Kafka 温故(五):Kafka的消费编程模型
Kafka的消费模型分为两种:
1.分区消费模型
2.分组消费模型
一.分区消费模型
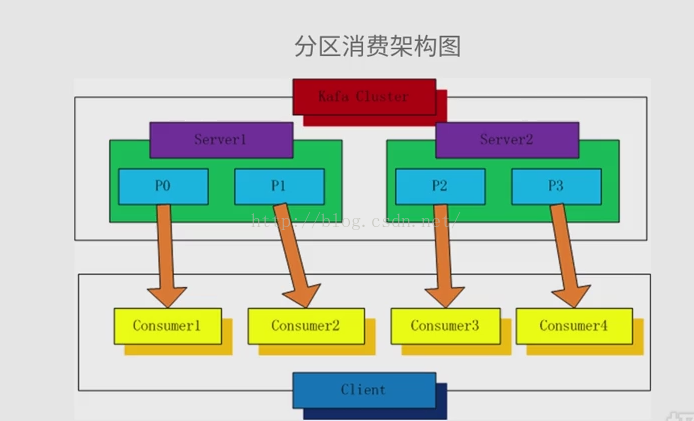
二、分组消费模型

Producer :
package cn.outofmemory.kafka; import java.util.Properties; import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig; /**
* Hello world!
*
*/
public class KafkaProducer
{
private final Producer<String, String> producer;
public final static String TOPIC = "TEST-TOPIC"; private KafkaProducer(){
Properties props = new Properties();
//此处配置的是kafka的端口
props.put("metadata.broker.list", "192.168.193.148:9092"); //配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
//配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder"); //request.required.acks
//0, which means that the producer never waits for an acknowledgement from the broker (the same behavior as 0.7). This option provides the lowest latency but the weakest durability guarantees (some data will be lost when a server fails).
//1, which means that the producer gets an acknowledgement after the leader replica has received the data. This option provides better durability as the client waits until the server acknowledges the request as successful (only messages that were written to the now-dead leader but not yet replicated will be lost).
//-1, which means that the producer gets an acknowledgement after all in-sync replicas have received the data. This option provides the best durability, we guarantee that no messages will be lost as long as at least one in sync replica remains.
props.put("request.required.acks","-1"); producer = new Producer<String, String>(new ProducerConfig(props));
} void produce() {
int messageNo = 1000;
final int COUNT = 10000; while (messageNo < COUNT) {
String key = String.valueOf(messageNo);
String data = "hello kafka message " + key;
producer.send(new KeyedMessage<String, String>(TOPIC, key ,data));
System.out.println(data);
messageNo ++;
}
} public static void main( String[] args )
{
new KafkaProducer().produce();
} }
Consumer
package cn.outofmemory.kafka; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties; import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties; public class KafkaConsumer { private final ConsumerConnector consumer; private KafkaConsumer() {
Properties props = new Properties();
//zookeeper 配置
props.put("zookeeper.connect", "192.168.193.148:2181"); //group 代表一个消费组
props.put("group.id", "jd-group"); //zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
//序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder"); ConsumerConfig config = new ConsumerConfig(props); consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
} void consume() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(KafkaProducer.TOPIC, new Integer(1)); StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties()); //获取到的输入流
Map<String, List<KafkaStream<String, String>>> consumerMap =
consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
KafkaStream<String, String> stream = consumerMap.get(KafkaProducer.TOPIC).get(0);
ConsumerIterator<String, String> it = stream.iterator();
//输出接受到的消息
while (it.hasNext())
System.out.println(it.next().message());
} public static void main(String[] args) {
new KafkaConsumer().consume();
}
}
kafka 学习告一段落,后面进入的为Spring 温习。
Kafka 温故(五):Kafka的消费编程模型的更多相关文章
- Kafka 温故(二):Kafka的基本概念和结构
一.Kafka中的核心概念 Producer: 特指消息的生产者Consumer :特指消息的消费者Consumer Group :消费者组,可以并行消费Topic中partition的消息Broke ...
- Storm集成Kafka编程模型
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3974417.html 本文主要介绍如何在Storm编程实现与Kafka的集成 一.实现模型 数据流程: ...
