Zookeeper原理架构与搭建
一、Zookeeper到底是什么!?
学一个东西,不搞明白他是什么东西,哪还有心情学啊!!
首先,Zookeeper是Apache的一个java项目,属于Hadoop系统,扮演管理员的角色。
然后看到官网那些专有名词,实在理解不了。
在Zookeeper的官网上有这么一句话:ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
那么我们来仔细研究一下这个东西吧!

二、Zookeeper能干嘛?!
2.1 配置管理
这个好理解。分布式系统都有好多机器,比如我在搭建hadoop的HDFS的时候,需要在一个主机器上(Master节点)配置好HDFS需要的各种配置文件,然后通过scp命令把这些配置文件拷贝到其他节点上,这样各个机器拿到的配置信息是一致的,才能成功运行起来HDFS服务。Zookeeper提供了这样的一种服务:一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的都可以获得变更。这样就省去手动拷贝配置了,还保证了可靠和一致性。
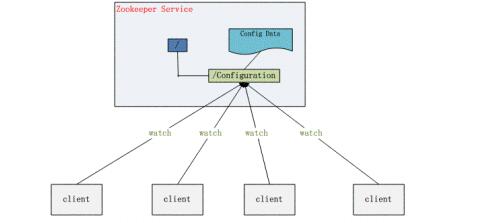
2.2 名字服务
这个可以简单理解为一个电话薄,电话号码不好记,但是人名好记,要打谁的电话,直接查人名就好了。
分布式环境下,经常需要对应用/服务进行统一命名,便于识别不同服务;
- 类似于域名与ip之间对应关系,域名容易记住;
- 通过名称来获取资源或服务的地址,提供者等信息
2.3 分布式锁
碰到分布二字貌似就难理解了,其实很简单。单机程序的各个进程需要对互斥资源进行访问时需要加锁,那分布式程序分布在各个主机上的进程对互斥资源进行访问时也需要加锁。很多分布式系统有多个可服务的窗口,但是在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即fail over到另外的服务。这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫Leader Election(leader选举)。举个通俗点的例子,比如银行取钱,有多个窗口,但是呢对你来说,只能有一个窗口对你服务,如果正在对你服务的窗口的柜员突然有急事走了,那咋办?找大堂经理(zookeeper)!大堂经理指定另外的一个窗口继续为你服务!
2.4 集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中有些机器(比如Master节点)需要感知到这种变化,然后根据这种变化做出对应的决策。我已经知道HDFS中namenode是通过datanode的心跳机制来实现上述感知的,那么我们可以先假设Zookeeper其实也是实现了类似心跳机制的功能吧!
三、Zookeeper的特点
1 最终一致性:为客户端展示同一视图,这是zookeeper最重要的功能。
2 可靠性:如果消息被到一台服务器接受,那么它将被所有的服务器接受。
3 实时性:Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4 等待无关(wait-free):慢的或者失效的client不干预快速的client的请求。
5 原子性:更新只能成功或者失败,没有中间状态。
6 顺序性:所有Server,同一消息发布顺序一致。
用到Zookeeper的系统
HDFS中的HA方案
YARN的HA方案
HBase:必须依赖Zookeeper,保存了Regionserver的心跳信息,和其他的一些关键信息。
Flume:负载均衡,单点故障
四、Zookpeeper的基本架构
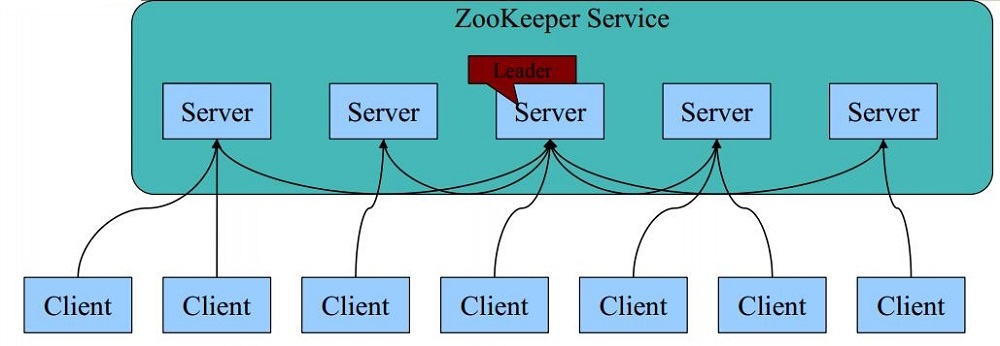
1 每个Server在内存中存储了一份数据;
2 Zookeeper启动时,将从实例中选举一个leader(Paxos协议);
3 Leader负责处理数据更新等操作(Zab协议);
4 一个更新操作成功,当且仅当大多数Server在内存中成功修改
数据。
4.1 Zookpeeper Server 节点的数目
Zookeeper Server数目一般为奇数
Leader选举算法采用了Paxos协议;Paxos核心思想:当多数Server写成功,则任务数据写
成功。也就是说:
如果有3个Server,则两个写成功即可;
如果有4或5个Server,则三个写成功即可。
Server数目一般为奇数(3、5、7)
如果有3个Server,则最多允许1个Server挂掉;
如果有4个Server,则同样最多允许1个Server挂掉
既然如此,为啥要用4个Server?
