Machine Learning(Andrew Ng)学习笔记
1.监督学习(supervised learning)&非监督学习(unsupervised learning)
监督学习:处理具有若干属性且返回值不同的对象。分为回归型和分类型:回归型的返回值是连续的,分类型的返回值是离散的。
非监督学习:将具有若干属性的相同对象分为不同的群体。
2.线性回归模型(监督学习)
2.1 一些符号
m——训练样本数目
x——输入变量
y——输出变量
(x,y)——一个训练样本
(x(i),y(i))——第i个训练样本
h——假设(hypothesis)——预测函数
n——训练样本特征数目
$x_{i}$——训练样本的第i个特征对应的向量
$x^{(i)}$——第i个训练样本所有特征对应的向量
$x_{j}^{(i)}$——第i个训练样本的第j个特征
2.2 cost function
$J\left ( \theta _{0},\theta _{1} \right )= \frac{1}{2m}\sum_{i=1}^{m}\left ( h_{\theta }\left ( x^{(i)} \right )-y^{(i)} \right )^{2}$
$h_{\theta }(x)=\theta _{0}+\theta _{1}x$
2.3 梯度下降算法(gradient descent)
2.3.1 单特征:
$\theta _{i}:=\theta _{i}-\alpha \frac{\partial }{\partial \theta _{i}}J\left ( \theta _{0}, \theta _{1}\right ) (simultaneously\ for\ i=0\ and\ i=1)$
$J\left ( \theta _{0},\theta _{1} \right )= \frac{1}{2m}\sum_{i=1}^{m}\left ( h_{\theta }\left ( x^{(i)} \right )-y^{(i)} \right )^{2}$
$h_{\theta }(x)=\theta _{0}+\theta _{1}x$
即
$\theta _{0}:=\theta _{0}-\alpha \frac{1}{m}\sum_{i=1}^{m}\left (h_{\theta }(x^{(i)})-y^{(i)} \right )$
$\theta _{1}:=\theta _{1}-\alpha \frac{1}{m}\sum_{i=1}^{m}\left (h_{\theta }(x^{(i)})-y^{(i)} \right )\cdot x^{(i)}$
2.3.2 多特征:
$\theta _{i}:=\theta _{i}-\alpha \frac{\partial }{\partial \theta _{i}}J\left ( \theta\right ) (simultaneously\ for\ i=0\ to\ n)$
$\theta = \begin{pmatrix}\theta _{0}
\\\theta _{1}
\\\theta _{2}
\\...
\\\theta _{n}
\end{pmatrix}$
$x^{(i)} = \begin{pmatrix}x_{0}^{(i)}
\\x_{1}^{(i)}
\\x_{2}^{(i)}
\\...
\\x_{n}^{(i)}
\end{pmatrix}(x_{0}^{(i)}=1)$
$J\left (\theta \right )= \frac{1}{2m}\sum_{i=1}^{m}\left ( h_{\theta }(x^{(i)})-y^{(i)} \right )^{2}$
$h_{\theta }(x^{(i)})=\theta ^{T}x^{(i)}$
即
$\theta_{j}:=\theta_{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})\cdot x_{j}^{(i)}$
2.3.3
批处理梯度下降("Batch" Gradient Descent):梯度下降的每一步都要用到所有训练样本的数据
2.4 优化方法
2.4.1 特征缩放(feature scaling)
$x_{j}^{(i)}:=\frac{x_{j}^{(i)}-\mu_{j}}{S_{j}}$
$\mu_{j}$为训练样本的第j个特征的平均值
$S_{j}$为训练样本的第j个特征的标准差(max-min)
2.4.2
(1)工作正确性检验
随着迭代次数(iteration)的增加,代价函数$J(\theta)$不可能增加
当$J(\theta)$减少量小于$\varepsilon $时,认为代价函数已收敛
(2)学习速率($\alpha$)选取
$\alpha$过小:收敛过慢
$\alpha$过大:无法保证每次迭代$J(\theta)$都不增加;无法保证收敛(solution:减小$\alpha$)
3 多项式回归
3.1
直接把f(x)作为一个整体当成$x^{(i)}_{j}$,即可把非线性回归转化为线性回归
3.2 数学方法直接求出最优解

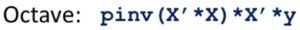
3.3

Machine Learning(Andrew Ng)学习笔记的更多相关文章
- Machine Learning - Andrew Ng - Coursera
Machine Learning - Andrew Ng - Coursera Contents 1 Notes 1 Notes What is Machine Learning? Two defin ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记
Week1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记(完结)
Week 1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- Coursera 机器学习 第6章(下) Machine Learning System Design 学习笔记
Machine Learning System Design下面会讨论机器学习系统的设计.分析在设计复杂机器学习系统时将会遇到的主要问题,给出如何巧妙构造一个复杂的机器学习系统的建议.6.4 Buil ...
