每天几分钟跟小猫学前端之node系列:用node实现最简单的爬虫
先来段求分小视频:
https://www.iesdouyin.com/share/video/6550631947750608142/?region=CN&mid=6550632036246555405&titleType=title×tamp=1525407578&utm_campaign=client_share&app=aweme&utm_medium=ios&iid=30176260384&utm_source=qq&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=aweme_ios&utm_campaign=client_share&uid=92735989673&did=30176260384
本文的教学视频地址:
https://v.qq.com/x/page/b0643tut4ze.html


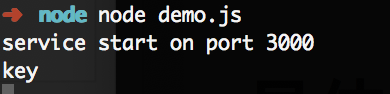
const request = require('request');
const app = express();
app.get('/:key',function(req,res){
console.log(req.params.key)
})
app.listen(3000,()=>{
console.log("service start on port 3000");
})
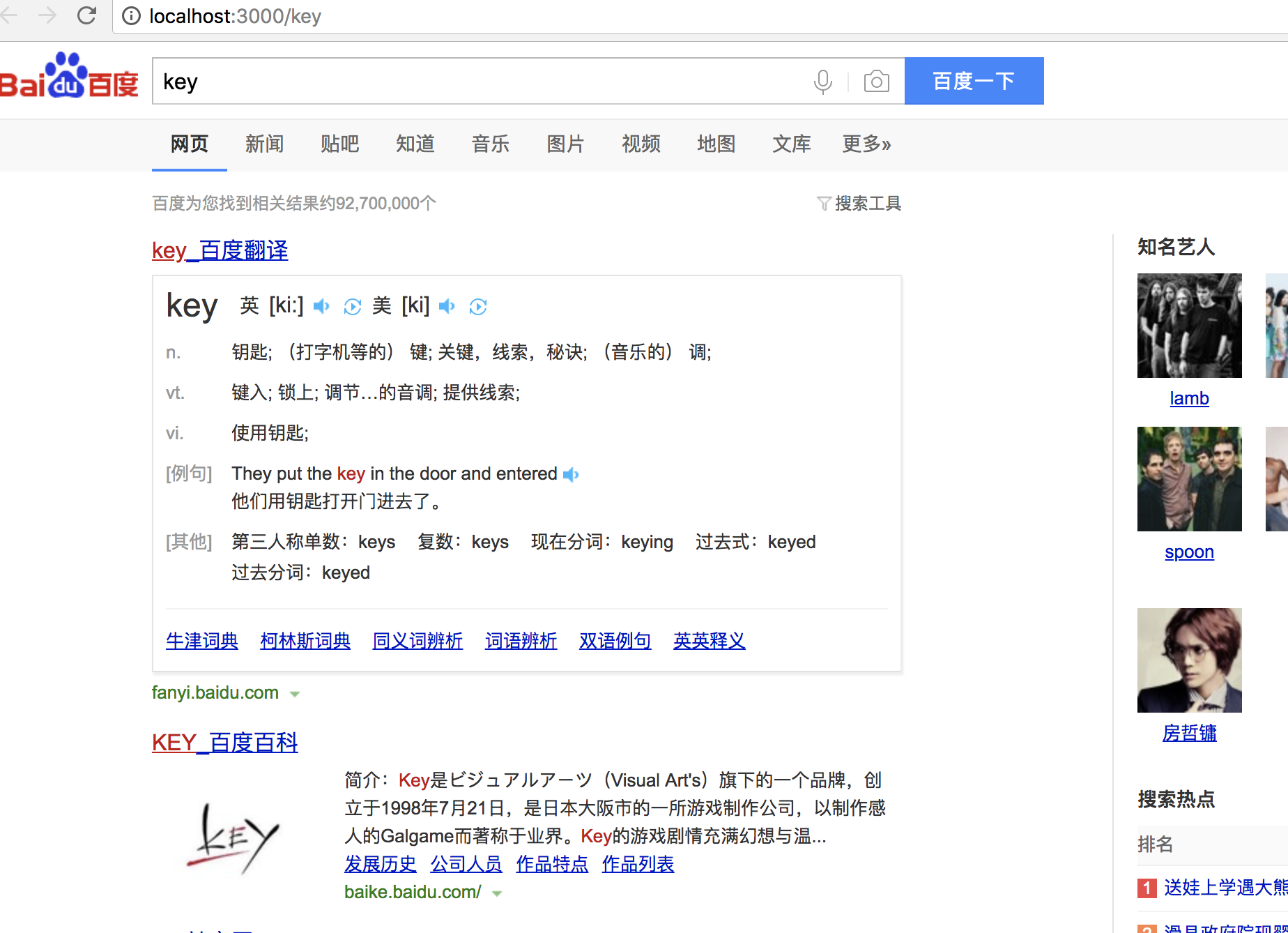
const express = require('express');
const request = require('request');
const app = express();
app.get('/:key',function(req,res){
console.log(req.params.key)
let spider = new Spider();
spider.fetch("http://www.baidu.com/s?wd="+req.params.key,(err,body)=>{
if(!err){
res.send(body.toString());
}
})
})
app.listen(3000,()=>{
console.log("service start on port 3000");
})
class Spider{
fetch(url,callback){
request({url: url, encoding : null}, (error, response, body)=>{
if (!error && response.statusCode === 200){
callback(null ,body);
}else{
callback(error ,'<body></body>');
}
});
}
}
const express = require('express');
const request = require('request');
const app = express();
const cheerio = require('cheerio');
app.get('/:key',function(req,res){
let spider = new Spider();
spider.fetch("http://www.baidu.com/s?wd="+req.params.key,(err,$)=>{
spider.fetchCallback(err,$,res)
})
console.log("http://www.baidu.com/s?wd="+req.params.key)
})
app.listen(3000,()=>{
console.log("service start on port 3000");
})
class Spider{
fetch(url,callback){
request({url: url, encoding : null}, (error, response, body)=>{
if (!error && response.statusCode === 200){
callback(null ,cheerio.load('<body>'+body+'</body>'));
}else{
callback(error ,cheerio.load('<body></body>'));
}
});
}
fetchCallback(err,$,res){
if(!err){
let keyList = [];
let table = $('body').find("#rs table").html();
res.send(table);
}
}
}
每天几分钟跟小猫学前端之node系列:用node实现最简单的爬虫的更多相关文章
- 只需几分钟跟小猫学前端(内含视频教程):nodejs基础之用express、ejs、mongdb建设简单的网站
开门见山视频教程 https://v.qq.com/x/page/d0645s79xrq.html 前 言: 这是小猫的第二篇node教程,第一篇教程是一个简单的试水,小猫的node教程面向对象为没有 ...
