如何用卷积神经网络CNN识别手写数字集?
前几天用CNN识别手写数字集,后来看到kaggle上有一个比赛是识别手写数字集的,已经进行了一年多了,目前有1179个有效提交,最高的是100%,我做了一下,用keras做的,一开始用最简单的MLP,准确率只有98.19%,然后不断改进,现在是99.78%,然而我看到排名第一是100%,心碎 = =,于是又改进了一版,现在把最好的结果记录一下,如果提升了再来更新。
手写数字集相信大家应该很熟悉了,这个程序相当于学一门新语言的“Hello World”,或者mapreduce的“WordCount”:)这里就不多做介绍了,简单给大家看一下:
# Author:Charlotte
# Plot mnist dataset
from keras.datasets import mnist
import matplotlib.pyplot as plt
# load the MNIST dataset
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# plot 4 images as gray scale
plt.subplot(221)
plt.imshow(X_train[0], cmap=plt.get_cmap('PuBuGn_r'))
plt.subplot(222)
plt.imshow(X_train[1], cmap=plt.get_cmap('PuBuGn_r'))
plt.subplot(223)
plt.imshow(X_train[2], cmap=plt.get_cmap('PuBuGn_r'))
plt.subplot(224)
plt.imshow(X_train[3], cmap=plt.get_cmap('PuBuGn_r'))
# show the plot
plt.show()
图:

1.BaseLine版本
一开始我没有想过用CNN做,因为比较耗时,所以想看看直接用比较简单的算法看能不能得到很好的效果。之前用过机器学习算法跑过一遍,最好的效果是SVM,96.8%(默认参数,未调优),所以这次准备用神经网络做。BaseLine版本用的是MultiLayer Percepton(多层感知机)。这个网络结构比较简单,输入--->隐含--->输出。隐含层采用的rectifier linear unit,输出直接选取的softmax进行多分类。
网络结构:

代码:
# coding:utf-8
# Baseline MLP for MNIST dataset
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.utils import np_utils seed = 7
numpy.random.seed(seed)
#加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data() num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32')
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype('float32') X_train = X_train / 255
X_test = X_test / 255 # 对输出进行one hot编码
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1] # MLP模型
def baseline_model():
model = Sequential()
model.add(Dense(num_pixels, input_dim=num_pixels, init='normal', activation='relu'))
model.add(Dense(num_classes, init='normal', activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model # 建立模型
model = baseline_model() # Fit
model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=10, batch_size=200, verbose=2) #Evaluation
scores = model.evaluate(X_test, y_test, verbose=0)
print("Baseline Error: %.2f%%" % (100-scores[1]*100))#输出错误率
结果:
Layer (type) Output Shape Param # Connected to
====================================================================================================
dense_1 (Dense) (None, 784) 615440 dense_input_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 10) 7850 dense_1[0][0]
====================================================================================================
Total params: 623290
____________________________________________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
3s - loss: 0.2791 - acc: 0.9203 - val_loss: 0.1420 - val_acc: 0.9579
Epoch 2/10
3s - loss: 0.1122 - acc: 0.9679 - val_loss: 0.0992 - val_acc: 0.9699
Epoch 3/10
3s - loss: 0.0724 - acc: 0.9790 - val_loss: 0.0784 - val_acc: 0.9745
Epoch 4/10
3s - loss: 0.0509 - acc: 0.9853 - val_loss: 0.0774 - val_acc: 0.9773
Epoch 5/10
3s - loss: 0.0366 - acc: 0.9898 - val_loss: 0.0626 - val_acc: 0.9794
Epoch 6/10
3s - loss: 0.0265 - acc: 0.9930 - val_loss: 0.0639 - val_acc: 0.9797
