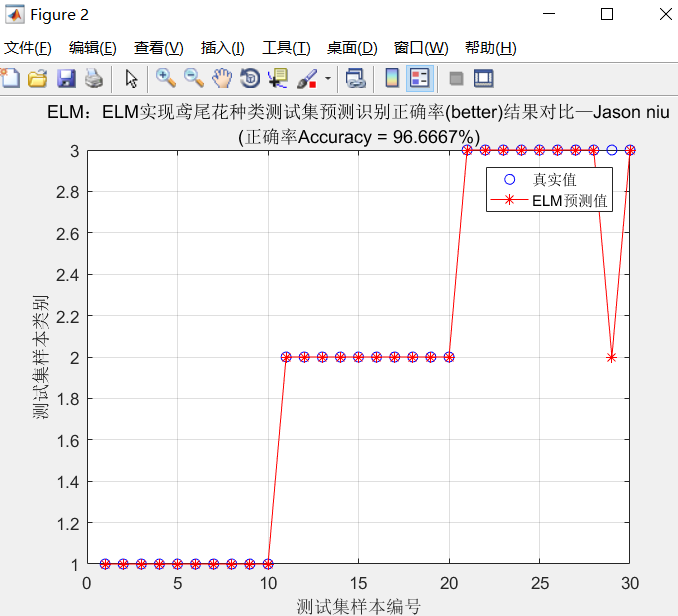
ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu
load iris_data.mat P_train = [];
T_train = [];
P_test = [];
T_test = [];
for i = 1:3
temp_input = features((i-1)*50+1:i*50,:);
temp_output = classes((i-1)*50+1:i*50,:);
n = randperm(50); P_train = [P_train temp_input(n(1:40),:)'];
T_train = [T_train temp_output(n(1:40),:)']; P_test = [P_test temp_input(n(41:50),:)'];
T_test = [T_test temp_output(n(41:50),:)'];
end [IW,B,LW,TF,TYPE] = elmtrain(P_train,T_train,20,'sig',1); T_sim_1 = elmpredict(P_train,IW,B,LW,TF,TYPE);
T_sim_2 = elmpredict(P_test,IW,B,LW,TF,TYPE); result_1 = [T_train' T_sim_1'];
result_2 = [T_test' T_sim_2']; k1 = length(find(T_train == T_sim_1));
n1 = length(T_train);
Accuracy_1 = k1 / n1 * 100;
disp(['训练集正确率Accuracy = ' num2str(Accuracy_1) '%(' num2str(k1) '/' num2str(n1) ')']) k2 = length(find(T_test == T_sim_2));
n2 = length(T_test);
Accuracy_2 = k2 / n2 * 100;
disp(['测试集正确率Accuracy = ' num2str(Accuracy_2) '%(' num2str(k2) '/' num2str(n2) ')']) figure(2)
plot(1:30,T_test,'bo',1:30,T_sim_2,'r-*')
grid on
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu';['(正确率Accuracy = ' num2str(Accuracy_2) '%)' ]};
title(string)
legend('真实值','ELM预测值')
ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu的更多相关文章
- ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
%ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu load spectra_data.mat temp = randperm(size(NIR,1)); P_tra ...
- RBF:RBF基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat temp = randperm(size(NIR,1)); P_train = NIR(temp(1:50),:)'; T_train = octane(t ...
- GRNN/PNN:基于GRNN、PNN两神经网络实现并比较鸢尾花种类识别正确率、各个模型运行时间对比—Jason niu
load iris_data.mat P_train = []; T_train = []; P_test = []; T_test = []; for i = 1:3 temp_input = fe ...
- NN:实现BP神经网络的回归拟合,基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat plot(NIR') title('Near infrared spectrum curve—Jason niu') temp = randperm(siz ...
- TF之AE:AE实现TF自带数据集数字真实值对比AE先encoder后decoder预测数字的精确对比—Jason niu
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #Import MNIST data from t ...
- PCA:利用PCA(四个主成分的贡献率就才达100%)降维提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- Tensorflow&CNN:验证集预测与模型评价
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/90480140 - 写在前面 本科毕业设计终于告一段落了.特 ...
- SVM—PK—BP:SVR(better)和BP两种方法比较且实现建筑物钢筋混凝土抗压强度预测—Jason niu
load concrete_data.mat n = randperm(size(attributes,2)); p_train = attributes(:,n(1:80))'; t_train = ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
随机推荐
- 移动端适配——font-size计算
function calcFontSize(){ var view_width = window.screen.width; var view_height = window.screen.heigh ...
- 微信video最上层解决问题
/* http://blog.csdn.net/kepoon/article/details/53608190 */ //x5-video-player-type="h5" x ...
- Confluence 6 WebDAV 禁用严格路径检查
如果你在你的 WebDAV 客户端发现了一些不正常的现象,例如文件夹在 Confluence 中是存在的,但是在你客户端下载的文件中就不存在了.你可以禁用 WebDAV 插件中的严格路径检查选项,这 ...
- http之cdn介绍
百度百科:CDN的全称是Content Delivery Network,即内容分发网络.CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡.内容分发.调度等功能 ...
- day12 函数的嵌套调用 闭包函数,函数对象
函数嵌套: 函数嵌套: 嵌套指的是,一个物体包含另一个物体,函数嵌套就是一个函数包含另一个函数 按照函数的两个阶段 嵌套调用 指的是在函数的执行过程中调用了另一个函数,其好处可以简化外层大函数的代码, ...
- LeetCode(105):从前序与中序遍历序列构造二叉树
Medium! 题目描述: 根据一棵树的前序遍历与中序遍历构造二叉树. 注意:你可以假设树中没有重复的元素. 例如,给出 前序遍历 preorder = [3,9,20,15,7] 中序遍历 inor ...
- 【sqli-labs】Less5~Less6
双注入原理: 来源: http://www.myhack58.com/Article/html/3/7/2016/73471.htm (非常详细的说明了原理,good) http://www.2cto ...
- tensorflow(1) 基础: 神经网络基本框架
1.tensorflow 的计算得到的是计算图graph import tensorflow as tf a=tf.constant([1.0,2.0]) b=tf.constant([3.0,4.0 ...
- cf1133 bcdef
b所有数模k,记录出现次数即可 #include<bits/stdc++.h> using namespace std; int main(){ ]; ]={}; cin>>n ...
- Nginx详解十七:Nginx深度学习篇之动静分离
动静分离:通过中间件将动态请求和静态请求分离 作用:分离资源,减少不必要的请求消耗,减少请求延时 动静分离还有个好处就是,当动态请求的后端服务出问题了,只会影响动态的部分,静态资源不影响,照样加载 如 ...