CompletionService异步非阻塞获取并行任务执行结果
第1部分 问题引入
《Java并发编程实践》一书6.3.5节CompletionService:Executor和BlockingQueue,有这样一段话:
"如果向Executor提交了一组计算任务,并且希望在计算完成后获得结果,那么可以保留与每个任务关联的Future,然后反复使用get方法,同时将参数timeout指定为0,从而通过轮询来判断任务是否完成。这种方法虽然可行,但却有些繁琐。幸运的是,还有一种更好的方法:完成服务CompletionService。"
这是什么意思呢?通过一个例子,分别使用繁琐的做法和CompletionService来完成,清晰的对比能让我们更好的理解上面的一段话和CompletionService这个API提供的初衷。
第2部分 实例
考虑这样的场景,有5个Callable任务分别返回5个整数,然后我们在main方法中按照各个任务完成的先后顺序,在控制台打印返回结果。
public class ReturnAfterSleepCallable implements Callable<Integer>{
private int sleepSeconds;
private int returnValue;
public ReturnAfterSleepCallable(int sleepSeconds,int returnValue){
this.sleepSeconds = sleepSeconds;
this.returnValue = returnValue;
}
@Override
public Integer call() throws Exception {
System.out.println("begin to execute ");
TimeUnit.SECONDS.sleep(sleepSeconds);
return returnValue;
}
}
1.轮询的做法
通过一个List来保存每个任务返回的Future,然后轮询这些Future,直到每个Future都已完成。我们不希望出现因为排在前面的任务阻塞导致后面先完成的任务的结果没有及时获取的情况,所以在调用get方式时,需要将超时时间设置为0。
public class TraditionalTest {
public static void main(String[] args){
int taskSize = 5;
ExecutorService executor = Executors.newFixedThreadPool(taskSize);
List<Future<Integer>> futureList = new ArrayList<Future<Integer>>();
for(int i= 1; i<=taskSize; i++){
int sleep = taskSize -1;
int value = i;
//向线程池提交任务
Future<Integer> future = executor.submit(new ReturnAfterSleepCallable(sleep, value));
//保留每个任务的Future
futureList.add(future);
}
// 轮询,获取完成任务的返回结果
while(taskSize > 0){
for (Future<Integer> future : futureList){
Integer result = null;
try {
result = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//任务已经完成
if(result!=null){
System.out.println("result = "+result);
//从future列表中删除已经完成的任务
futureList.remove(future);
taskSize --;
break;
}
}
}
// 所有任务已经完成,关闭线程池
System.out.println("all over ");
executor.shutdown();
}
}
执行结果:
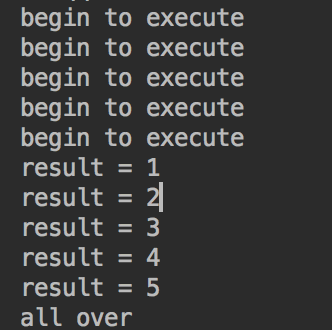
2.使用CompletionService
public class CompletionServiceTest {
public static void main(String[] args){
int taskSize = 5;
ExecutorService executor = Executors.newFixedThreadPool(taskSize);
// 构建完成服务
CompletionService<Integer> completionService = new ExecutorCompletionService<Integer>(executor);
for (int i=1;i<= taskSize; i++){
// 睡眠时间
int sleep = taskSize - i;
// 返回结果
int value = i;
//向线程池提交任务
completionService.submit(new ReturnAfterSleepCallable(sleep, value));
try {
System.out.println("result:"+completionService.take().get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
System.out.println("all over. ");
executor.shutdown();
}
}
执行结果:
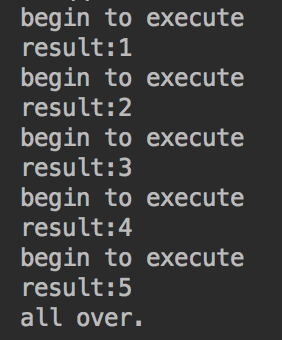
第3部分 源码分析
首先看一下 构造方法:
public ExecutorCompletionService(Executor executor) {
if (executor == null)
throw new NullPointerException();
this.executor = executor;
this.aes = (executor instanceof AbstractExecutorService) ?
(AbstractExecutorService) executor : null;
//创建阻塞队列
this.completionQueue = new LinkedBlockingQueue<Future<V>>();
}
构造法方法主要初始化了一个阻塞队列,用来存储已完成的task任务。 ExecutorCompletionService是CompletionService的实现,融合了线程池Executor和阻塞队列BlockingQueue的功能。可以推测,按照任务的完成顺序获取结果,就是通过阻塞队列实现的,阻塞队列刚好具有这样的性质:阻塞和有序。
然后看一下 completionService.submit 方法:
public Future<V> submit(Callable<V> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<V> f = newTaskFor(task);
//将我们的callable任务包装成QueueingFuture
executor.execute(new QueueingFuture(f));
return f;
}
可以看到,callable任务被包装成QueueingFuture,而 QueueingFuture是 FutureTask的子类,所以最终执行了FutureTask中的run()方法。来看一下该方法:
public void run() {
//判断执行状态,保证callable任务只被运行一次
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
//这里回调我们创建的callable对象中的call方法
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
//处理执行结果
set(result);
}
} finally {
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
可以看到在该 FutureTask 中执行run方法,最终回调自定义的callable中的call方法,执行结束之后,通过 set(result) 处理执行结果:
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
//设置执行结果v,并标记线程执行状态为:NORMAL
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL);
//完成执行,将执行结果添加到队列
finishCompletion();
}
}
继续跟进finishCompletion()方法,在该方法中找到 done()方法:
protected void done() { completionQueue.add(task); }
可以看到该方法只做了一件事情,就是将执行结束的task添加到了队列中,只要队列中有元素,我们调用take()方法时就可以获得执行的结果。
到这里就已经清晰了,异步非阻塞获取执行结果的实现原理其实就是通过队列来实现的,FutureTask将执行结果放到队列中,先进先出,线程执行结束的顺序就是获取结果的顺序。
CompletionService异步非阻塞获取并行任务执行结果的更多相关文章
- 多线程异步非阻塞之CompletionService
引自:https://www.cnblogs.com/swiftma/p/6691235.html 上节,我们提到,在异步任务程序中,一种常见的场景是,主线程提交多个异步任务,然后希望有任务完成就处理 ...