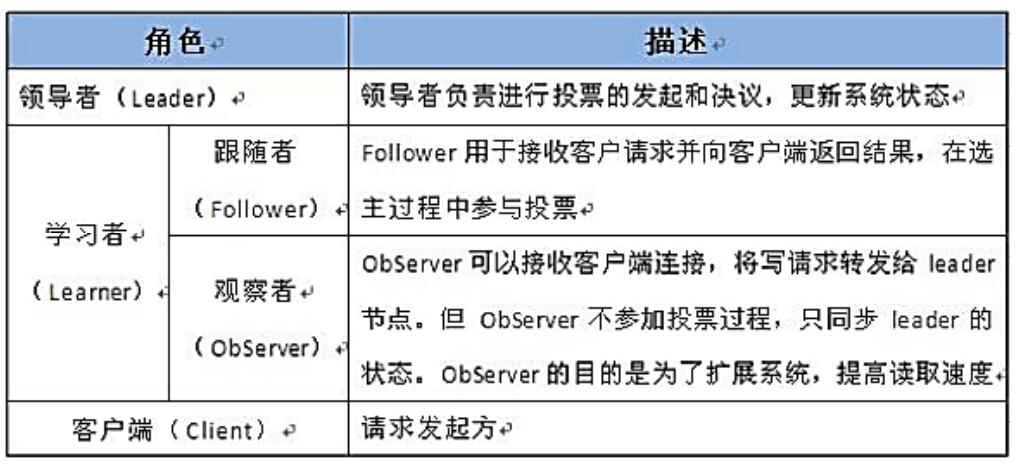
4.2 Observer节点
3.3.0 以后 版本新增角色Observer
增加原因:
Zookeeper需保证高可用和强一致性;
当集群节点数目逐渐增大为了支持更多的客户端,需要增加更多Server,然而Server增多,投票阶段延迟增大,影响性能。为了权衡伸缩性和高吞吐率,引入Observer:
Observer不参与投票;
Observers接受客户端的连接,并将写请求转发给leader节点;
加入更多Observer节点,提高伸缩性,同时不影响吞吐率。
五、Zookeeper写流程:
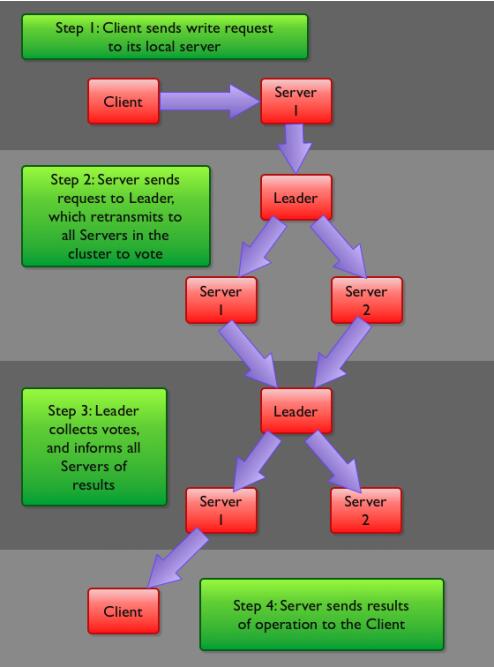
客户端首先和一个Server或者Observe(可以认为是一个Server的代理)通信,发起写请求,然后Server将写请求转发给Leader,Leader再将写请求转发给其他Server,Server在接收到写请求后写入数据并相应Leader,Leader在接收到大多数写成功回应后,认为数据写成功,相应Client。
六、Zookeeper数据模型

组织结构
zookeeper采用层次化的目录结构,命名符合常规文件系统规范;
每个目录在zookeeper中叫做znode,并且其有一个唯一的路径标识;
Znode
Znode可以包含数据和子znode(ephemeral类型的节点不能有子znode);
Znode中的数据可以有多个版本,比如某一个znode下存有多个数据版本,那么查询这个路径下的数据需带上版本;
客户端应用可以在znode上设置监视器(Watcher)
znode不支持部分读写,而是一次性完整读写
Znode类型
Znode有两种类型,短暂的(ephemeral)和持久的(persistent);
Znode的类型在创建时确定并且之后不能再修改;
ephemeral znode的客户端会话结束时,zookeeper会将该ephemeral znode删除,ephemeralzn ode不可以有子节点;
persistent znode不依赖于客户端会话,只有当客户端明确要删除该persistent znode时才会被删除;
Znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、PHEMERAL_SEQUENTIAL。
七、zookeeper搭建
Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式。
- 单机模式:Zookeeper只运行在一台服务器上,适合测试环境;
- 伪集群模式:就是在一台物理机上运行多个Zookeeper 实例;
- 集群模式:Zookeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”(ensemble)
Zookeeper通过复制来实现高可用性,只要集合体中半数以上的机器处于可用状态,它就能够保证服务继续。为什么一定要超过半数呢?这跟Zookeeper的复制策略有关:zookeeper确保对znode 树的每一个修改都会被复制到集合体中超过半数的机器上。
单机模式
打开zookeeper的官方下载地址:
https://archive.apache.org/dist/zookeeper/
目前最新版本为3.4.13,下载对应的包即可!
