爬取猫眼电影TOP100
本文所讲的爬虫项目实战属于基础、入门级别,使用的是Python3.5实现的。
本项目基本目标:在猫眼电影中把top100的电影名,排名,海报,主演,上映时间,评分等爬取下来
爬虫原理和步骤
爬虫,就是从网页中爬取自己所需要的东西,如文字、图片、视频等,这样我们就需要读取网页,然后获取网页源代码,从源代码中用正则表达式进行匹配,把匹配成功的信息存入相关文档中。这就是爬虫的简单原理。
操作步骤:
1.确定抓取的数据字段(排名,海报,电影名,主演,上映时间,评分)
2.分析页面html标签结构,找到数据所在位置
3.选择实现方法及数据存储位置(存在在mysql 数据库中)
4.代码写入(requests+re+pymysql)
5.代码调试
确定抓取的页面目标URL:http://maoyan.com/board/4
1.导入库/模块
import re
import requests
import pymysql
from requests.exceptions import RequestException #捕获异常
2.请求头域,在网页中查看headers,复制User-Agent内容
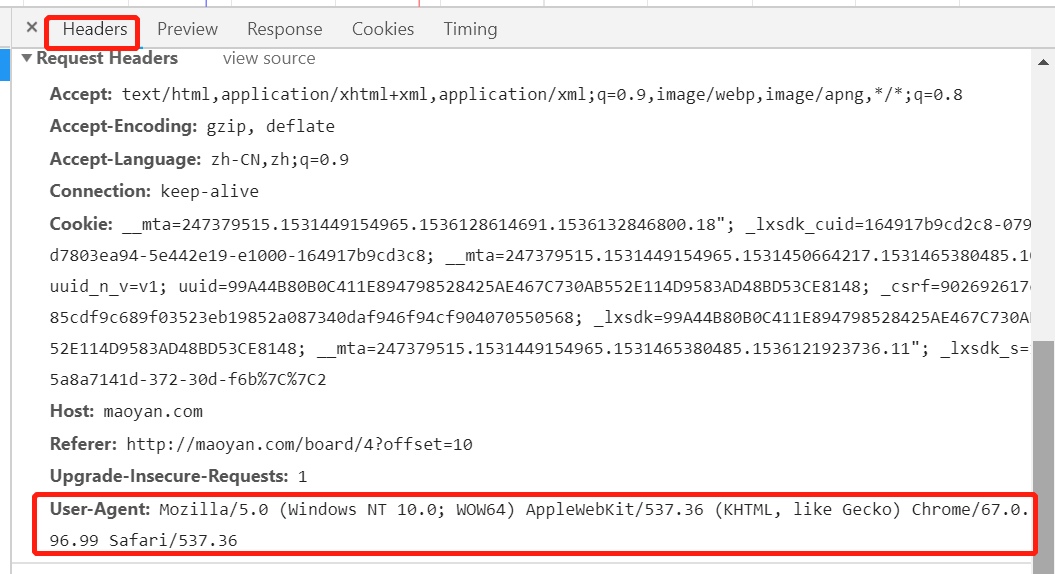
请求一个单页内容拿到HTML,定义函数,构建headers,请求成功则代码为200,否则失败重新写入代码
def get_one_page(url):
try:
#构建headers
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.text
except RequestException:
return '请求异常'
3.解析HTML,用正则表达式匹配字符,为非贪婪模式.*?匹配
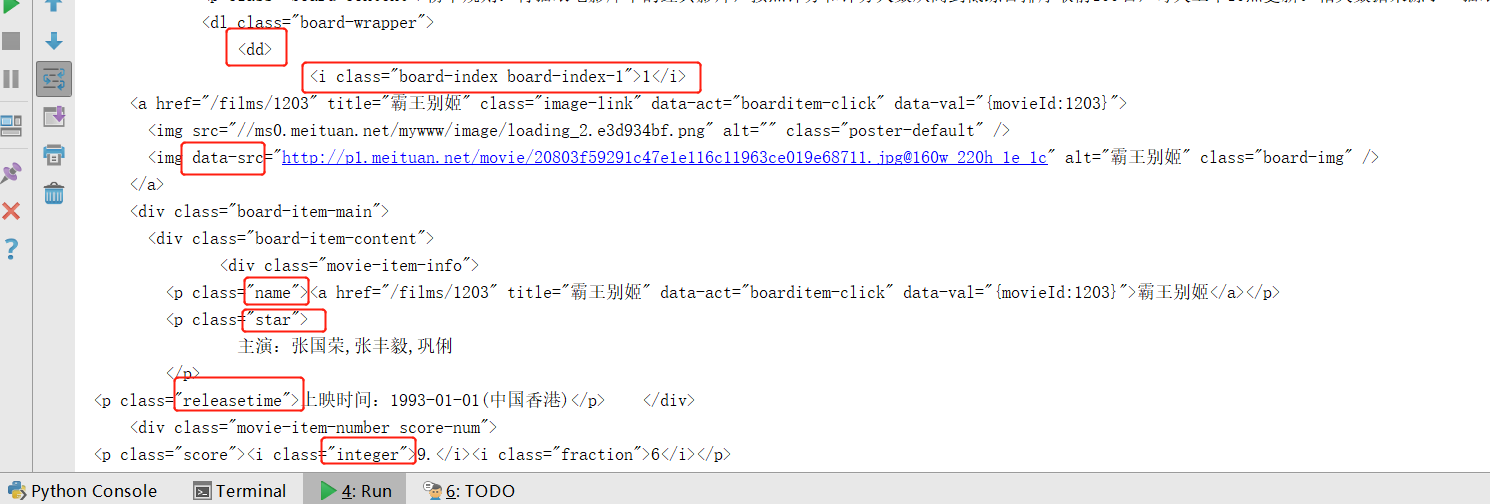
def parse_one_page(html):
# 创建一个正则表达式对象
#使用re.S可以使元字符.匹配到换行符
pattern=re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name">'
+ '<a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
# print(items)
运行已经匹配好的第一页内容
运行结果没有处理的如下:

4.进行数据处理,格式美化,按字段依次排列,去掉不必要的空格符
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:], # strip():删除前后空白
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
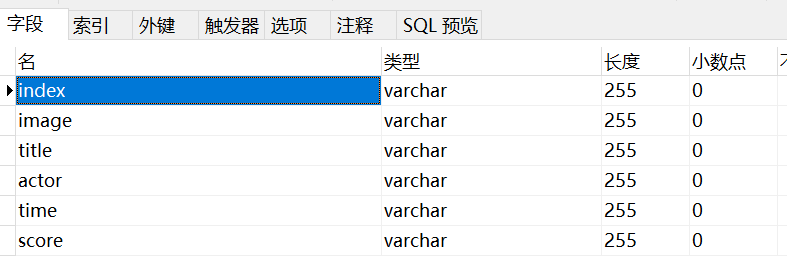
5.创建MySQL数据库,库名movie1表名maoyan,添加我们爬取的6个字段名
6.在python中创建数据库连接,把爬取的数据存储到MySQL