Epoch 7/10
3s - loss: 0.0185 - acc: 0.9956 - val_loss: 0.0611 - val_acc: 0.9811
Epoch 8/10
3s - loss: 0.0150 - acc: 0.9967 - val_loss: 0.0616 - val_acc: 0.9816
Epoch 9/10
4s - loss: 0.0107 - acc: 0.9980 - val_loss: 0.0604 - val_acc: 0.9821
Epoch 10/10
4s - loss: 0.0073 - acc: 0.9988 - val_loss: 0.0611 - val_acc: 0.9819
Baseline Error: 1.81%
可以看到结果还是不错的,正确率98.19%,错误率只有1.81%,而且只迭代十次效果也不错。这个时候我还是没想到去用CNN,而是想如果迭代100次,会不会效果好一点?于是我迭代了100次,结果如下:
Epoch 100/100
8s - loss: 4.6181e-07 - acc: 1.0000 - val_loss: 0.0982 - val_acc: 0.9854
Baseline Error: 1.46%
从结果中可以看出,迭代100次也只提高了0.35%,没有突破99%,所以就考虑用CNN来做。
2.简单的CNN网络
keras的CNN模块还是很全的,由于这里着重讲CNN的结果,对于CNN的基本知识就不展开讲了。
网络结构:
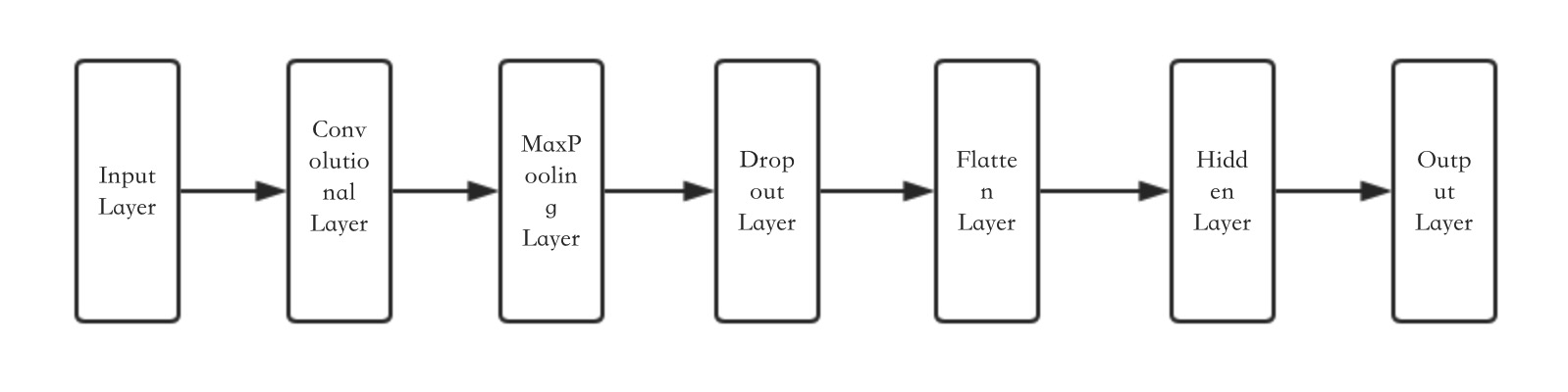
代码:
#coding: utf-8
#Simple CNN
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils seed = 7
numpy.random.seed(seed) #加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][channels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32') # normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255 # one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1] # define a simple CNN model
def baseline_model():
# create model
model = Sequential()
model.add(Convolution2D(32, 5, 5, border_mode='valid', input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model # build the model
model = baseline_model() # Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=10, batch_size=128, verbose=2) # Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("CNN Error: %.2f%%" % (100-scores[1]*100))
结果:
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 32, 24, 24) 832 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 32, 12, 12) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 32, 12, 12) 0 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0 dropout_1[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 128) 589952 flatten_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 10) 1290 dense_1[0][0]
====================================================================================================
Total params: 592074
____________________________________________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
32s - loss: 0.2412 - acc: 0.9318 - val_loss: 0.0754 - val_acc: 0.9766
Epoch 2/10
32s - loss: 0.0726 - acc: 0.9781 - val_loss: 0.0534 - val_acc: 0.9829
Epoch 3/10
32s - loss: 0.0497 - acc: 0.9852 - val_loss: 0.0391 - val_acc: 0.9858
Epoch 4/10
32s - loss: 0.0413 - acc: 0.9870 - val_loss: 0.0432 - val_acc: 0.9854
Epoch 5/10
34s - loss: 0.0323 - acc: 0.9897 - val_loss: 0.0375 - val_acc: 0.9869
Epoch 6/10
36s - loss: 0.0281 - acc: 0.9909 - val_loss: 0.0424 - val_acc: 0.9864
Epoch 7/10
36s - loss: 0.0223 - acc: 0.9930 - val_loss: 0.0328 - val_acc: 0.9893
Epoch 8/10
36s - loss: 0.0198 - acc: 0.9939 - val_loss: 0.0381 - val_acc: 0.9880
Epoch 9/10
36s - loss: 0.0156 - acc: 0.9954 - val_loss: 0.0347 - val_acc: 0.9884
Epoch 10/10
36s - loss: 0.0141 - acc: 0.9955 - val_loss: 0.0318 - val_acc: 0.9893