基于docker方式安装
本文所使用的操作系统是 ubuntu-16.04.5-server-amd64,docker镜像采用的是ubuntu:16.04
创建一个空目录
mkdir /opt/zookeeper
dockerfile
内容如下:
FROM ubuntu:16.04
# 修改更新源为阿里云
ADD sources.list /etc/apt/sources.list
ADD zookeeper-3.4..tar.gz /
ADD zoo.cfg /
# 安装jdk
RUN apt-get update && apt-get install -y openjdk--jdk --allow-unauthenticated && apt-get clean all && \
cd /zookeeper-3.4. && \
mkdir data log && \
mv /zoo.cfg conf EXPOSE
# 添加启动脚本
ADD run.sh .
RUN chmod run.sh
ENTRYPOINT [ "/run.sh"]
注意:zookeeper依赖java环境。如果不安装,会导致2181端口无法开启!
ADD 文件名,如果这个是文件是tgz或者tar.gz,docker会自动解压,并自动删除压缩包。
所以在dockerfile中,需要写解压命令以及删除压缩文件
run.sh
内容如下:
#!/bin/bash cd /zookeeper-3.4./
bin/zkServer.sh start tail -f NOTICE.txt
注意:由于docker启动时,要保证run.sh执行之后,要能够hold住,所以最后使用tail -f NOTICE.txt。
这样docker后台执行时,才不会终止掉!
sources.list
内容如下:
deb http://mirrors.aliyun.com/ubuntu/ xenial main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
zoo.cfg
内容如下:
tickTime=
dataDir=/zookeeper-3.4./data
dataLogDir=/zookeeper-3.4./log
clientPort=
这个是zookeeper的配置文件,主要配置这几项就可了!
参数解释:
tickTime:Client-Server通信心跳时间
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
dataDir:数据文件目录
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
clientPort:客户端连接端口
客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
dataLogDir:存放顺序日志(WAL)
dataLogDir如果没提供的话使用的则是dataDir。zookeeper的持久化都存储在这两个目录里。
为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。
此时 /opt/zookeeper 目录结构如下:
./
├── dockerfile
├── run.sh
├── sources.list
├── zoo.cfg
└── zookeeper-3.4..tar.gz
创建镜像
docker build -t zookeeper /opt/zookeeper
运行zookeeper
docker run -d -it -p : zookeeper
查看端口是否启动
root@jqb-node128:/opt/zookeeper# netstat -anpt
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0.0.0.0: 0.0.0.0:* LISTEN /sshd
tcp 192.168.91.128: 192.168.91.1: ESTABLISHED /
tcp6 ::: :::* LISTEN /sshd
tcp6 0 0 :::2181 :::* LISTEN 37198/docker-proxy
查看docker 进程
root@jqb-node128:/opt/zookeeper# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6ab3e463aebb zookeeper "/run.sh" minutes ago Up minutes 0.0.0.0:->/tcp hardcore_booth
进入 docker 容器
root@jqb-node128:/opt/zookeeper# docker exec -it 6ab3e463aebb /bin/bash
执行 zookeeper的cli脚本,使用ls / 查看所有节点
root@6ab3e463aebb:/# cd /zookeeper-3.4.13/bin/
root@6ab3e463aebb:/zookeeper-3.4./bin# ./zkCli.sh
[zk: localhost:(CONNECTED) ] ls /
[zookeeper]
默认只有一个zookeeper 节点
查看节点
[zk: localhost:(CONNECTED) ] ls /zookeeper
[quota]
获取节点数据
[zk: localhost:(CONNECTED) ] get /zookeeper cZxid = 0x0
ctime = Thu Jan :: UTC
mZxid = 0x0
mtime = Thu Jan :: UTC
pZxid = 0x0
cversion = -
dataVersion =
aclVersion =
ephemeralOwner = 0x0
dataLength =
numChildren =
关于 Zookeeper 的基础命令操作,请参考链接:
https://blog.csdn.net/dandandeshangni/article/details/80558383
关于 Zookeeper 另外2中默认搭建,请参考链接:
http://www.cnblogs.com/wuxl360/p/5817489.html
本文参考链接:
http://www.cnblogs.com/arjenlee/articles/9224366.html
Zookeeper原理架构与搭建的更多相关文章
- Zookeeper原理架构
Zookeeper到底是什么!? 学一个东西,不搞明白他是什么东西,哪还有心情学啊!! 首先,Zookeeper是Apache的一个java项目,属于Hadoop系统,扮演管理员的角色. 然后看到官网 ...
