洗礼灵魂,修炼python(89)-- 知识拾遗篇 —— 进程
进程
1.含义:计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。说白了就是一个程序的执行实例。
执行一个程序就是一个进程,比如你打开浏览器看到我的博客,浏览器本身是一个软件程序,你此时打开的浏览器就是一个进程。
2.进程的特性
一个进程里可以有多个子进程
新的进程的创建是完全拷贝整个主进程
进程里可以包含线程
进程之间(包括主进程和子进程)不存在数据共享,相互通信(浏览器和python之间的数据不能互通的),要通信则要借助队列,管道之类的
3.进程和线程之间的区别
线程共享地址空间,而进程之间有相互独立的空间
线程之间数据互通,相互操作,而进程不可以
新的线程比新的进程创建简单,比开进程的开销小很多
主线程可以影响子线程,而主进程不能影响子进程
4.在python中,进程与线程的用法就只是名字不同,使用的方法也是没多大区别
5.简单实例
1)创建一个简单的多进程:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing,time
def func(name):
time.sleep(1)
print('hello',name,time.ctime())
ml = []
for i in range(3):
p = multiprocessing.Process(target=func,args=('yang',))
p.start()
ml.append(p)
for i in ml:
i.join() #注意这里,进程必须加join方法,不然会导致僵尸进程
运行结果:
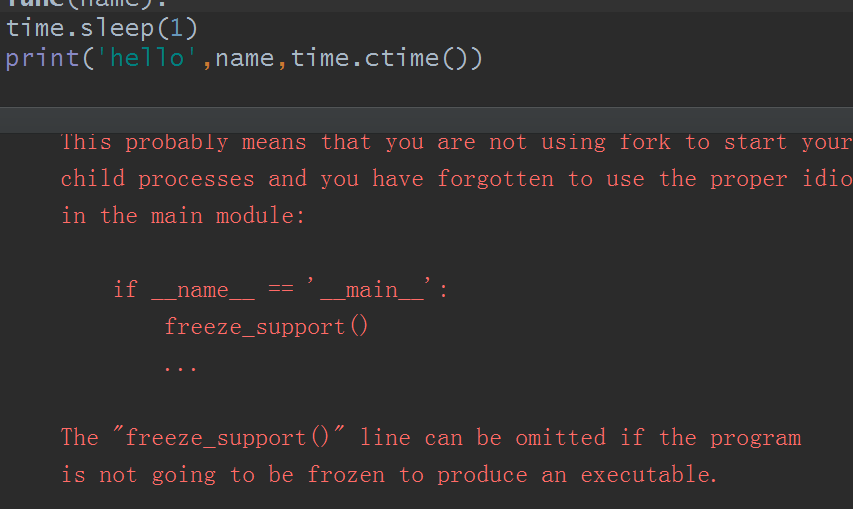
不管怎么说,反正报错了,同样的代码,在python自带的IDLE里试试:
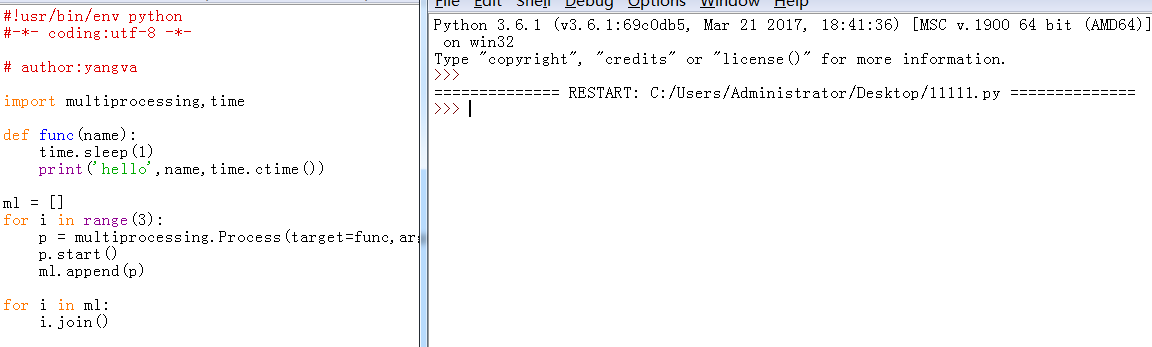
没有任何东西就结束了。好的,这里要说下了,按照我个人的理解,当你用pycharm或者IDLE时,pycharm或者IDLE在你的电脑里本身也是一个进程,并且默认是主进程。所以在pycharm会报错,而在IDLE里运行就是空白,个人理解,对不对暂且不谈,后期学到子进程时再说。
解决办法就是,其他的不变,加一个if __name == '__main__'判断就行:
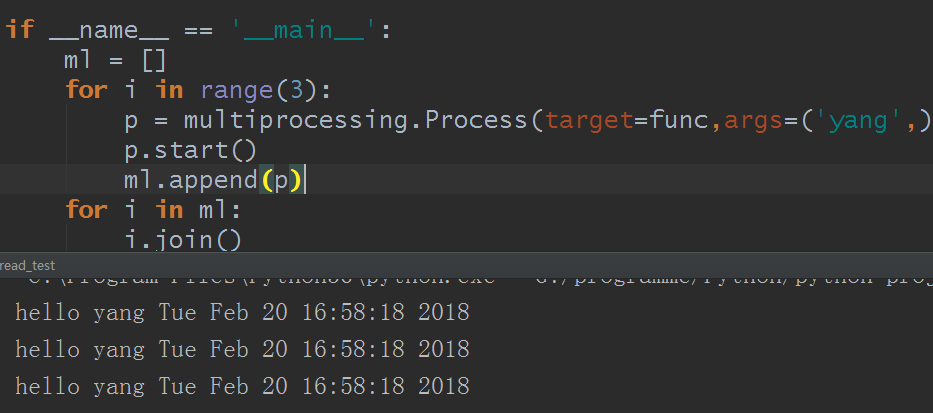
这样就解决了,好的,你现在可以体会到那句话了,进程与线程的用法就只是名字不同,使用的方法也是没多大区别。不多说,自行体会。而运行结果看到的时间是同步的,那么这进程才是真正意义上的并行运行。