CNN Error: 1.07%
迭代的结果中,loss和acc为训练集的结果,val_loss和val_acc为验证机的结果。从结果上来看,效果不错,比100次迭代的MLP(1.46%)提升了0.39%,CNN的误差率为1.07%。这里的CNN的网络结构还是比较简单的,如果把CNN的结果再加几层,边复杂一代,结果是否还能提升?
3.Larger CNN
这一次我加了几层卷积层,代码:
# Larger CNN
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils seed = 7
numpy.random.seed(seed)
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][pixels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
# define the larger model
def larger_model():
# create model
model = Sequential()
model.add(Convolution2D(30, 5, 5, border_mode='valid', input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(15, 3, 3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# build the model
model = larger_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=69, batch_size=200, verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Large CNN Error: %.2f%%" % (100-scores[1]*100))
结果:
___________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 30, 24, 24) 780 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 30, 12, 12) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 15, 10, 10) 4065 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 15, 5, 5) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 15, 5, 5) 0 maxpooling2d_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 375) 0 dropout_1[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 128) 48128 flatten_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 50) 6450 dense_1[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 10) 510 dense_2[0][0]
====================================================================================================
Total params: 59933
____________________________________________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
34s - loss: 0.3789 - acc: 0.8796 - val_loss: 0.0811 - val_acc: 0.9742
Epoch 2/10
34s - loss: 0.0929 - acc: 0.9710 - val_loss: 0.0462 - val_acc: 0.9854
Epoch 3/10
35s - loss: 0.0684 - acc: 0.9786 - val_loss: 0.0376 - val_acc: 0.9869
Epoch 4/10
35s - loss: 0.0546 - acc: 0.9826 - val_loss: 0.0332 - val_acc: 0.9890
Epoch 5/10
35s - loss: 0.0467 - acc: 0.9856 - val_loss: 0.0289 - val_acc: 0.9897
Epoch 6/10
35s - loss: 0.0402 - acc: 0.9873 - val_loss: 0.0291 - val_acc: 0.9902
Epoch 7/10
34s - loss: 0.0369 - acc: 0.9880 - val_loss: 0.0233 - val_acc: 0.9924
Epoch 8/10
36s - loss: 0.0336 - acc: 0.9894 - val_loss: 0.0258 - val_acc: 0.9913
Epoch 9/10
39s - loss: 0.0317 - acc: 0.9899 - val_loss: 0.0219 - val_acc: 0.9926
Epoch 10/10
40s - loss: 0.0268 - acc: 0.9916 - val_loss: 0.0220 - val_acc: 0.9919
Large CNN Error: 0.81%
效果不错,现在的准确率是99.19%
4.最终版本
网络结构没变,只是在每一层后面加了dropout,结果居然有显著提升。一开始迭代500次,跑死我了,结果过拟合了,然后观察到69次的时候结果就已经很好了,就选择了迭代69次。
# Larger CNN for the MNIST Dataset
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
import matplotlib.pyplot as plt
from keras.constraints import maxnorm
from keras.optimizers import SGD
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][pixels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
