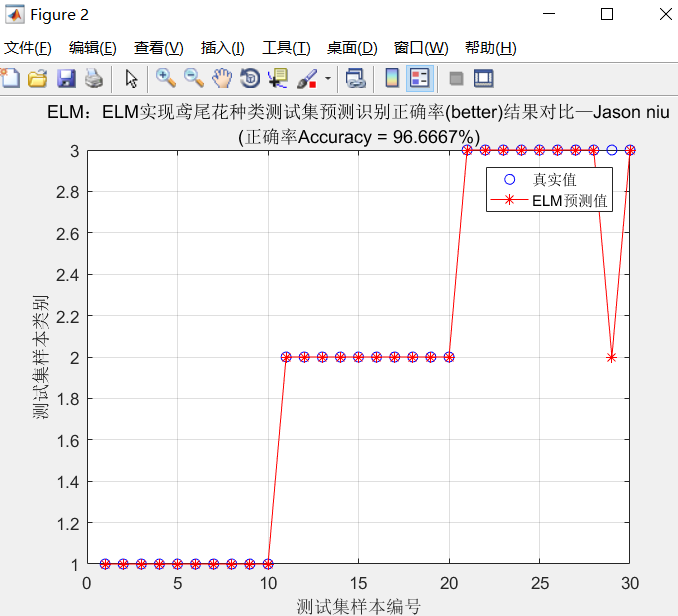
ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu
load iris_data.mat P_train = [];
T_train = [];
P_test = [];
T_test = [];
for i = 1:3
temp_input = features((i-1)*50+1:i*50,:);
temp_output = classes((i-1)*50+1:i*50,:);
n = randperm(50); P_train = [P_train temp_input(n(1:40),:)'];
T_train = [T_train temp_output(n(1:40),:)']; P_test = [P_test temp_input(n(41:50),:)'];
T_test = [T_test temp_output(n(41:50),:)'];
end [IW,B,LW,TF,TYPE] = elmtrain(P_train,T_train,20,'sig',1); T_sim_1 = elmpredict(P_train,IW,B,LW,TF,TYPE);
T_sim_2 = elmpredict(P_test,IW,B,LW,TF,TYPE); result_1 = [T_train' T_sim_1'];
result_2 = [T_test' T_sim_2']; k1 = length(find(T_train == T_sim_1));
n1 = length(T_train);
Accuracy_1 = k1 / n1 * 100;
disp(['训练集正确率Accuracy = ' num2str(Accuracy_1) '%(' num2str(k1) '/' num2str(n1) ')']) k2 = length(find(T_test == T_sim_2));
n2 = length(T_test);
Accuracy_2 = k2 / n2 * 100;
disp(['测试集正确率Accuracy = ' num2str(Accuracy_2) '%(' num2str(k2) '/' num2str(n2) ')']) figure(2)
plot(1:30,T_test,'bo',1:30,T_sim_2,'r-*')
grid on
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu';['(正确率Accuracy = ' num2str(Accuracy_2) '%)' ]};
title(string)
legend('真实值','ELM预测值')
ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu的更多相关文章
- ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
%ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu load spectra_data.mat temp = randperm(size(NIR,1)); P_tra ...
- RBF:RBF基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat temp = randperm(size(NIR,1)); P_train = NIR(temp(1:50),:)'; T_train = octane(t ...
- GRNN/PNN:基于GRNN、PNN两神经网络实现并比较鸢尾花种类识别正确率、各个模型运行时间对比—Jason niu
load iris_data.mat P_train = []; T_train = []; P_test = []; T_test = []; for i = 1:3 temp_input = fe ...
- NN:实现BP神经网络的回归拟合,基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat plot(NIR') title('Near infrared spectrum curve—Jason niu') temp = randperm(siz ...
- TF之AE:AE实现TF自带数据集数字真实值对比AE先encoder后decoder预测数字的精确对比—Jason niu
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #Import MNIST data from t ...
- PCA:利用PCA(四个主成分的贡献率就才达100%)降维提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- Tensorflow&CNN:验证集预测与模型评价
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/90480140 - 写在前面 本科毕业设计终于告一段落了.特 ...
- SVM—PK—BP:SVR(better)和BP两种方法比较且实现建筑物钢筋混凝土抗压强度预测—Jason niu
load concrete_data.mat n = randperm(size(attributes,2)); p_train = attributes(:,n(1:80))'; t_train = ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
随机推荐
- LuoGu P1004 方格取数
题目传送门 一开始这个题我是不会的(沙华弱DP啊QwQ),后来考完试我一想,这东西怎么和数字三角形那题这么像啊? 都是自上而下,只能向下或者向右,求一个max 那么...这不就是个走两遍的数字矩阵嘛 ...
- ORA-00379: no free buffers available in buffer pool DEFAULT for block size 16K
SYS@orcl> select TABLESPACE_NAME ,AUTOEXTENSIBLE from dba_data_files ; ERROR: ORA-00379: no free ...
- LeetCode(72):编辑距离
Hard! 题目描述: 给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 . 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换 ...
- medir设置
setting中 MEDIA_URL="/media/"MEDIA_ROOT=os.path.join(BASE_DIR, "app01","medi ...
- OpenCV-Python入门教程6-Otsu阈值法
在说Otsu之前,先说几个概念 灰度直方图:将数字图像中的所有像素,按照灰度值的大小,统计其出现的频率.其实就是每个值(0~255)的像素点个数统计. Otsu算法假设这副图片由前景色和背景色组成,通 ...
- 查看CPU 内存 硬盘 网络 查看进程使用的文件 uptime top ps -aux vmstat iostat iotop nload iptraf nethogs
#安装命令 yum install sysstat #包含 iostat vmstat yum install iotop yum install nload yum install iptraf ...
- SHELL打印两个日期之间的日期
SHELL打印两个日期之间的日期 [root@umout shell]# cat date_to_date.sh THIS_PATH=$(cd `dirname $0`;) cd $THIS_PATH ...
- 【专栏学习】APM——异步编程模型(.NET不推荐)
(1)learning hard C#学习笔记 异步1:<learning hard C#学习笔记>读书笔记(20)异步编程 (2)<C# 4.0 图解教程> 22.4 异步编 ...
- 为tomcat8安装Native library
安装依赖包 yum install -y cmake gcc expat-devel perl wget 安装apr wget http://mirrors.hust.edu.cn/apache//a ...
- ES标准
精确来说,ES1 ~ ES5 中的数字是 ECMA-262 标准的版本号(edition). 即:Standard ECMA-262, 1st Edition(其实第一个版本是没有版本号的)Stand ...