2)自定义类式进程
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing,time
class myprocess(multiprocessing.Process):
def __init__(self,name):
super(myprocess,self).__init__()
self.name = name
def run(self):
time.sleep(1)
print('hello',self.name,time.ctime())
if __name__ == '__main__':
ml = []
for i in range(3):
p = myprocess('yang')
p.start()
ml.append(p)
for j in ml:
j.join()
运行结果:
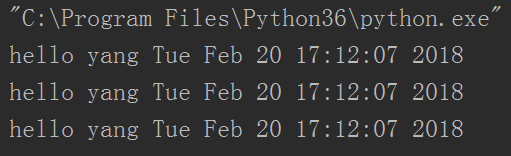
然后setDaemon之类的方法和线程也是完全一致的。
3)每一个进程都有根进程,换句话,每一个进程都有父进程
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing,time,os
def info():
print('mudule name:',__name__)
print('parent process:',os.getppid()) #父进程号
print('son process:',os.getpid()) #子进程号
if __name__ == '__main__':
info()
print('-----')
p = multiprocessing.Process(target=info,args=[])
p.start()
p.join()
运行结果:
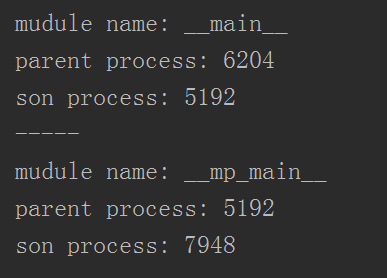
而查看我本机的进程:
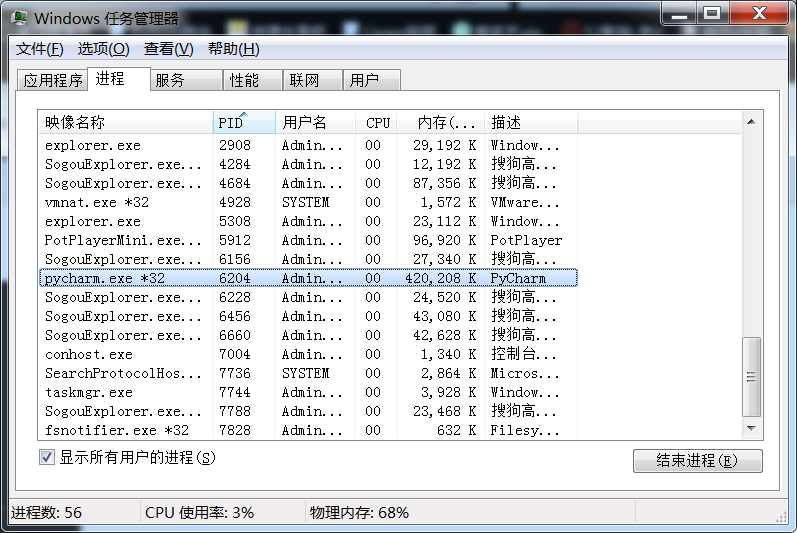
可以知道,6204就是pycharm,正是此时的根进程,而主进程就是我这个py文件(由__main__可知),接着再往下的子进程等等等的。
6.多进程间的通信和数据共享
首先我们都已经知道进程之间是独立的,不可以互通,并且数据相互独立,而在实际开发中,一定会遇到需要进程间通信的场景要求,那么我们怎么搞呢
有两种方法:
- pipe
- queue
1)使用queue通信
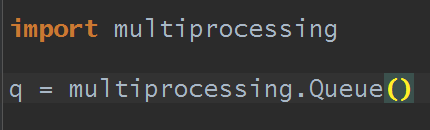
