书看下. 参考:使用异步 I/O 大大提高应用程序的性能 怎样理解阻塞非阻塞与同步异步的区别? 同步和异步:主要关 ...
- Python web框架 Tornado(二)异步非阻塞
异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案:多线程,多进程 异步非阻塞(存在IO请求): Torna ...
- 150行代码搭建异步非阻塞Web框架
最近看Tornado源码给了我不少启发,心血来潮决定自己试着只用python标准库来实现一个异步非阻塞web框架.花了点时间感觉还可以,一百多行的代码已经可以撑起一个极简框架了. 一.准备工作 需要的 ...
- Python web框架 Tornado异步非阻塞
Python web框架 Tornado异步非阻塞 异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案: ...
随机推荐
- 我的dbtreeview–treeview直接连接数据表_delphi教程
unit Unit1; interface uses Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs ...
- 使用 bash 脚本把 AWS EC2 数据备份到 S3
目录 一.IAM 秘钥授权方式(普通) 1.1.打开 IAM 1.2.添加用户 1.3.安装和配置 AWS CLI 1.4.配置授权 二.IAM 角色授权方式(安全) 2.1.创建一个 EC2 访问 ...
- PHP实现发送模板消息(微信公众号版)
以下为开发步骤: 1.微信公众号为服务号且开通微信认证(其他类型账号不能发送) 2.ip白名单设置你的服务器ip(用于获取access_token) 3.网页授权你的域名(用于获取用户的openid) ...
- Vulnhub-XXE靶机学习
------------恢复内容开始------------ 前两天在微信公众号上看见了这个XXE靶场,就想试一试,虽然网上关于这个的文章已经写了太多太多了,但还是要写出来划划水,233333333, ...
- OpenCV.20190628
1.OpenCV提取ORB特征并匹配 - 简书.html(https://www.jianshu.com/p/420f8211d1cb) OpenCV提取ORB特征并匹配 - 简书.html(http ...
- bootstrap基础学习【网格系统】(三)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Linux 重启php
对于高版本PHP, 例如PHP 5.6, 重启PHP命令: service php-fpm restart 如果提示权限不足, 请使用: 1 sudo service php-fpm restart
- 幻数浅析(Magic Number)
在源代码编写中,有这么一种情况:编码者在写源代码的时候,使用了一个数字,比如0x2123,0.021f等,他当时是明白这个数字的意思的,但是别的程序员看他的代码,可能很难理解,甚至,过了一段时间,代码 ...
- 洛谷 题解 P1284 【三角形牧场】
状态: dp[i][j]表示用i和j的木板能否搭成,不用去管第三块,因为知道了两块的长度与周长,那就可以表示出第三块:c-i-j 转移 有点类似于背包 if((j-l[i]>=0&&am ...
- Reactor系列(十一)take获取
#java#reactor#take#获取# 获取Flux订阅数量 视频讲解: https://www.bilibili.com/video/av80322616/ FluxMonoTestCase. ...