弱分类器的进化--Bagging、Boosting、Stacking
- 一般来说集成学习可以分为三大类:
- 用于减少方差的bagging
- 用于减少偏差的boosting
- 用于提升预测结果的stacking
一、Bagging(1996)
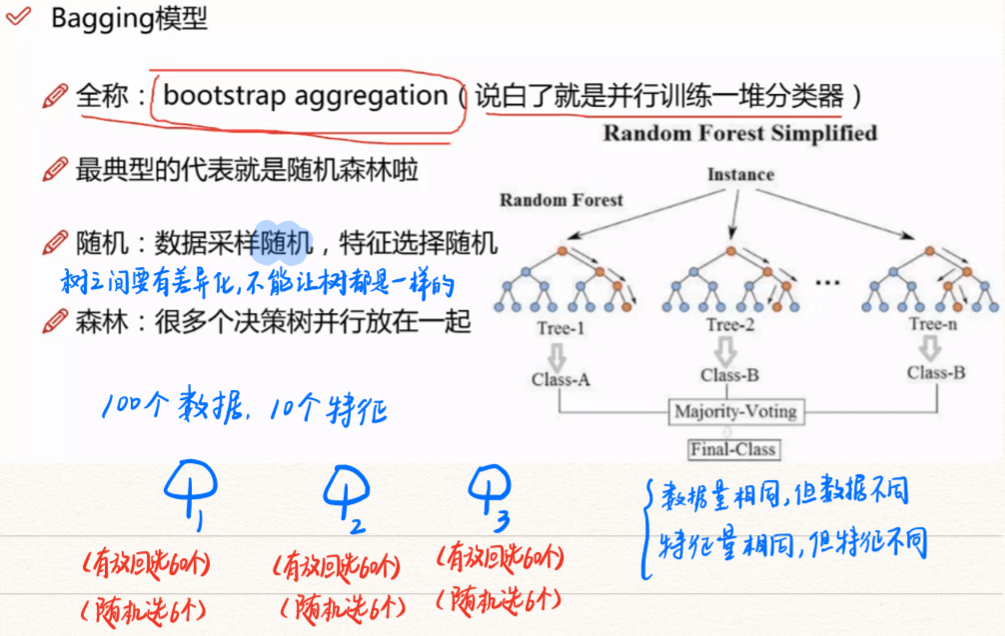
1、随机森林(1996)
RF = bagging + random-combination C&RT
(1)RF介绍
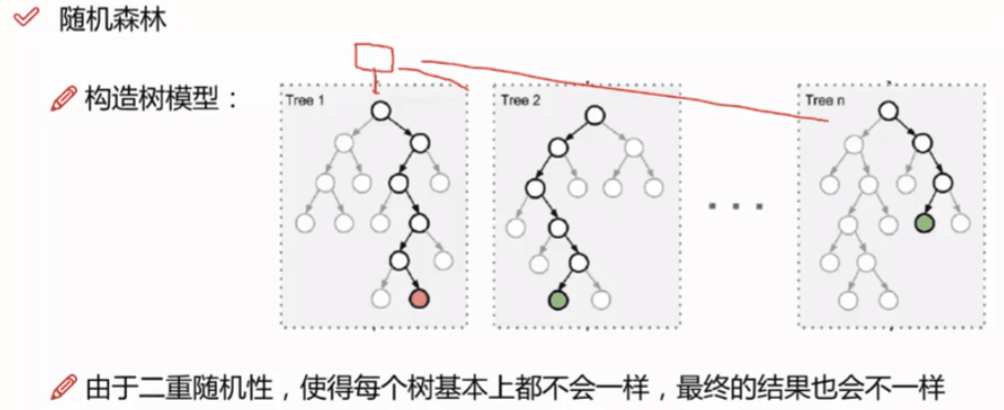
- RF通过Bagging的方式将许多个CART组合在一起,不考虑计算代价,通常树越多越好。
- RF中使用CART没有经过剪枝操作,一般会有比较大的偏差(variance),结合Bagging的平均效果可以降低CART的偏差。
- 在训练CART的时候,使用有放回的随机抽取样本(bootstraping)、随机的抽取样本的特征、甚至将样本特征通过映射矩阵P投影到随机的子空间等技术来增大g(t)的随机性、多样性。
(2)RF算法结构与优势
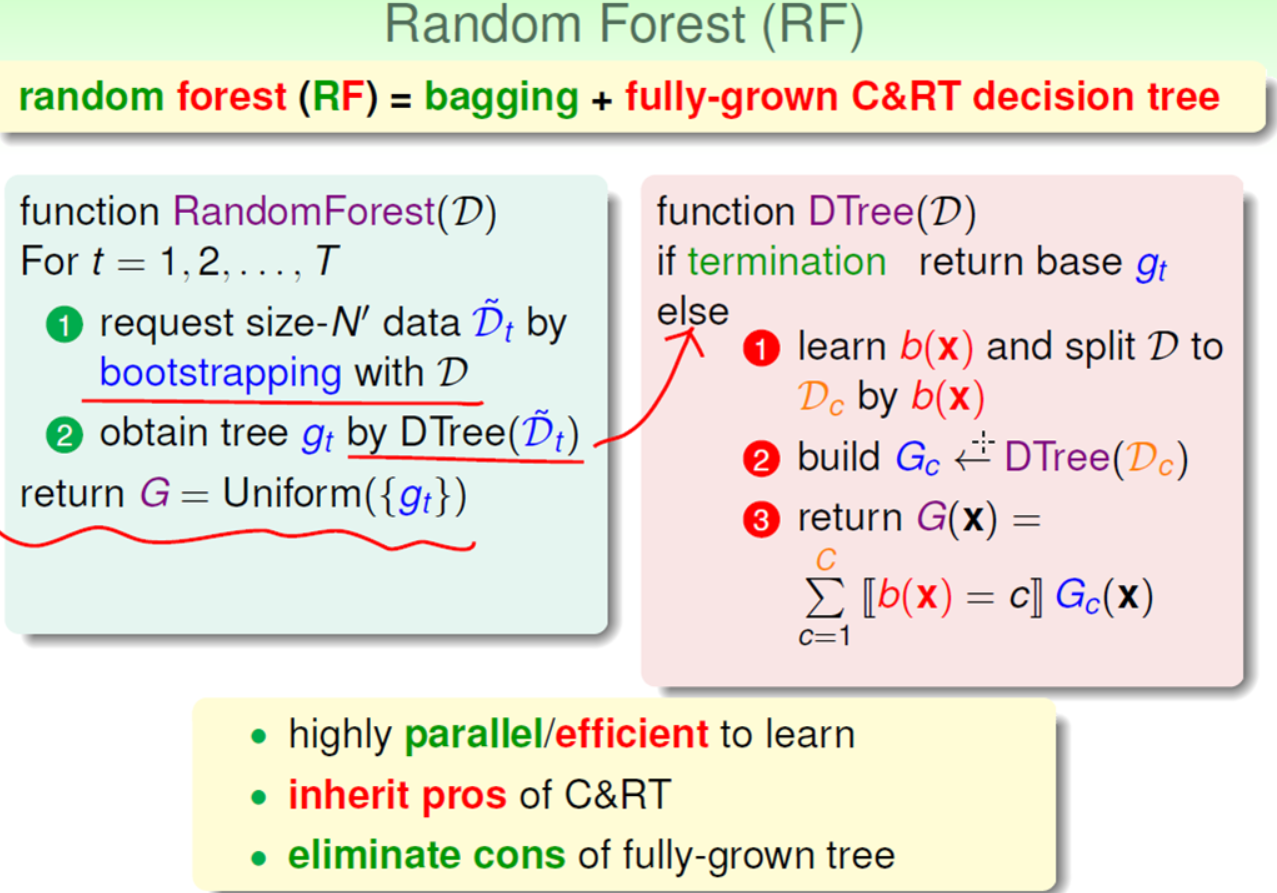
(3)OOB(Out of Bag)和自验证(Automatic Validation)
【1】OOB
RF中使用的有放回的抽样方式(Bootstrapping)会导致能有些样本在某次训练中没有被使用,没有被用到的样本称为OOB(Out-Of-Bag)。
当样本集合很大的时候,如果训练数据的大小和样本集合的大小相同,那么某个样本没有被使用的概率大约为1/e,OOB的大小也约为样本集合的1/e,下面是具体的数学描述。
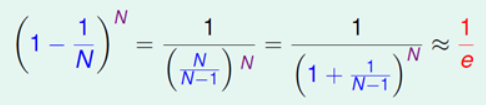

