Kafka 温故(五):Kafka的消费编程模型
Kafka的消费模型分为两种:
1.分区消费模型
2.分组消费模型
一.分区消费模型
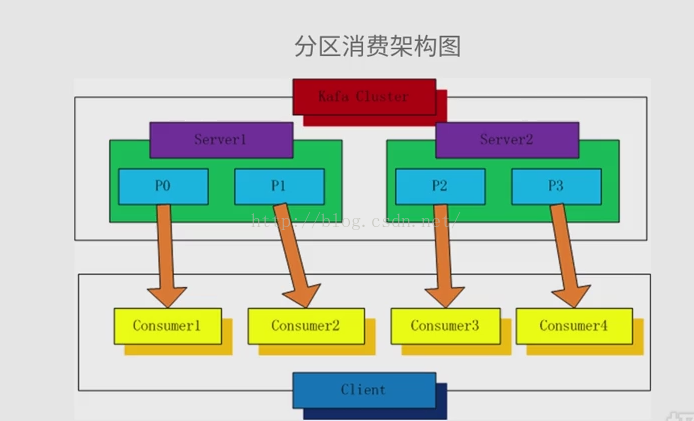
二、分组消费模型

Producer :
package cn.outofmemory.kafka; import java.util.Properties; import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig; /**
* Hello world!
*
*/
public class KafkaProducer
{
private final Producer<String, String> producer;
public final static String TOPIC = "TEST-TOPIC"; private KafkaProducer(){
Properties props = new Properties();
//此处配置的是kafka的端口
props.put("metadata.broker.list", "192.168.193.148:9092"); //配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
//配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder"); //request.required.acks
//0, which means that the producer never waits for an acknowledgement from the broker (the same behavior as 0.7). This option provides the lowest latency but the weakest durability guarantees (some data will be lost when a server fails).
//1, which means that the producer gets an acknowledgement after the leader replica has received the data. This option provides better durability as the client waits until the server acknowledges the request as successful (only messages that were written to the now-dead leader but not yet replicated will be lost).
//-1, which means that the producer gets an acknowledgement after all in-sync replicas have received the data. This option provides the best durability, we guarantee that no messages will be lost as long as at least one in sync replica remains.
props.put("request.required.acks","-1"); producer = new Producer<String, String>(new ProducerConfig(props));
} void produce() {
int messageNo = 1000;
final int COUNT = 10000; while (messageNo < COUNT) {
String key = String.valueOf(messageNo);
String data = "hello kafka message " + key;
producer.send(new KeyedMessage<String, String>(TOPIC, key ,data));
System.out.println(data);
messageNo ++;
}
} public static void main( String[] args )
{
new KafkaProducer().produce();
} }
Consumer
package cn.outofmemory.kafka; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties; import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties; public class KafkaConsumer { private final ConsumerConnector consumer; private KafkaConsumer() {
Properties props = new Properties();
//zookeeper 配置
props.put("zookeeper.connect", "192.168.193.148:2181"); //group 代表一个消费组
props.put("group.id", "jd-group"); //zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
//序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder"); ConsumerConfig config = new ConsumerConfig(props); consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
} void consume() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(KafkaProducer.TOPIC, new Integer(1)); StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties()); //获取到的输入流
Map<String, List<KafkaStream<String, String>>> consumerMap =
consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
KafkaStream<String, String> stream = consumerMap.get(KafkaProducer.TOPIC).get(0);
ConsumerIterator<String, String> it = stream.iterator();
//输出接受到的消息
while (it.hasNext())
System.out.println(it.next().message());
} public static void main(String[] args) {
new KafkaConsumer().consume();
}
}
kafka 学习告一段落,后面进入的为Spring 温习。
Kafka 温故(五):Kafka的消费编程模型的更多相关文章
- Kafka 温故(二):Kafka的基本概念和结构
一.Kafka中的核心概念 Producer: 特指消息的生产者Consumer :特指消息的消费者Consumer Group :消费者组,可以并行消费Topic中partition的消息Broke ...
- Storm集成Kafka编程模型
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3974417.html 本文主要介绍如何在Storm编程实现与Kafka的集成 一.实现模型 数据流程: ...
- Kafka 通过python简单的生产消费实现
使用CentOS6.5.python3.6.kafkaScala 2.10 - kafka_2.10-0.8.2.2.tgz (asc, md5) 一.下载kafka 下载地址 https://ka ...