- Tornado异步非阻塞的使用以及原理
Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快.得利于其 非阻塞的方式和对 epoll 的运用,Tornado ...
- 03: 自定义异步非阻塞tornado框架
目录:Tornado其他篇 01: tornado基础篇 02: tornado进阶篇 03: 自定义异步非阻塞tornado框架 04: 打开tornado源码剖析处理过程 目录: 1.1 源码 1 ...
- python---tornado补充(异步非阻塞)
一:正常访问(同一线程中多个请求是同步阻塞状态) import tornado.ioloop import tornado.web import tornado.websocket import da ...
- Tornado之自定义异步非阻塞的服务器和客户端
一.自定义的异步非阻塞的客户端 #!/usr/bin/env python # -*- coding: utf8 -*- # __Author: "Skiler Hao" # da ...
- 利用tornado使请求实现异步非阻塞
基本IO模型 网上搜了很多关于同步异步,阻塞非阻塞的说法,理解还是不能很透彻,有必要买书看下. 参考:使用异步 I/O 大大提高应用程序的性能 怎样理解阻塞非阻塞与同步异步的区别? 同步和异步:主要关 ...
- Python web框架 Tornado(二)异步非阻塞
异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案:多线程,多进程 异步非阻塞(存在IO请求): Torna ...
- 150行代码搭建异步非阻塞Web框架
最近看Tornado源码给了我不少启发,心血来潮决定自己试着只用python标准库来实现一个异步非阻塞web框架.花了点时间感觉还可以,一百多行的代码已经可以撑起一个极简框架了. 一.准备工作 需要的 ...
- Python web框架 Tornado异步非阻塞
Python web框架 Tornado异步非阻塞 异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案: ...
随机推荐
- Ubuntu 18.04设置1920*1080
Ubuntu升级后,发现分辨率没有1920*1080,在网上寻找了一个文章解决办法如下. 方案一(临时性,重启会失效): 1.打开终端.输入:cvt 1920 1080 出现有modeline 的提示 ...
- Tomcat 80端口被占用
1.“运行”中输入cmd2.在命令行中输入netstat -ano,得到端口号对应的PID 3.打开任务管理器,点击“查看“菜单,选择“选择列”,给进程列表中添加”PID“列,然后找到PID对应的进程 ...
- linux双机热备份
使用HeartBeat实现高可用HA的配置过程详解 一.写在前面 HA即(high available)高可用,又被叫做双机热备,用于关键性业务.简单理解就是,有2台机器 A 和 B,正常是 A 提供 ...
- Linux磁盘和文件系统扩容彻底研究
1.物理卷: LVM 逻辑卷的底层物理存储单元是一个块设备,比如一个分区或整个磁盘.要在 LVM 逻辑卷中使用该设备,则必须将该设备初始化为物理卷(PV). 2.卷组:物理卷合并为卷组(VG).这样就 ...
- 安装ELectron失败解决方案
npm安装Electron解决方案 Electron使用npm安装时,因为是国外的镜像源,所以速度会非常慢.而使用cnpm如下命令进行安装时,又会出现安装失败的问题: npm install elec ...
- KVM虚拟机的热迁移---Live Migration
KVM虚拟机的热迁移---Live Migration: 服务器虚拟化技术是当前的热点,而虚拟机的“热迁移(Live Migration)”技术则是虚拟机的运行状态完整保存下来,同时可以快速的回复到原 ...
- 【Qt开发】 QT:make: Nothing to be done for `first'和error:QtSql:No such file or directory
http://blog.csdn.NET/heqiuya/article/details/7774208 这是QT编程中常见的两个编译错误.可能你的代码在window下编译能正常通过,可是到到Linu ...
- C# 添加日志文件
StreamWriter log_sw; // 新建文件 log_sw = File.AppendText(log_str); // 写入日志文件 log_sw.WriteLine(s + " ...
- String、StringBuilder、StringBuffer的爱恨情仇
第三阶段 JAVA常见对象的学习 StringBuffer和StringBuilder类 (一) StringBuffer类的概述 (1) 基本概述 下文以StringBuffer为例 前面我们用字符 ...
- SQL中的关键词
AS的用法及妙用 https://www.cnblogs.com/zhaotiancheng/p/6692553.html