###raw
# define the larger model
def larger_model():
# create model
model = Sequential()
model.add(Convolution2D(30, 5, 5, border_mode='valid', input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.4))
model.add(Convolution2D(15, 3, 3, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(50, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model # build the model
model = larger_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=200, batch_size=200, verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Large CNN Error: %.2f%%" % (100-scores[1]*100))
结果:
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 30, 24, 24) 780 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 30, 12, 12) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 15, 10, 10) 4065 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 15, 5, 5) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 15, 5, 5) 0 maxpooling2d_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 375) 0 dropout_1[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 128) 48128 flatten_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 50) 6450 dense_1[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 10) 510 dense_2[0][0]
====================================================================================================
Total params: 59933
____________________________________________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/69
34s - loss: 0.4248 - acc: 0.8619 - val_loss: 0.0832 - val_acc: 0.9746
Epoch 2/69
35s - loss: 0.1147 - acc: 0.9638 - val_loss: 0.0518 - val_acc: 0.9831
Epoch 3/69
35s - loss: 0.0887 - acc: 0.9719 - val_loss: 0.0452 - val_acc: 0.9855
、、、
Epoch 66/69
38s - loss: 0.0134 - acc: 0.9955 - val_loss: 0.0211 - val_acc: 0.9943
Epoch 67/69
38s - loss: 0.0114 - acc: 0.9960 - val_loss: 0.0171 - val_acc: 0.9950
Epoch 68/69
38s - loss: 0.0116 - acc: 0.9959 - val_loss: 0.0192 - val_acc: 0.9956
Epoch 69/69
38s - loss: 0.0132 - acc: 0.9969 - val_loss: 0.0188 - val_acc: 0.9978
Large CNN Error: 0.22% real 41m47.350s
user 157m51.145s
sys 6m5.829s
这是目前的最好结果,99.78%,然而还有很多地方可以提升,下次准确率提高了再来更 。
总结:
1.CNN在图像识别上确实比传统的MLP有优势,比传统的机器学习算法也有优势(不过也有通过随机森林取的很好效果的)
2.加深网络结构,即多加几层卷积层有助于提升准确率,但是也能大大降低运行速度
3.适当加Dropout可以提高准确率
4.激活函数最好,算了,直接说就选relu吧,没有为啥,就因为relu能避免梯度消散这一点应该选它,训练速度快等其他优点下次专门总结一篇文章再说吧。
5.迭代次数不是越多越好,很可能会过拟合,自己可以做一个收敛曲线,keras里可以用history函数plot一下,看算法是否收敛,还是发散。
如何用卷积神经网络CNN识别手写数字集?的更多相关文章
- Python实现神经网络算法识别手写数字集
最近忙里偷闲学习了一点机器学习的知识,看到神经网络算法时我和阿Kun便想到要将它用Python代码实现.我们用了两种不同的方法来编写它.这里只放出我的代码. MNIST数据集基于美国国家标准与技术研究 ...
- Pytorch卷积神经网络识别手写数字集
卷积神经网络目前被广泛地用在图片识别上, 已经有层出不穷的应用, 如果你对卷积神经网络充满好奇心,这里为你带来pytorch实现cnn一些入门的教程代码 #首先导入包 import torchfrom ...
- python手写神经网络实现识别手写数字
写在开头:这个实验和matlab手写神经网络实现识别手写数字一样. 实验说明 一直想自己写一个神经网络来实现手写数字的识别,而不是套用别人的框架.恰巧前几天,有幸从同学那拿到5000张已经贴好标签的手 ...
- 李宏毅 Keras手写数字集识别(优化篇)
在之前的一章中我们讲到的keras手写数字集的识别中,所使用的loss function为‘mse’,即均方差.那我们如何才能知道所得出的结果是不是overfitting?我们通过运行结果中的trai ...