def write_to_mysql(content):
conn=pymysql.connect(host='localhost',user='root',passwd='',
db='movie1',charset='utf8')
cursor=conn.cursor()
index=content['index']
image=content['image']
title=content['title']
actor=content['actor']
time=content['time']
score=content['score']
sql='insert into maoyan values(%s,%s,%s,%s,%s,%s)'
parm=(index,image,title,actor,time,score)
cursor.execute(sql,parm)
conn.commit()
cursor.close()
conn.close()
调用主函数,运行后得到结果如下:


以上为调取的一页数据,只有TOP10的电影排名,如果需要得到TOP100,则要重新得到URL来构建
第一页的URL为:http://maoyan.com/board/4
第二页的URL为:http://maoyan.com/board/4?offset=10
第三页的URL为:http://maoyan.com/board/4?offset=20
得到页面都是以10来递增URL为:
url='http://maoyan.com/board/4?offset='+str(offset)
需要循环10次即可得到排名前100的电影,并把它写入到数据库中
def main(offset):
url='http://maoyan.com/board/4?offset='+str(offset)
html=get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_mysql(item) if __name__=='__main__':
for i in range(0,10):
main(i*10)
运行后进入MySQL查看写入的数据
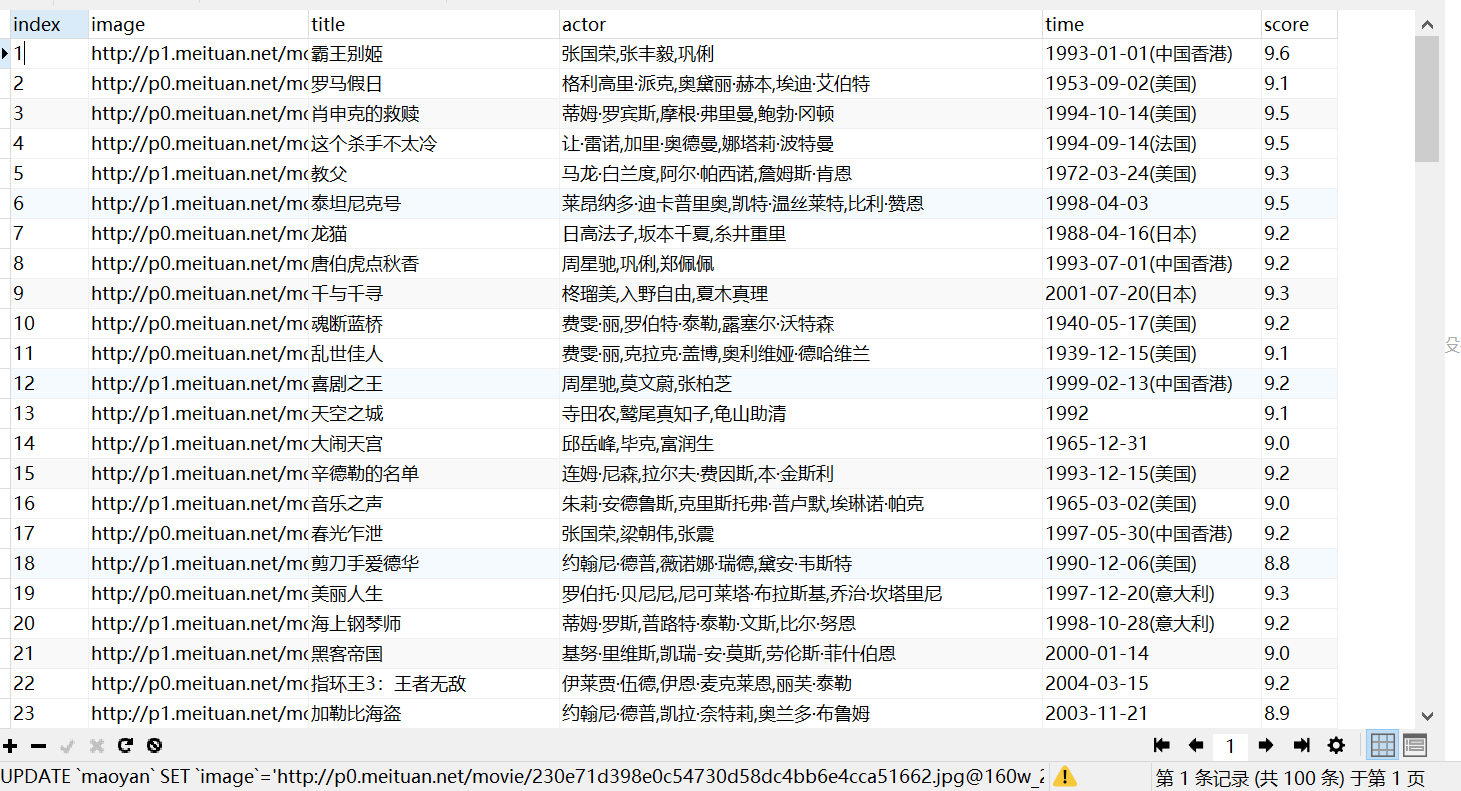
以上是爬取猫眼top100完整代码,如有错误请多指教。
爬取猫眼电影TOP100的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- # 爬虫连载系列(1)--爬取猫眼电影Top100
前言 学习python有一段时间了,之前一直忙于学习数据分析,耽搁了原本计划的博客更新.趁着这段空闲时间,打算开始更新一个爬虫系列.内容大致包括:使用正则表达式.xpath.BeautifulSoup ...
- python应用-爬取猫眼电影top100
import requests import re import json import time from requests.exceptions import RequestException d ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
