HDFS的NameNode与SecondaryNameNode的工作原理
原文:https://blog.51cto.com/xpleaf/2147375
看完之后确实对nameNode的工作更加清晰一些
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一。
从它的名字上看,它给人的感觉就像是NameNode的备份。但它实际上却不是。很多Hadoop的初学者都很疑惑,Secondary NameNode究竟是做什么的,而且它为什么会出现在HDFS中。本文将解释下SecondaryNameNode在HDFS中所扮演的角色。
从它的名字来看,你可能认为它跟NameNode有点关系。没错,你猜对了。因此在我们深入了解SecondaryNameNode之前,我们先来看看NameNode是做什么的。
NameNode
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
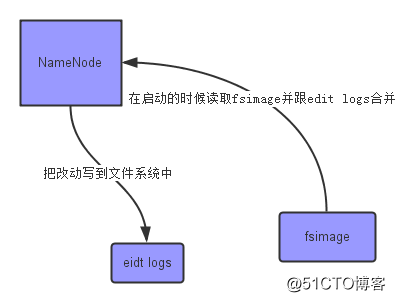
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
- fsimage - 它是在NameNode启动时对整个文件系统的快照
- edit logs - 它是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
- edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
- NameNode的重启会花费很长时间,因为有很多改动[在edit logs中]要合并到fsimage文件上。
- 如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。[在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到edit logs的这部分。]
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。
现在我们明白了NameNode的功能和所面临的挑战 - 保持文件系统最新的元数据。那么,这些跟SecondaryNameNode又有什么关系呢?
[
叶子备注:
那么从上面的分析以及后面的文档可以知道,或者说,很容易产生一个疑问,既然fsimage要在nameNode重启以后才能更新,即便后面有了secondaryNameNode之后也要一定的时间后才会去同步这些文件,那么为什么每次上传一个文件后,就可以马上通过命令行方式获取到这个文件呢,我的元数据信息可是保存在fsimage中的呀!不要忘记了,fsimage和edit的存在只是为了持久化这些数据信息,这意味着,nameNode启动之后,内存当中肯定也是保存着这些信息的,而添加删除文件等操作所产生的信息,肯定也是有保存到nameNode的内存当中的(不然怎么可能马上就读取到这些数据呢),同步fsimage,合并edit,只是为了持久化这些数据,防止nameNode出现异常时元数据信息的丢失。
]
Secondary NameNode
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
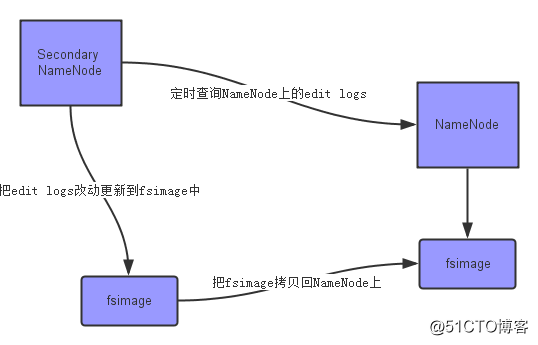
上面的图片展示了SecondaryNameNode是怎么工作的。
首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[Secondary NameNode自己的fsimage]
一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。
现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。所以一般也称呼它为checkpoint node吧。
二者的工作机制
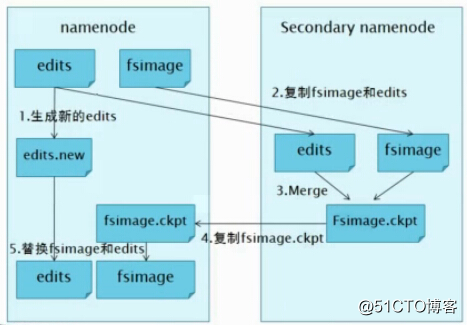
1.NameNode管理着元数据信息,元数据信息会定期的刷到磁盘中,其中的两个文件是edits即操作日志文件和fsimage即元数据镜像文件,新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源)。当edits文件的大小达到一个临界值(默认是64MB)或者间隔一段时间(默认是1小时)的时候checkpoint会触发SecondaryNameNode进行工作。
2.当触发一个checkpoint操作时,NameNode会生成一个新的edits即上图中的edits.new文件,同时SecondaryNameNode会将edits文件和fsimage复制到本地。
3.SecondaryNameNode将本地的fsimage文件加载到内存中,然后再与edits文件进行合并生成一个新的fsimage文件即上图中的Fsimage.ckpt文件。
4.SecondaryNameNode将新生成的Fsimage.ckpt文件复制到NameNode节点。
5.在NameNode结点的edits.new文件和Fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此,刚好是一个轮回即在NameNode中又是edits和fsimage文件了。
6.等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
注:checkpoint触发的条件可以在hdfs-site.xml文件中进行配置,如下:
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>
The number of seconds between two periodic checkpoints.
</description>
</property> HDFS的NameNode与SecondaryNameNode的工作原理的更多相关文章
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- hadoop平台上HDFS和MAPREDUCE的功能、工作原理和工作过程
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- NameNode 与 SecondaryNameNode 的工作机制
一.NameNode.Fsimage .Edits 和 SecondaryNameNode 概述 NameNode:在内存中储存 HDFS 文件的元数据信息(目录) 如果节点故障或断电,存在内存中的数 ...
- NameNode和SecondaryNameNode的工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中,一旦 ...
- HDSF主要节点解说(二)工作原理
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统. 是依据google发表的论文翻版的.论文为GFS(Google File System)Goog ...
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- HADOOP1.X中HDFS工作原理
转载自:http://www.daniubiji.cn/archives/596 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据googl ...
随机推荐
- api的日志
package cn.com.acxiom.coty.wechat.ws.bean.po; import java.util.Date; public class WebserviceLogWecha ...
- Kinect for Windows SDK开发入门(七):骨骼追踪基础 下
http://www.cnblogs.com/yangecnu/archive/2012/04/09/KinectSDK_Skeleton_Tracking_Part2.html 上一篇文章用在UI界 ...
- 若干简单的进程和作业调度的C++模拟程序
进程调度(时间片轮转,动态优先级,链表形式): #include<cstdio> #include<cstdlib> struct PCB { ]; char state; / ...
- vscode插件-JavaScript(ES6) Code Snippets 缩写代表含义
Import and export Trigger Content imp→ imports entire module import fs from 'fs'; imn→ imports entir ...
- vue1 动态组件
- 推荐一款在IntelliJ IDEA中使用微信/QQ的插件
SmartIM SmartIM4IntelliJ 是一个 IntelliJ IDEA 上的 SmartIM(原 SmartQQ)插件,可以在 IDEA 中使用 QQ 或微信聊天. 功能 收发文本消息 ...
- redis与spring整合实例
1)首先是redis的配置. 使用的是maven工程,引入redis与spring整合的相关jar包 <!-- redis服务 start--> <dependency> &l ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- eclipse-jee-luna安装ADT-23.0.6出现的问题,以及解决办法
刚安装好ADT-23.0.6,然后配置sdk路径(最新的版本android-22),然后创建一个新的Android Project; 对于布局界面会出现如下错误,导致无法显示布局界面: java.la ...
- [Luogu] 校园网Network of Schools
https://www.luogu.org/problemnew/show/2746 Tarjan 缩点 判断入度为0的点的个数与出度为0的点的个数的关系 注意全缩为一个点的情况 #include & ...