在多线程那里已经学过queue了,创建queue的方式,q = queue.Queue(),这种创建是创建的线程queue,并不是进程queue。创建进程queue的方式是:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing
def func(q,name,age): #这里必须要把q对象作为参数传入才能实现进程之间通信
q.put({'name':name,'age':age})
if __name__ == '__main__':
q = multiprocessing.Queue() #创建进程queue对象
ml = []
for i in range(3):
p = multiprocessing.Process(target=func,args=(q,'yang',21))
p.start()
ml.append(p)
print(q.get()) #获取queue信息
print(q.get())
print(q.get())
for i in ml:
i.join()
运行结果:

好的,已经通过queue实现通信,那么细心的朋友可能会想,此时的queue到底是同一个呢还是copy的呢?开始测试,码如下:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing
def func(q,name,age):
q.put({'name':name,'age':age})
print('id:',id(q))
if __name__ == '__main__':
q = multiprocessing.Queue()
ml = []
print('id:',id(q))
for i in range(3):
p = multiprocessing.Process(target=func,args=(q,'yang',21))
p.start()
ml.append(p)
print(q.get())
print(q.get())
print(q.get())
for i in ml:
i.join()
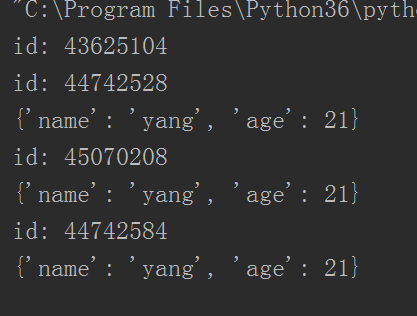
在Windows平台运行结果:
Linux的ubuntu下是这样的:
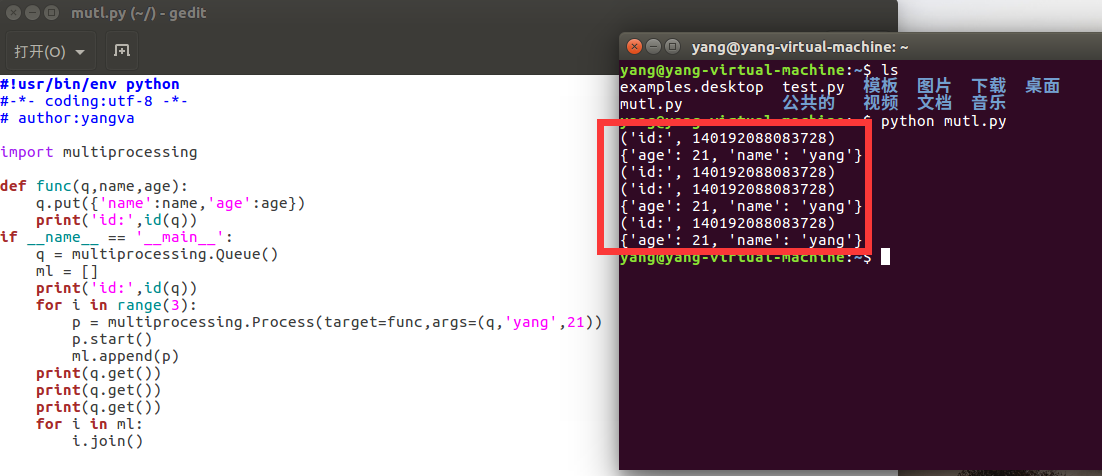
这就不好怎么说了,我个人的理解,线程和进程这类与电脑硬件(CPU,RAM)等有联系的都有不确定因素,姑且认为在Windows平台里queue是copy的,在Linux里是同一个吧,并且据经验人士表示,在macbook上也是同一个。
还有个问题, 假如使用的queue是线程式的呢?