- 【TensorFlow篇】--Tensorflow框架实现SoftMax模型识别手写数字集
一.前述 本文讲述用Tensorflow框架实现SoftMax模型识别手写数字集,来实现多分类. 同时对模型的保存和恢复做下示例. 二.具体原理 代码一:实现代码 #!/usr/bin/python ...
- 使用神经网络来识别手写数字【译】(三)- 用Python代码实现
实现我们分类数字的网络 好,让我们使用随机梯度下降和 MNIST训练数据来写一个程序来学习怎样识别手写数字. 我们用Python (2.7) 来实现.只有 74 行代码!我们需要的第一个东西是 MNI ...
- matlab手写神经网络实现识别手写数字
实验说明 一直想自己写一个神经网络来实现手写数字的识别,而不是套用别人的框架.恰巧前几天,有幸从同学那拿到5000张已经贴好标签的手写数字图片,于是我就尝试用matlab写一个网络. 实验数据:500 ...
- 【TensorFlow-windows】(四) CNN(卷积神经网络)进行手写数字识别(mnist)
主要内容: 1.基于CNN的mnist手写数字识别(详细代码注释) 2.该实现中的函数总结 平台: 1.windows 10 64位 2.Anaconda3-4.2.0-Windows-x86_64. ...
- 利用卷积神经网络实现MNIST手写数据识别
代码: import torch import torch.nn as nn import torch.utils.data as Data import torchvision # 数据库模块 im ...
随机推荐
- visual studio code更新
早上起来正在看go语言,vsc提示有更新,之后安装,重启之后显示中文菜单,显然vsc支持本地化了. 查看发行说明:https://code.visualstudio.com/updates#vscod ...
- java设计模式之简单工厂模式
简单工厂: 简单工厂的优点: 1.去除客户端与具体产品的耦合,在客户端与具体的产品中增加一个工厂类,增加客户端与工厂类的耦合 2.封装工厂类,实现代码平台的复用性,创建对象的过程被封装成工厂类,可以多 ...
- [Asp.net 5] Options-配置文件(2)
很久之前写过一篇介绍Options的文章,2016年再打开发现很多变化.增加了新类,增加OptionMonitor相关的类.今天就对于这个现在所谓的新版本进行介绍. 老版本的传送门([Asp.net ...
- PDO运用
- LogBack简易教程
1.简介 LogBack是一个日志框架,它与Log4j可以说是同出一源,都出自Ceki Gülcü之手.(log4j的原型是早前由Ceki Gülcü贡献给Apache基金会的) 1.1 LogBac ...
- IoC组件~Autofac将多实现一次注入,根据别名Resove实例
回到目录 对于IoC容器来说,性能最好的莫过于Autofac了,而对于灵活度来说,它也是值得称赞的,为了考虑系统的性能,我们经常是在系统初始化于将所有依赖注册到容器里,当需要于根据别名把实现拿出来,然 ...
- datatables中的Options总结(2)
datatables中的Options总结(2) 五.datatable,列 columnDefs.targets 分配一个或多个列的列定义. columnDefs 设置列定义初始化属性. colum ...
- CSS3学习总结——实现瀑布流布局与无限加载图片相册
首先给大家看一下瀑布流布局与无限加载图片相册效果图: 一.pic1.html页面代码如下: <!DOCTYPE html> <html> <head> <me ...
- CSS3之新UI方案
border-radius 圆角 参数可为像素 也可为百分比 当一个参数时 作用范围为四个角 当两个参数时 作用范围为 左上右下 右上左下 当三个参数时 作用范围为 左上 右上左下 右下 当四个参数时 ...
- 随笔分类 - [C#6] 新增特性
C#6.0中引入的基本特性总结 [C#6] 7-索引初始化器 摘要: 0. 目录 C#6 新增特性目录 1. 老版本的代码 早C#3中引入的集合初始化器,可是让我们用上面的语法来在声明一个字典或者集合 ...