随机推荐
- bzoj 2806 [Ctsc2012]Cheat——广义后缀自动机+单调队列优化DP
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=2806 只想着怎么用后缀数据结构做,其实应该考虑结合其他算法. 可以二分那个长度 L .设当前 ...
- Spring 4 中重定向RedirectAttributes的使用
RedirectAttributes 的使用 @RequestMapping(value = "/redirecttest", produces = "applicati ...
- Centos 7 systemctl和防火墙firewalld命令
今天自己在Hyper-v下搭建三台Linux服务器集群,用于学习ELKstack(即大数据日志解决技术栈Elasticsearch,Logstash,Kibana的简称),下载的Linux版本为cen ...
- VGA原理
VGA原理 1.VGA时序 2.不同的显示标准,有不同的水平段和垂直段 3.像素时钟和帧频的关系 联系目前调试的1080i 50Hz: 像素时钟为148.5MHz, 水平段周期 = 2640 X (1 ...
- 使用Vivado的block design
使用Vivado的block design (1)调用ZYNQ7 Processing System (2)配置ZYNQ7系统 (3)外设端口配置 根据开发板原理图MIO48和MIO49配置成了串口通 ...
- Django 链接mysql
第一步:settings.py DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'testdjango ...
- 卸载QQ,360,迅雷,搜狗
如题. 以及一切中国的流行软件. 这帮家伙都不是一个人,后面都跟着一帮子助手,杀毒,自我保护,管家,桌面,播放器,等等等等,你也不知道电脑速度为什么会这么慢,但是他变慢了. 今天头天用 360优化速度 ...
- ALGO-118_蓝桥杯_算法训练_连续正整数的和
问题描述 78这个数可以表示为连续正整数的和,++,+++,++. 输入一个正整数 n(<=) 输出 m 行(n有m种表示法),每行是两个正整数a,b,表示a+(a+)+...+b=n. 对于多 ...
- 【linux】之Centos6.x升级glibc
因为Centos比较保守依赖的glibc最高版本是2.12 rpm -qa|grep glibc strings /lib64/libc.so. |grep GLIBC_ 但是经常我们安装一些源码包, ...
- pyqt4 利用信号槽在子线程里面操作Qt界面
转载:ABigCaiBird #-*- coding:utf-8 -*- ####### from PyQt4.QtCore import * from PyQt4.QtGui import * im ...