代码其他都没变,只改了这里:
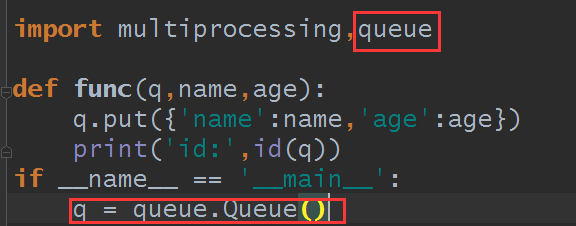
结果:
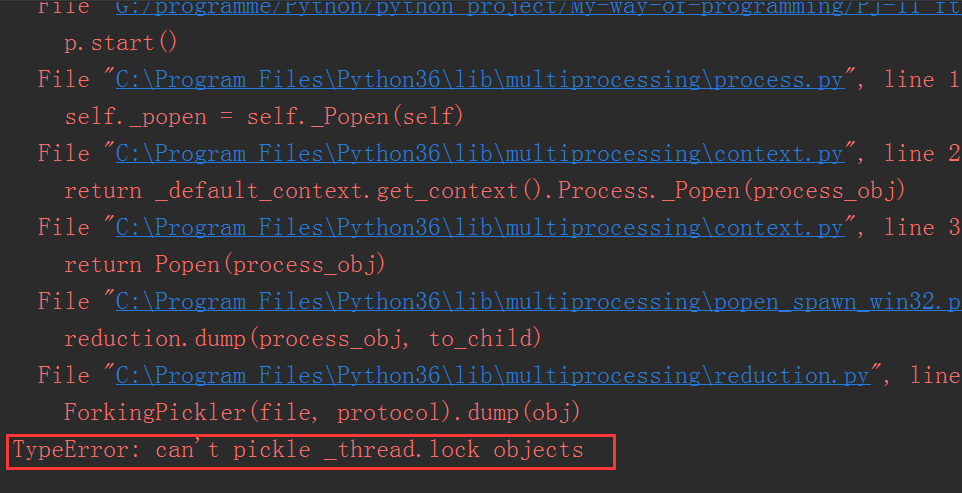
虽然报错了,但是却有一个关键点,提示的是不能pickle线程锁对象,也就是说刚才我们使用的queue是进程对象,所以可以pickle,注意了,这里就是关键点,使用了pickle,那么也就是说,在Windows平台里是copy的,如果不是copy,就不需要存在pickle对吧?直接拿来用就是啊,干嘛要pickle之后取的时候再反pickle呢对吧?