- 原生JS实现轮播+学前端的感受(防止走火入魔)
插件!插件!天天听到有人求这个插件,那个插件的,当然,用第三方插件可以大幅提高开发效率,但作为新手,我还是喜欢自己来实现,主要是我有时间! 今天我来给大家分享下用原生JS实现图片轮播的写法 前辈们可以 ...
- 重学前端 --- Promise里的代码为什么比setTimeout先执行?
首先通过一段代码进入讨论的主题 var r = new Promise(function(resolve, reject){ console.log("a"); resolve() ...
- ife 零基础学院 day 1 - 我为什么想学前端
与前端结缘 我是后端研发,毕业四年,用了四年C#,一开始写ASP.NET,有时会在asp页面写简单的js和html,做点css样式调整.当时的感触是前端调试太费劲了,因为没有js.html.css ...
- 结合jquery的前后端加密解密 适用于WebApi的SQL注入过滤器 Web.config中customErrors异常信息配置 ife2018 零基础学院 day 4 ife2018 零基础学院 day 3 ife 零基础学院 day 2 ife 零基础学院 day 1 - 我为什么想学前端
在一个正常的项目中,登录注册的密码是密文传输到后台服务端的,也就是说,首先前端js对密码做处理,随后再传递到服务端,服务端解密再加密传出到数据库里面.Dotnet已经提供了RSA算法的加解密类库,我们 ...
- 重学前端--js是面向对象还是基于对象?
重学前端-面向对象 跟着winter老师一起,重新认识前端的知识框架 js面向对象或基于对象编程 以前感觉这两个在本质上没有什么区别,面向对象和基于对象都是对一个抽象的对象拥有一系列的行为和状态,本质 ...
- 15分钟带你了解前端工程师必知的javascript设计模式(附详细思维导图和源码)
15分钟带你了解前端工程师必知的javascript设计模式(附详细思维导图和源码) 前言 设计模式是一个程序员进阶高级的必备技巧,也是评判一个工程师工作经验和能力的试金石.设计模式是程序员多年工作经 ...
- css与javascript重难点,学前端,基础不好一切白费!
JavaScript是一种属于网络的脚本语言,已经被广泛用于Web应用开发,常用来为网页添加各式各样的动态功能,为用户提供更流畅美观的浏览效果.通常JavaScript脚本是通过嵌入在HTML中来实现 ...
- 学前端的第一门语言HTML
学前端最终要做的就是制作各种各样的网页,html就相当于网页的骨架,所以我们学习前端的第一步就是先学html,接下来学习什么是html. 什么是HTML? HTML指的是超文本标记语言(Hyper T ...
随机推荐
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- UNIX网络编程——非阻塞accept
当有一个已完成的连接准备好被accept时,select将作为可读描述符返回该连接的监听套接字.因此,如果我们使用select在某个监听套接字上等待一个外来连接,那就没有必要把监听套接字设置为非阻塞, ...
- java根据概率生成数字
/** * JAVA 返回随机数,并根据概率.比率 * @author zhanglei * */ public class MathRandom { /** * 0出现的概率为%50 */ publ ...
- 版本控制—使用Gradle自动管理应用程序版本
我们在开发App时,通常在项目的Release阶段我们需要设置应用的版本号和版本名称,也就是设置下面两个属性 versionCode versionName 版本号 其中versionCode的值是i ...
- 11.1、Libgdx的音频之音效
(官网:www.libgdx.cn) 音效通常是比较小的音频文件,通常是几秒钟的长度.通常用在特定的游戏事件中,比如跳跃或者射击. 音效可以保存为多种格式.Libgdx支持MP3.OGG和WAV文件. ...
- 海量数据挖掘MMDS week3:流算法Stream Algorithms
http://blog.csdn.net/pipisorry/article/details/49183379 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- OJ题:字符串分隔
题目描述 •连续输入字符串,请按长度为8拆分每个字符串后输出到新的字符串数组:•长度不是8整数倍的字符串请在后面补数字0,空字符串不处理. 输入描述: 连续输入字符串(输入2次,每个字符串长度小于10 ...
- Leetcode_66_Plus One
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/41652987 Plus One Given a non-n ...
- Zookeeper实现master选举
使用场景 有一个向外提供的服务,服务必须7*24小时提供服务,不能有单点故障.所以采用集群的方式,采用master.slave的结构.一台主机多台备机.主机向外提供服务,备机负责监听主 ...
- 【一天一道LeetCode】#51. N-Queens
一天一道LeetCode系列 (一)题目 The n-queens puzzle is the problem of placing n queens on an n×n chessboard suc ...