- 初始zookeeper与集群搭建实例
zookeeper是什么 Zookeeper,一种分布式应用的协作服务,是Google的Chubby一个开源的实现,是Hadoop的分布式协调服务,它包含一个简单的原语集,应用于分布式应用的协作服务, ...
- Solr集群的搭建以及使用(内涵zookeeper集群的搭建指南)
1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...
- SpringMVC,Spring,Hibernate,Mybatis架构开发搭建之SpringMVC部分
SpringMVC,Spring,Hibernate,Mybatis架构开发搭建之SpringMVC部分 辞职待业青年就是有很多时间来写博客,以前在传统行业技术强度相对不大,不处理大数据,也不弄高并发 ...
- 初识ZooKeeper与集群搭建实例
原文链接:http://www.linuxidc.com/Linux/2015-02/114230.htm zookeeper是什么 Zookeeper,一种分布式应用的协作服务,是Google的Ch ...
- (转)OpenStack —— 原理架构介绍(一、二)
原文:http://blog.51cto.com/wzlinux/1961337 http://blog.51cto.com/wzlinux/category18.html-------------O ...
- ZooKeeper原理 --------这可能是把ZooKeeper概念讲的最清楚的一篇文章
相信大家对 ZooKeeper 应该不算陌生,但是你真的了解 ZooKeeper 是什么吗?如果别人/面试官让你讲讲 ZooKeeper 是什么,你能回答到哪个地步呢? 我本人曾经使用过 ZooKee ...
- LNMP架构的搭建
第9章 LNMP架构的搭建 9.1 什么是LNMP 9.1.1 LNMP的组成 L linux N nginx:实现静态的服务处理 M ...
- 8.8.ZooKeeper 原理和选举机制
1.ZooKeeper原理 Zookeeper虽然在配置文件中并没有指定master和slave但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通 ...
随机推荐
- js字符串替换(时间转换)
转: js中字符串全部替换 废话不多说,直接发结果 在js中字符串全部替换可以用以下方法: str.replace(/需要替换的字符串/g,"新字符串") 比如: "yy ...
- imuxsock lost 353 messages from pid 20261 due to rate-limiting 解决办法
日志中出现大量一下日志时 May 24 18:42:08 yw_lvs2_backup rsyslogd-2177: imuxsock lost 353 messages from pid 20261 ...
- centos systemctl daemon-reload 提示 no such file or directory 的一个原因
service 的文件名写错了 比如 mongodb.service 写成了 mongodb.srvice 真的是坑,居然没有提示具体的路径,只是提示一个 no such file or direct ...
- 用递归的方法求一个数组的前n项和
用递归的方法求一个数组的前n项和 public class Demo1 { /* * 用递归的方法求一个数组的前n项和 */ public static void main(String[] args ...
- nltk30_Investigating bias with NLTK
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- Java基础-面向接口编程-JDBC详解
Java基础-面向接口编程-JDBC详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.JDBC概念和数据库驱动程序 JDBC(Java Data Base Connectiv ...
- Java基础-数组常见排序方式
Java基础-数组常见排序方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 数据的排序一般都是生序排序,即元素从小到大排列.常见的有两种排序方式:选择排序和冒泡排序.选择排序的特 ...
- 遗传算法入门C1
遗传算法入门C1 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 遗传算法历史 遗传算法(GA)是从生物进化的角度考虑提出来的方法,19世纪达尔文在大量观察基础上总结了大自然进化规律 ...
- [转]windows下安装python MySQLdb及问题解决
转自 https://blog.csdn.net/ping523/article/details/54135228#commentBox 之前按照网络上搜罗的教程安装了python-mysql(1.2 ...
- python---基础知识回顾(十)进程和线程(进程)
前戏:进程和线程的概念 若是学过linux下的进程,线程,信号...会有更加深刻的了解.所以推荐去学习下,包括网络编程都可以去了解,尤其是对select,poll,epoll都会有更多的认识. 进程就 ...