- kafka的编程模型
1.kafka消费者编程模型 分区消费模型 组(group)消费模型 1.1.1.分区消费架构图,每个分区对应一个消费者. 1.1.2.分区消费模型伪代码描述 指定偏移量,用于从上次消费的地方开始消费 ...
- kafka架构,消息存储和生成消费模型,Kafka与其他队列对比,零拷贝,Kafka基本介绍
kafka架构,消息存储和生成消费模型,Kafka与其他队列对比,零拷贝,Kafka基本介绍 一.初识kafka 1.1SparkStreaming+Kafka好处: 1.2Kafka的架构: 二.k ...
- Kafka具体解释五、Kafka Consumer的底层API- SimpleConsumer
1.Kafka提供了两套API给Consumer The high-level Consumer API The SimpleConsumer API 第一种高度抽象的Consumer API,它使用 ...
- Kafka详解五:Kafka Consumer的底层API- SimpleConsumer
问题导读 1.Kafka如何实现和Consumer之间的交互?2.使用SimpleConsumer有哪些弊端呢? 1.Kafka提供了两套API给Consumer The high-level Con ...
- Kafka创建&查看topic,生产&消费指定topic消息
启动zookeeper和Kafka之后,进入kafka目录(安装/启动kafka参考前面一章:https://www.cnblogs.com/cici20166/p/9425613.html) 1.创 ...
- kafka创建topic,生产和消费指定topic消息
启动zookeeper和Kafka之后,进入kafka目录(安装/启动kafka参考前面一章:https://www.cnblogs.com/cici20166/p/9425613.html) 1.创 ...
随机推荐
- 2017qq红包雨最强攻略
这个只支持苹果手机,而且要有苹果电脑,只有苹果手机是不行的. QQ红包规则:只要你到达指定的位置,就可以领取附近的红包,一般也就几毛,还有几分的,当然也不排除有更高的,只不过我是没遇到... 那么既然 ...
- Asp.Net_Ajax调用WebService返回Json前台获取循环解析
利用JQuery的$.ajax()可以很方便的调用 asp.net的后台方法.但往往从后台返回的json字符串不能够正确解析,究其原因,是因为没有对返回的json数据做进一步的加工.其实,这里只需 要 ...
- Apache Ignite 学习笔记(四): Ignite缓存冗余备份策略
Ignite的数据网格是围绕着基于内存的分布式key/value存储能力打造的.当初技术选型的时候,决定用Ignite也是因为虽然同样是key/value存储,它有着和其他key/value存储系统不 ...
- Google C++ 编码规范
刚刚看到一位博主的文章分享Google C++ 编码规范 本人做一下记录,方便以后学习.. 中文在线版本地址: http://zh-google-styleguide.readthedocs.io/e ...
- [2017BUAA软工助教]个人得分总表(至alpha结束)
一.表 学号 第0次 week1 week2 week3 个人项目 附加1 结对项目 附加2 a团队 a团队得分 a贡献分 总分(不计) 总分(记) 15061119 7 9.5 12 9 45.75 ...
- Linux第五周学习总结——扒开系统调用的三层皮(下
Linux第五周学习总结--扒开系统调用的三层皮(下) 作者:刘浩晨 [原创作品转载请注明出处] <Linux内核分析>MOOC课程http://mooc.study.163.com/co ...
- 关于查询报表总是"超时已过期"的问题解决
"超时已过期" 的问题一直在烦扰着我, 在查一些数据量比较大的表或者运行一些复杂存储过程的时候就会出现这个提示, 一开始是按下面的来设,有一些报表是可以正常查出来 a.在企业管理器 ...
- 二分图最大权匹配模板(pascal)
用uoj80的题面了: 从前一个和谐的班级,有 nlnl 个是男生,有 nrnr 个是女生.编号分别为 1,…,nl1,…,nl 和 1,…,nr1,…,nr. 有若干个这样的条件:第 vv 个男生和 ...
- JVM学习笔记(四):类加载机制
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制. 一.类加载的时机1. 类从被加载到虚拟机内存 ...
- ubuntu下java JDK环境配置
ubuntu下配置JDK环境变量ubuntu下的JDK配置本质上和win一样的:1.去官网下载JDK,选择适合自己版本,我下载的版本是jdk-8u121-linunx-x64.tag.gz,官方网址h ...