- Kafka 通过python简单的生产消费实现
使用CentOS6.5.python3.6.kafkaScala 2.10 - kafka_2.10-0.8.2.2.tgz (asc, md5) 一.下载kafka 下载地址 https://ka ...
- kafka的编程模型
1.kafka消费者编程模型 分区消费模型 组(group)消费模型 1.1.1.分区消费架构图,每个分区对应一个消费者. 1.1.2.分区消费模型伪代码描述 指定偏移量,用于从上次消费的地方开始消费 ...
- kafka架构,消息存储和生成消费模型,Kafka与其他队列对比,零拷贝,Kafka基本介绍
kafka架构,消息存储和生成消费模型,Kafka与其他队列对比,零拷贝,Kafka基本介绍 一.初识kafka 1.1SparkStreaming+Kafka好处: 1.2Kafka的架构: 二.k ...
- Kafka具体解释五、Kafka Consumer的底层API- SimpleConsumer
1.Kafka提供了两套API给Consumer The high-level Consumer API The SimpleConsumer API 第一种高度抽象的Consumer API,它使用 ...
- Kafka详解五:Kafka Consumer的底层API- SimpleConsumer
问题导读 1.Kafka如何实现和Consumer之间的交互?2.使用SimpleConsumer有哪些弊端呢? 1.Kafka提供了两套API给Consumer The high-level Con ...
- Kafka创建&查看topic,生产&消费指定topic消息
启动zookeeper和Kafka之后,进入kafka目录(安装/启动kafka参考前面一章:https://www.cnblogs.com/cici20166/p/9425613.html) 1.创 ...
- kafka创建topic,生产和消费指定topic消息
启动zookeeper和Kafka之后,进入kafka目录(安装/启动kafka参考前面一章:https://www.cnblogs.com/cici20166/p/9425613.html) 1.创 ...
随机推荐
- flask入门小方法
我是在pycharm中写的.那么需要在Termainal中cd 到当前文件所在的文件夹,在运行python py文件名 一开始想用面向对象的方法来封装这些小模块,但发现在面向对象中要用到类属性,以及类 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 假设检验,alpha,p值 通俗易懂的的理解。
假设检验: 一般原假设H0 :表是为 XXX和YYYY无显著差异,H1,是有显著差异. 如果我们定义alpha的值是0.05.意味着我们接受H0是真的但是我们却认为他是假的的概率. 这里你想想,这个值 ...
- 《口算大作战 2》DLC:算法真奇妙
211614331 王诚荣 211614354 陈斌 --第一次结对作业 DLC DLC:三年级混合运算模块现已更新!现在您可以愉快的使用三年级题库啦.同时您必须拥有本体才能使用此DLC 单击此处查看 ...
- 关于cocos2dx 关键字的问题
今天码代码,在创建新场景的时候,.h文件里 class Game : public cocos2d::Layer没有问题,在Game类里面,声明了它的成员之后,开始在.cpp文件里面实现这个类,到重 ...
- Daily Scrum - 11/25
今天是Sprint 2的最后一天,我们在下午的课上对之前两个Sprint作了比较详尽的Review,并在课后Daily Scrum上讨论制订了Sprint 3的任务安排.具体Task会在明天更新在TF ...
- RYU 灭龙战 fourth day (2)
RYU 灭龙战 fourth day (2) 前言 之前试过在ODL调用他们的rest api,一直想自己写一个基于ODL的rest api,结果还是无果而终.这个小目标却在RYU身上实现了.今日说法 ...
- C#简述(一)
详情请参考:http://www.runoob.com/csharp/csharp-tutorial.html 1.C# 是一个简单的.现代的.通用的.面向对象的编程语言,它是由微软(Microsof ...
- Linux dd命令制作U盘启动盘
linux下的dd命令来自于coreutils:http://www.gnu.org/software/coreutils/ https://jingyan.baidu.com/article/d45 ...
- Mysql 间隙锁原理,以及Repeatable Read隔离级别下可以防止幻读原理(百度)
Mysql知识实在太丰富了,前几天百度的面试官问我MySql在Repeatable Read下面是否会有幻读出现,我说按照事务的特性当然会有, 但是面试官却说 Mysql 在Repeatable Re ...