Flume的概述和安装部署
一、Flume概述
Flume是一种分布式、可靠且可用的服务,用于有效的收集、聚合和移动大量日志文件数据。Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有强大的容错能力。Flume使用简单的的可扩展数据模型,循环在线分析应用程序。
二、Flume的作用
数据的来源大致有三类:
1.爬虫
2.日志数据 =>使用Flume进行获取传输
3.传统数据库 =>使用Sqoop进行数据迁移
三、Flume架构
1.source:数据源
接收webser端的数据,产生数据流
同时source将产生数据流传输到channel
2.channel:传输管道
用于桥接source和sinks
3.sinks:下沉
从channel接收数据,并传输到hdfs或下一个agent
4.agent:代理
一个agent中包含一组source,channel,sinks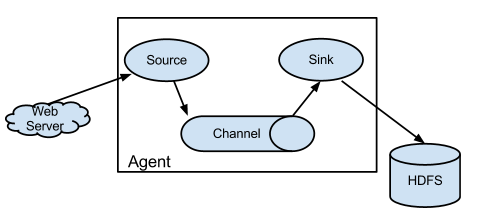
四、Flume的安装部署
1.从官网下载flume安装包(本人使用的是1.6.0版本)
2.上次到linux中解压
tar -zxvf ***.tar
3.重命名解压缩的文件夹为flume,方便以后更新维护
4.进去flume下的conf文件夹,将文件flume-env.sh.template重命名为flume-env.sh
5.进去该文件,删除java_home的注释,并修改java路径为本机的java_home路径
export JAVA_HOME=/root/hd/jdk1.8.0_102
6.保存并退出,安装完成!
Flume的概述和安装部署的更多相关文章
- HBase的概述和安装部署
一.HBase概述 1.HBase是Hadoop数据库,是一个分布式.可扩展的大数据存储. HBase是用于对大数据进行随机.实时读写访问的非关系型数据库,它的目标托管非常大的表——数十亿行N百万列. ...
- Kafka概述及安装部署
一.Kafka概述 1.Kafka是一个分布式流媒体平台,它有三个关键功能: (1)发布和订阅记录流,类似于消息队列或企业消息传递系统: (2)以容错的持久方式存储记录流: (3)记录发送时处理流. ...
- Zookeeper的概述、安装部署及选举机制
一.Zookeeper概述 1.Zookeeper是Hadoop生态的管理者,它致力于开发和维护开源服务器,实现高度可靠的分布式协调. 2.Zookeeper的两大功能: (1)存储数据 (2)监听 ...
- Spark-Unit1-spark概述与安装部署
一.Spark概述 spark官网:spark.apache.org Spark是用的大规模数据处理的统一计算引擎,它是为大数据处理而设计的快速通用的计算引擎.spark诞生于加油大学伯克利分校AMP ...
- 1.1-1.5 flume架构概述及安装使用
一.flume架构概述 1.flume简介 Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据.它具有基于流数据流的简单灵活的架构.它具有可靠的可靠性机制和许多故障转移和 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- Kubernetes后台数据库etcd:安装部署etcd集群,数据备份与恢复
目录 一.系统环境 二.前言 三.etcd数据库 3.1 概述 四.安装部署etcd单节点 4.1 环境介绍 4.2 配置节点的基本环境 4.3 安装部署etcd单节点 4.4 使用客户端访问etcd ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
随机推荐
- STM32L476应用开发之三:串行通讯实验
在我们的项目需求中,有两个串口应用需求,一个是与炭氢传感器的通讯,另一个是与显示屏的通讯.鉴于此,我们需要实验串行通讯. 1.硬件设计 串行通讯一个采用RS232接口,另一个直接采用TTL方式.我们在 ...
- Confluence 6 Oracle 测试你的数据库连接
在你的数据库设置界面,有一个 测试连接(Test connection)按钮可以检查: Confluence 可以连接你的数据库服务器 数据库的字符集编码是否正确 你的数据库用户是否具有需要的权限 你 ...
- Java语法基础常见疑惑解答8,16,17,21图片补充
8. 16. 17. 21
- 通过$broadcast或$emit在子级和父级controller之间进行值传递
通过$broadcast或$emit在controller之间进行值传递,不过这些controller必须是子级或者父级关系, $emit只能向父级parent controller传递事件event ...
- Python基础之面向对象进阶一
一.isinstance(obj,cls)和issubclass(sub,super) 1.isinstance(obj,cls)检查obj是否是类 cls 的对象 class A: pass obj ...
- eclipse创建动态maven项目
需求表均同springmvc案例 此处只是使用maven 注意,以下所有需要建立在你的eclipse等已经集成配置好了maven了,说白了就是新建项目的时候已经可以找到maven了 没有的话需要安装m ...
- less 写关键帧动画
@keyframes 关键帧动画写在less里的时候,务必要写在所有的{}之外,不能被{}包裹 甚至务必写在代码的最后 不然报错 Compilation resulted in incorrect C ...
- Python函数之递归函数
递归函数的定义:在这个函数里再调用这个函数本身 最大递归深度默认是997或者998,python从内存角度做的限制 优点:代码变简单 缺点:占内存 一:推导年龄 问a的值是多少: a 比 b 小2,b ...
- Python(列表操作应用实战)
# 输入一个数据,删除一个列表中的所有指定元素# 给定的列表数据data = [1,2,3,4,5,6,7,8,9,0,5,4,3,5,"b","a",&quo ...
- linux 系统备份和恢复
Linux不像windows,它不限制根用户存取任何东西,因此,你完全可以把一个分区上每一个的文件放入一个TAR文件中. 使用root用户切换到根目录 然后,使用下面的命令备份完整的系统: tar c ...