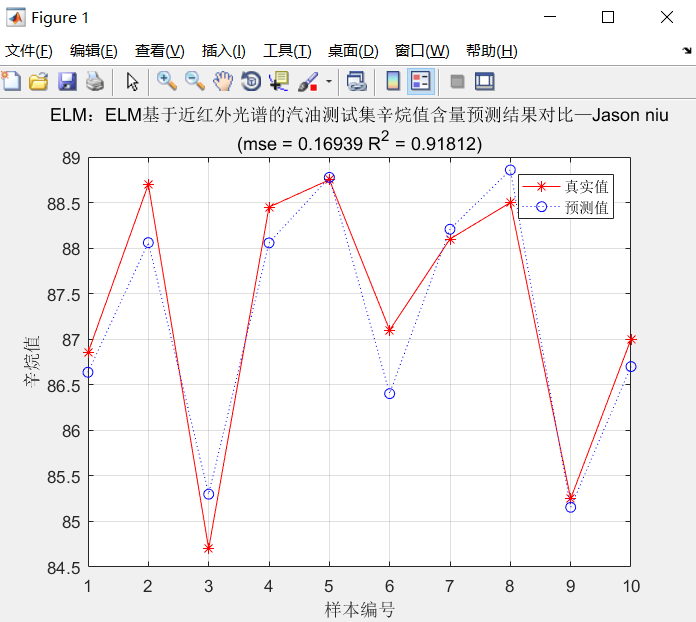
ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
%ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
load spectra_data.mat
temp = randperm(size(NIR,1)); P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)'; P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2); [Pn_train,inputps] = mapminmax(P_train);
Pn_test = mapminmax('apply',P_test,inputps); [Tn_train,outputps] = mapminmax(T_train);
Tn_test = mapminmax('apply',T_test,outputps); [IW,B,LW,TF,TYPE] = elmtrain(Pn_train,Tn_train,30,'sig',0); tn_sim = elmpredict(Pn_test,IW,B,LW,TF,TYPE); T_sim = mapminmax('reverse',tn_sim,outputps); result = [T_test' T_sim']; E = mse(T_sim - T_test); N = length(T_test);
R2=(N*sum(T_sim.*T_test)-sum(T_sim)*sum(T_test))^2/((N*sum((T_sim).^2)-(sum(T_sim))^2)*(N*sum((T_test).^2)-(sum(T_test))^2)); figure(1)
plot(1:N,T_test,'r-*',1:N,T_sim,'b:o')
grid on
legend('真实值','预测值')
xlabel('样本编号')
ylabel('辛烷值')
string = {'ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu';['(mse = ' num2str(E) ' R^2 = ' num2str(R2) ')']};
title(string)
ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu的更多相关文章
- RBF:RBF基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat temp = randperm(size(NIR,1)); P_train = NIR(temp(1:50),:)'; T_train = octane(t ...
- PLS:利用PLS(两个主成分的贡献率就可达100%)提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- PCA:利用PCA(四个主成分的贡献率就才达100%)降维提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- NN:实现BP神经网络的回归拟合,基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat plot(NIR') title('Near infrared spectrum curve—Jason niu') temp = randperm(siz ...
- ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu
load iris_data.mat P_train = []; T_train = []; P_test = []; T_test = []; for i = 1:3 temp_input = fe ...
- GRNN/PNN:基于GRNN、PNN两神经网络实现并比较鸢尾花种类识别正确率、各个模型运行时间对比—Jason niu
load iris_data.mat P_train = []; T_train = []; P_test = []; T_test = []; for i = 1:3 temp_input = fe ...
- Azure上搭建ActiveMQ集群-基于ZooKeeper配置ActiveMQ高可用性集群
ActiveMQ从5.9.0版本开始,集群实现方式取消了传统的Master-Slave方式,增加了基于ZooKeeper+LevelDB的实现方式. 本文主要介绍了在Windows环境下配置基于Zoo ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- 基于开源软件构建高性能集群NAS系统,包括负载均衡(刘爱贵)
大数据时代的到来已经不可阻挡,面对数据的爆炸式增长,尤其是半结构化数据和非结构化数据,NoSQL存储系统和分布式文件系统成为了技术浪潮,得到了长足的发展.非结构化数据目前呈现更加快速的增长趋势,IDC ...
随机推荐
- Confluence 6 导入模板的步骤
第一步:检查你 Confluence 站点中安装的模板组件 查看当前已经导入到你 Confluence 站点中可用的模板组件: 以系统管理员或者 Confluence 管理员权限登录 Confluen ...
- Swift中 @objc 使用介绍
在swift 中 如果一个按钮添加点击方法 如果定义为Private 或者 定义为 FilePrivate 那么会在Addtaget方法中找不到私有方法 但是又不想把方法暴露出来,避免外界访问 ,那 ...
- day03 变量 运算符 基本数据类型 输出功能 格式化输出
变量补充 变量的命名 1变量名的命名的大前提:应该能够反映出变量值所记录的状态 具体的1.变量名由字母数字下划线组成 2.不能以数字开头 3.不能使用关键字命名为变量名 两种写法 1.驼峰体(由字母组 ...
- 【linux】centos6.9通过virtualenv安装python3.5
参考:http://www.linuxidc.com/Linux/2015-08/121352.htm wget https://www.python.org/ftp/python/3.5.4/Pyt ...
- 在vue项目中使用axios发送FormData
这个是axios的中文文档,挺详细的: https://www.kancloud.cn/luponu/axios/873153 文档中的 使用 application/x-www-form-ur ...
- meter压力测试 设置一秒发送一次请求,一秒两次请求
使用jmeter进行压力测试 ,测试情况有 1.一秒钟投1次请求(一个线程) 持续30分钟的情况 2.一秒钟发送2次请求(两个线程) 持续30分钟的情况 下面说一下如何使用jmeter 测试这两种情 ...
- spring cloud config--client
概述 之前我们简单的搭建了一个单点的config-server服务,实现配置文件的统一管理,本次文章将实现config-client是如何从config-server中获取到统一配置文件信息的 1.创 ...
- 饮冰三年-人工智能-linux-03 Linux文件管理(权限管理+归档+压缩)
1:对文件的权限管理 drwxr-xr-x. 最后一个.表示在安全情况下创建的.selinux a: d表示目录:-表示普通文件:l表示快捷方式:b设备文件 b:- 属主的权限 r:读权限:w:写权限 ...
- 八卦一下Starlark语言
八卦一下Starlark语言 编译移植TensorFlow时用到Bazel这一构建工具,Bazel用Starlark语法来编写WORKSPACE/BUILD文件,它们是类似于Make中的makeifl ...
- MongDb介绍及简单实用
一:介绍 MongoDB是一个高性能,开源,无模式的文档型数据库,是当前NoSql数据库中比较热门的一种.它在许多场景下可用于替代传统的关系型数据库或键/值存储方式.Mongo使用C ...