再看Linux下呢,由于Linux默认是python2,所以模块包名稍微有点不同
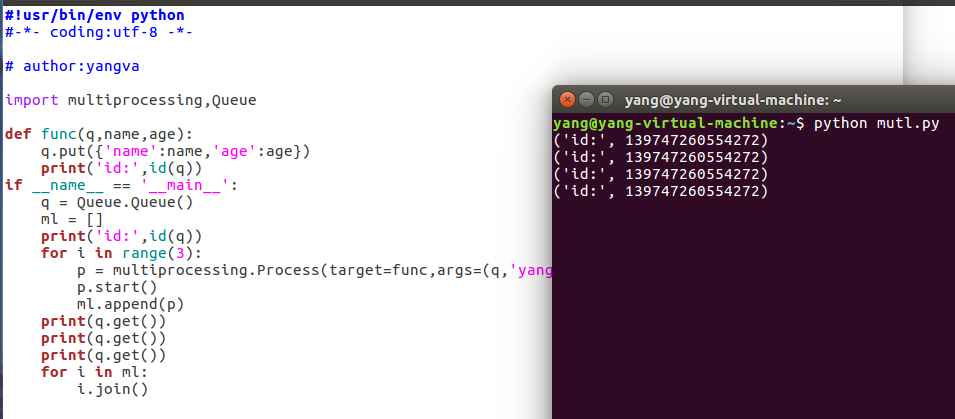
结果阻塞住了,但是前面的还是出来了,看到的id果然还是一样的。
这里就有三点需要注意:(个人理解,如有误望指正)
1.进程里的确不能使用线程式queue
2.Windows平台的进程式queue是copy的
3.Linux平台的线程式和进程式都是同一个,但是如果在进程里使用线程式queue会阻塞住
但我个人觉得copy更有安全性
2)使用pipe通信
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing
def func(conn):
conn.send('约吗?') #子进程发送数据
print(conn.recv()) #接受数据,不能加参数1024之类的
conn.close() #子进程关闭连接
if __name__ == '__main__':
parent_conn,son_conn = multiprocessing.Pipe() #创建pipe对象,父进程,子进程
ml = []
p = multiprocessing.Process(target=func,args=(son_conn,))
p.start()
print(parent_conn.recv()) #父进程接受数据,不能加参数1024之类的
parent_conn.send('不约') #发送数据
p.join() #join方法是进程特有
运行结果:

这样就联系上了,相信你发现了,基本和前面的socket差不多,不过唯一的不同是recv()方法不能加参数,不信的话,你加来试试
反观线程通信,相信你会觉得进程比线程更方便
当然pipe也可以有多个:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing,time
def func(conn):
conn.send('约吗?') #子进程发送数据
print(conn.recv())
conn.close() #子进程关闭连接
if __name__ == '__main__':
parent_conn,son_conn = multiprocessing.Pipe() #创建pipe对象,父进程,子进程
ml = []
for i in range(3):
p = multiprocessing.Process(target=func,args=(son_conn,))
p.start()
ml.append(p)
print(parent_conn.recv()) #父进程接受数据,不能加参数1024之类的
parent_conn.send('不约')
for i in ml:
i.join()
运行结果:

7.进程之间数据共享——manager
比较简单,就利用了进程里的manager对象下的各个数据类型,其他的很简单的,我就不注释了
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import multiprocessing
def func(l,d,num):
l.append(num)
d[num] = num
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
l = manager.list()
d = manager.dict()
ml = []
for i in range(6):
p = multiprocessing.Process(target=func,args=(l,d,i))
p.start()
ml.append(p)
for i in ml:
i.join()
print('d:',d)
print('l:',l)
运行结果:
这样是不是就实现了数据共享了?
好的,进程也解析完了
洗礼灵魂,修炼python(89)-- 知识拾遗篇 —— 进程的更多相关文章
- 洗礼灵魂,修炼python(85)-- 知识拾遗篇 —— 深度剖析让人幽怨的编码
编码 这篇博文的主题是,编码问题,老生常谈的问题了对吧?从我这一套的文章来看,前面已经提到好多次编码问题了,的确这个确实很重要,这可是难道了很多能人异士的,当你以为你学懂了,在研究爬虫时你发现你错了, ...
- 洗礼灵魂,修炼python(91)-- 知识拾遗篇 —— pymysql模块之python操作mysql增删改查
首先你得学会基本的mysql操作语句:mysql学习 其次,python要想操作mysql,靠python的内置模块是不行的,而如果通过os模块调用cmd命令虽然原理上是可以的,但是还是不太方便,那么 ...
- 洗礼灵魂,修炼python(87)-- 知识拾遗篇 —— 线程(1)
线程(上) 1.线程含义:一段指令集,也就是一个执行某个程序的代码.不管你执行的是什么,代码量少与多,都会重新翻译为一段指令集.可以理解为轻量级进程 比如,ipconfig,或者, python ...
