Kafka 温故(二):Kafka的基本概念和结构
一.Kafka中的核心概念
Producer: 特指消息的生产者
Consumer :特指消息的消费者
Consumer Group :消费者组,可以并行消费Topic中partition的消息
Broker:缓存代理,Kafa 集群中的一台或多台服务器统称为 broker。
Topic:特指 Kafka 处理的消息源(feeds of messages)的不同分类。
Partition:Topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)
Message:消息,是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息
Producers(是个动词):消息和数据生产者,向 Kafka 的一个 topic 发布消息的过程叫做 producers
Consumers(是个动词):消息和数据消费者,订阅 topics 并处理其发布的消息的过程叫做 consumers
二.Kafka的逻辑架构
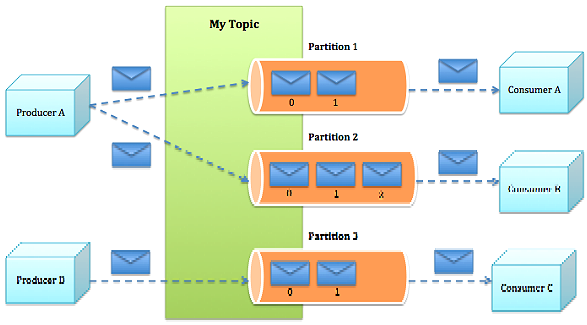
注:当一个Topic中消息过多时,会对Topic进行分区处理,把消息分到不同的Partition中。
为什么要分区:
是为了对大量的数据进行分而治之,把数据分区,不同的Consumer可以消费不同分区的数据,不同Consumer对数据的消费可以做成并行的,这样可以加快数据处理的速度。
消息发送的流程:
1.Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
2.kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
3.Consumer从kafka集群pull数据,并控制获取消息的offset
三.Kafka的Producers
1.producers定义:
消息和数据生产者,向 Kafka 的一个 topic 发布消息的过程叫做 produces
2.可指定消息的partition:
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition(即:生产者可以指定将发送的消息放在一个topic中的partition1,还是partition2中)(注:这种机制可以理解为一种变相的负载均衡,轮转);比如基于"round-robin"方式或者通过其他的一些算法等()
3.异步发送:
kafka支持异步批量发送消息。批量发送可以很有效的提高发送效率。Kafka producer的异步发送模式允许进行批量发送,先将消息缓存在内存中,然后一次请求批量发送出去。
四.Kafka的broker
1.Broker:(可以把Broker理解为Kafka的服务器)缓存代理,Kafka 集群中的一台或多台服务器统称为 broker。
注:
kafka中支持消息持久化的,生产者生产消息后,kafka不会直接把消息传递给消费者,而是先要在broker中进行存储,持久化是保存在kafka的日志文件中。
2.Message在Broker中通Log追加(即新的消息保存在文件的最后面,是有序的)的方式进行持久化存储。并进行分区(patitions)
3.为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
五.Kafka的broker无状态机制
1. Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。
注:Broker没有副本,那broker宕机了怎么解决?
虽然broker没有副本,但是消息本身是有副本的,不会丢失。Broker只要在宕机后再读取消息的日志就行了
2. Broker不保存订阅者的状态,由订阅者自己保存。
3. 无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
4. 消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id,即偏移量)进行重新读取消费消息。
注:1.消费者是如何确定,那条消息应该消费,那条消息已经消费了?
Zookeeper会帮助记录那条消息已经消费了,那条消息没有消费
2.消费者是如何快速的找到它没有消费的消息呢?
这个实现就要靠kafka中 “稀疏索引”
六.Kafka的Message的组成
1.Message消息:
是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息
2.Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
3.partition中的每条Message包含了以下三个属性:
offset(偏移量,即消息的唯一标示,通过它才能找到唯一的一条消息)
对应类型:long
MessageSize 对应类型:int32
data 是message的具体内容
注:1.消息是无状态的,消息的消费先后顺序是没有关系的
2.每一个partition只能由一个consumer来进行消费,但是一个consumer是可 以消费多个partition,是一对多的关系
七.Kafka的Partition的分区的目的
1.kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;
2.可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.
3.越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.
八.Kafka的Consumers

Kafka 温故(二):Kafka的基本概念和结构的更多相关文章
- Kafka学习之二 Kafka安装和使用
部署环境Linux(Centos 6.5),JDK 1.8.0,zookeeper-3.4.12,kafka_2.11-2.0.0. 1. 单机环境 官方建议使用JDK 1.8版本,因此本文使 ...