- [Machine Learning] Andrew Ng on Coursera (Week 1)
Week 1 的内容主要有: 机器学习的定义 监督式学习和无监督式学习 线性回归和成本函数 梯度下降算法 线性代数回归 主要是了解一下机器学习的基本概念,重点是学习线性回归模型,以及对应的成本函数和梯 ...
- [Machine Learning (Andrew NG courses)]II. Linear Regression with One Variable
- [Machine Learning (Andrew NG courses)]IV.Linear Regression with Multiple Variables
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvenFoXzE5OTE=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA ...
- Machine Learning With Spark学习笔记(在10万电影数据上训练、使用推荐模型)
我们如今開始训练模型,还输入參数例如以下: rank:ALS中因子的个数.通常来说越大越好,可是对内存占用率有直接影响,通常rank在10到200之间. iterations:迭代次数,每次迭代都会降 ...
- Machine Learning With Spark学习笔记(提取10万电影数据特征)
注:原文中的代码是在spark-shell中编写运行的,本人的是在eclipse中编写运行,所以结果输出形式可能会与这本书中的不太一样. 首先将用户数据u.data读入SparkContext中.然后 ...
随机推荐
- SQLite进阶-11.Join
目录 JOIN 交叉连接 - CROSS JOIN 内连接 - INNER JOIN 外连接 - OUTER JOIN JOIN JOIN 子句用于结合两个或者多个数据表的数据,基于这些表之间的共同字 ...
- logid让你的请求完整可追溯
今天是在博客园开园的第一天 一时间其实并不能想起来到底该写什么文章,其实想写的东西挺多 今天就以logid这个主题开始吧,网上写这个的文章似乎不多,但是的确是在实际生产中相当重要的一个能力,也是容易被 ...
- Jmeter的基础使用一安装、启动、关联、断言
一.下载Jmeter,配置环境变量 下载完解压即可, 环境变量配置: -------在环境变量中添加新变量JMETER_HOME:D:\jmeter\apache-jmeter-4.0 ------- ...
- mysql内存优化
一.环境说明: 操作系统:CentOS 6.5 x86_64 数据库:Mysql 5.6.22 服务器:阿里云VPS,32G Mem,0 swap 二.问题情况: 1.某日发现公司线上系统的Mysql ...
- X86逆向8:向程序中插入新区段
本节课我们不去破解程序,本节课学习给应用程序插入一些代码片段,这里我就插入一个弹窗喽,当然你也可以插入一段恶意代码,让使用的人中招, 这里有很多原理性的东西我就不多罗嗦了毕竟是新手入门教程,如果想去了 ...
- MySQL中的DML、DQL和子查询
一.MySQL中的DML语句 1.使用insert插入数据记录: INSERT INTO `myschool`.`student` (`studentNo`, `loginPwd`, `student ...
- the specified service is marked as deletion,can not find the file specified
使用命令注册windows service sc create CCGSQueueService binpath= "D:\DKX4003\services\xxx.xx.xx\xxx.ex ...
- Func<>委托、扩展方法、yield、linq ForEach综合运用
1.先定义一个Model类 public class P1 { public string name { get; set; } public int age ...
- Flask:上下文管理
1. werkzurg from werkzur.serving import run_simple def run(environ,start_response): reuturn [b'hello ...
- TensorFlow良心入门教程
All the matrials come from Machine Learning class in Polyu,HK and I reorganize them and add referenc ...