【2】RF Validation
RF 并不注重每棵树的分类效果,实际中也不会用OOB数据来验证g(t),而是使用OOB数据来验证G。但同时为了保证验证数据绝对没有在训练时“偷窥”,使用的G是去掉与测试的OOB相关的g(t)组成的G-。
最后将所有的OOB测试结果取平均。林说:实际中Eoob通常都会非常精确。

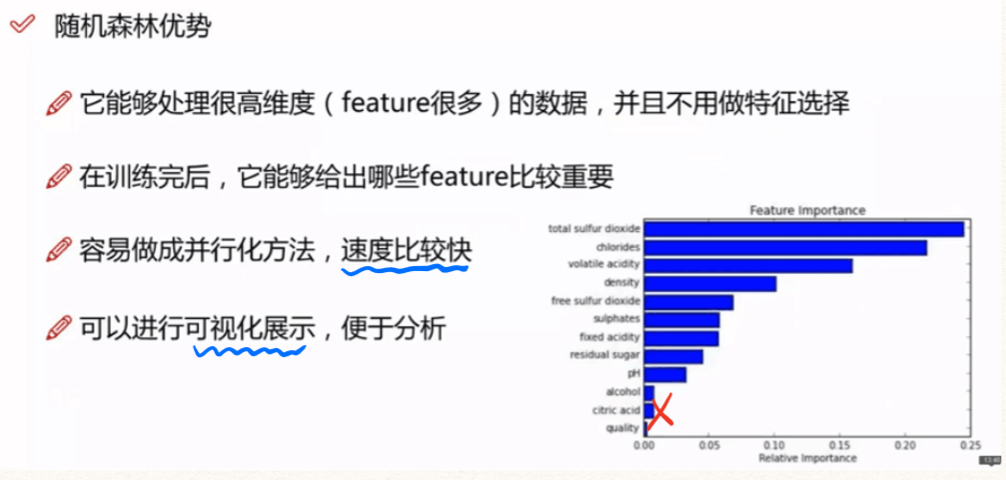
(4)特征选择和排列检验
在实际中,当样本的特征非常多的时候,有时会希望去掉冗余或者与结果无关的特征项,选取相对重要的特征项。