- 洗礼灵魂,修炼python(84)-- 知识拾遗篇 —— 网络编程之socket
学习本篇文章的前提,你需要了解网络技术基础,请参阅我的另一个分类的博文:网络互联技术(4)——计算机网络常识.原理剖析 网络通信要素 1.IP地址: 用来标识网络上一台独立的终端(PC或者主机) ip ...
- 洗礼灵魂,修炼python(90)-- 知识拾遗篇 —— 协程
协程 1.定义 协程,顾名思义,程序协商着运行,并非像线程那样争抢着运行.协程又叫微线程,一种用户态轻量级线程.协程就是一个单线程(一个脚本运行的都是单线程) 协程拥有自己的寄存器上下文和栈.协程调度 ...
- 洗礼灵魂,修炼python(88)-- 知识拾遗篇 —— 线程(2)/多线程爬虫
线程(下) 7.同步锁 这个例子很经典,实话说,这个例子我是直接照搬前辈的,并不是原创,不过真的也很有意思,请看: #!usr/bin/env python #-*- coding:utf-8 -*- ...
- Python基础知识拾遗
彻底搞清楚python字符编码 python的super函数
- python基础知识第一篇(认识Python)
开发语言: 高级语言:python java php c++ 生成的字节码 字节码转换为机器码 计算机识别运行 低级语言:C 汇编 生成的机器码 PHP语言:适用于网页,局限性 Python,Java ...
- python基础知识第九篇(函数)
函数 >>>>>>>>>>> : 使用函数的好处 1.代码重用 2.保持一致性,方便维护 3.可扩展性 定义方法 def test01 ...
随机推荐
- 深入理解 JavaScript 异步系列(1)——基础
前言 2014年秋季写完了<深入理解javascript原型和闭包系列>,已经帮助过很多人走出了 js 原型.作用域.闭包的困惑,至今仍能经常受到好评的留言. 很早之前我就总结了JS三座大 ...
- linux 命令 — find
find 基本形式 find base_path base_path可以是任何目录,find会从该目录开始往下寻找 find . -print 列出当前目录下所有的文件和目录,以'\n'作为分隔符 f ...
- FFmpeg中overlay滤镜用法-水印及画中画
本文为作者原创,转载请注明出处:https://www.cnblogs.com/leisure_chn/p/10434209.html 1. overlay技术简介 overlay技术又称视频叠加技术 ...
- 分享一个爬取HUST(哈理工)学生成绩的Python程序(OCR自动识别验证码)
Python版本:3.5.2 日期:2018/1/21 __Author__ = "Lance#" # -*- coding = utf-8 -*- from urllib imp ...
- NTP时间服务器实战应用详解-技术流ken
简介 在搭建集群服务中,要保证各节点时间一致,NTP时间服务器就成为了一个好帮手了. 系统环境 系统版本:centos6.7 服务器IP:10.220..5.166/24 客户端IP:10.220.5 ...
- spark之JDBC开发(实战)
一.概述 Spark Core.Spark-SQL与Spark-Streaming都是相同的,编写好之后打成jar包使用spark-submit命令提交到集群运行应用$SPARK_HOME/bin#. ...
- phpmyadmin创建mysql的存储过程
通过phpmyadmin ,创建procedure, 用于生成测试数据. 随机的用户名及手机号. DELIMITER $$ CREATE PROCEDURE `sp_insert_test_users ...
- C++程序实例唯一方案,窗口只打开一次,程序只打开一次
首先是方法: // IsAlreadyRunning - 是否已经运行 BOOL IsAlreadyRunning() { BOOL bRet = FALSE; HANDLE hMutex = ::C ...
- C#.NET和C++结构体Socket通信与数据转换
最近在用C#做一个项目的时候,Socket发送消息的时候遇到了服务端需要接收C++结构体的二进制数据流,这个时候就需要用C#仿照C++的结 构体做出一个结构来,然后将其转换成二进制流进行发送,之后将响 ...
- [android] 采用服务录制电话&服务的生命周期
根据上一节代码里,加入一个录音功能,上传到服务器,就能实现一个录制器 当手机处于通话状态时,开启录音机 获取MediaRecorder对象,通过new出来 调用MediaRecorder对象的setA ...