- kafka详解(二)--kafka为什么快
前言 Kafka 有多快呢?我们可以使用 OpenMessaging Benchmark Framework 测试框架方便地对 RocketMQ.Pulsar.Kafka.RabbitMQ 等消息系统 ...
- kafka学习(二)-------- 什么是Kafka
通过Kafka的快速入门 https://www.cnblogs.com/tree1123/p/11150927.html 能了解到Kafka的基本部署,使用,但他和其他的消息中间件有什么不同呢? K ...
- Kafka 温故(五):Kafka的消费编程模型
Kafka的消费模型分为两种: 1.分区消费模型 2.分组消费模型 一.分区消费模型 二.分组消费模型 Producer : package cn.outofmemory.kafka; import ...
- Kafka 温故(三):Kafka的内部机制深入(持久化,分布式,通讯协议)
一.Kafka的持久化 1.数据持久化: 发现线性的访问磁盘(即:按顺序的访问磁盘),很多时候比随机的内存访问快得多,而且有利于持久化: 传统的使用内存做为磁盘的缓存 Kafk ...
- Kafka 温故(一):Kafka背景及架构介绍
一.Kafka简介 Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,使用Scala语言编写,之后成为Apache项目的一部分.Kafka是一个分布式的,可划分的,多订阅者,冗余 ...
- Kafka安装之二 在CentOS 7上安装Kafka
一.简介 Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. 这 ...
- Kafka详解二:如何配置Kafka集群
问题导读1.Kafka有哪几种配制方法?2.如何启动一个Consumer实例来消费消息? Kafka集群配置比较简单,为了更好的让大家理解,在这里要分别介绍下面三种配置 单节点:一个broker的集群 ...
- Kafka具体解释二、怎样配置Kafka集群
Kafka集群配置比較简单,为了更好的让大家理解.在这里要分别介绍以下三种配置 单节点:一个broker的集群 单节点:多个broker的集群 多节点:多broker集群 一.单节点单broker实例 ...
随机推荐
- 「功能笔记」Spacemacs+Evil备忘录
设置代理 (setq url-gateway-method 'socks) (setq socks-server '("Default server" "127.0.0. ...
- Unity日记—对象缓存池
最近都在忙别的事了,今天忙里偷闲了解了一下对象池是啥玩意,简单记录一下. 还是个正在学习的萌新,如果写的不好请见谅. 1.对象池是啥 在了解对象池之后,我才意识到以前写的代码有多么蠢,当场景中有一些重 ...
- 通过Heketi管理GlusterFS为K8S集群提供持久化存储
参考文档: Github project:https://github.com/heketi/heketi MANAGING VOLUMES USING HEKETI:https://access.r ...
- 【Alpha阶段】M1事后报告
时间:2015-11-13 23:30 地点:七公寓一楼会议室 参与人员:窝窝头全体成员(王若愚因事请假) 设想和目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述 ...
- Linux内核实验作业六
实验作业:分析Linux内核创建一个新进程的过程 20135313吴子怡.北京电子科技学院 [第一部分]阅读理解task_struct数据结构 1.进程是计算机中已运行程序的实体.在面向线程设计的系统 ...
- 审评(HelloWorld团队)
炸弹人:我觉得炸弹人的构想很不错,很像以前玩的qq堂,不过上课时讲的不够深入,我没有找到项目的思路,项目的介绍也很粗糙,后面说的目标很大,希望你可以实现,我觉得越多的功能,就意味着越多的工作量,总的来 ...
- Spark 实践——用 Scala 和 Spark 进行数据分析
本文基于<Spark 高级数据分析>第2章 用Scala和Spark进行数据分析. 完整代码见 https://github.com/libaoquan95/aasPractice/tre ...
- ElasticSearch 2 (19) - 语言处理系列之故事开始
ElasticSearch 2 (19) - 语言处理系列之故事开始 摘要 全文搜索是精度(尽可能少的返回不相关文档)和召回(尽可能多的返回相关文档)的战场.尽管只精确匹配用户查询的词肯定会是精确的, ...
- PAT乙级(Basic Level)练习题-NowCoder数列总结
题目描述 NowCoder最近在研究一个数列: F(0) = 7 F(1) = 11 F(n) = F(n-1) + F(n-2) (n≥2) 他称之为NowCoder数列.请你帮忙确认一下数列中第n ...
- 查看django版本的方法
在cmd输入: python -m django --version django-admin --version