线性模型中,特征项的重要性使用|Wi|来衡量,非线性模型中特征项重要性的衡量一般会比较困难。

RF中使用统计中的工具排列检验(Permutation Test)来衡量特征项的重要性。
N个样本,每个样本d个维度,要想衡量其中某个特征di的重要,根据Permutation Test把这N个样本的di特征项都洗牌打乱,洗牌前后的误差相减就是该特征项重要性。
RF中通常不在训练时使用Permutation Test,而是在Validation 时打乱OOB的特征项,再评估验证,获得特征项的重要性。

(5)RF的应用
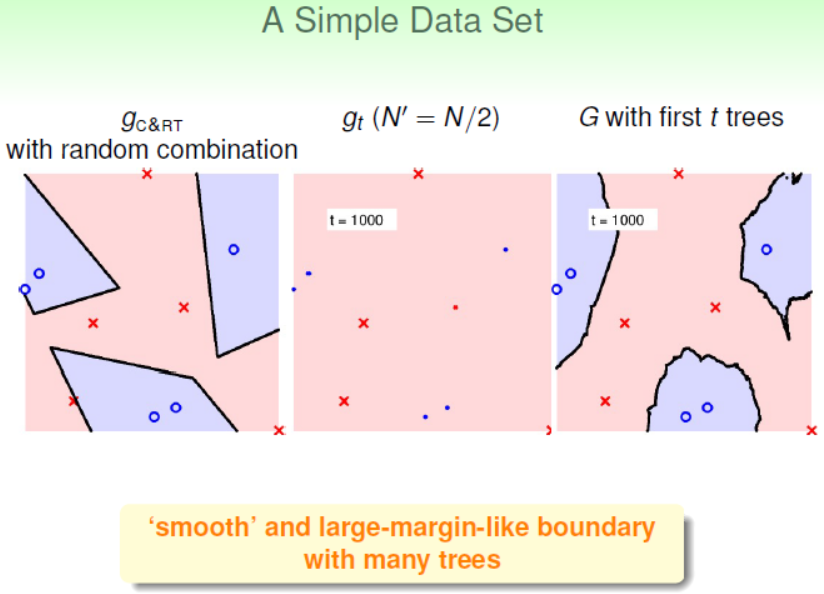
- 在简单数据集上,相比单棵的CART树,RF模型边界更加平滑,置信区间(Margin)也比较大
- 在复杂且有含有噪声的数据集上,决策树通常表现不好;RF具有很好的降噪性,相比而言RF模型也会表现得很好
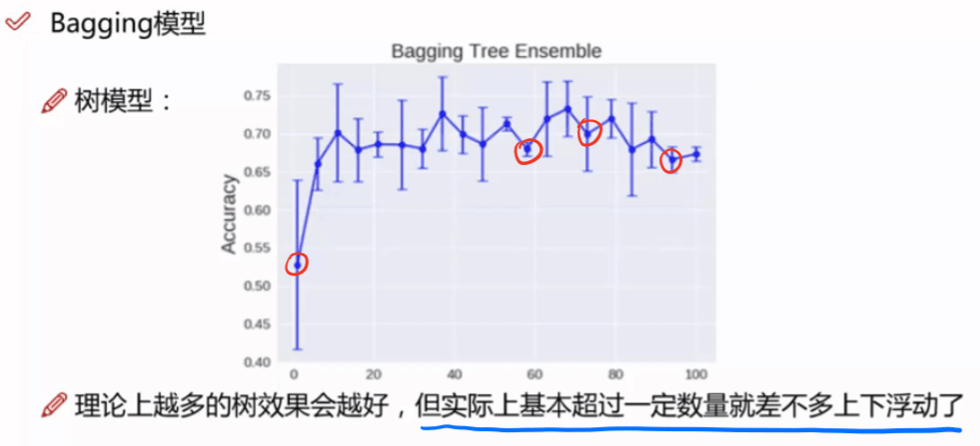
- RF中选多少棵树好呢?总的来说是越多越好!!!实践中,要用足够多的树去确保G的稳定性,所以可以使用G的稳定性来判断使用多少棵树好。


二、Boosting(1999)
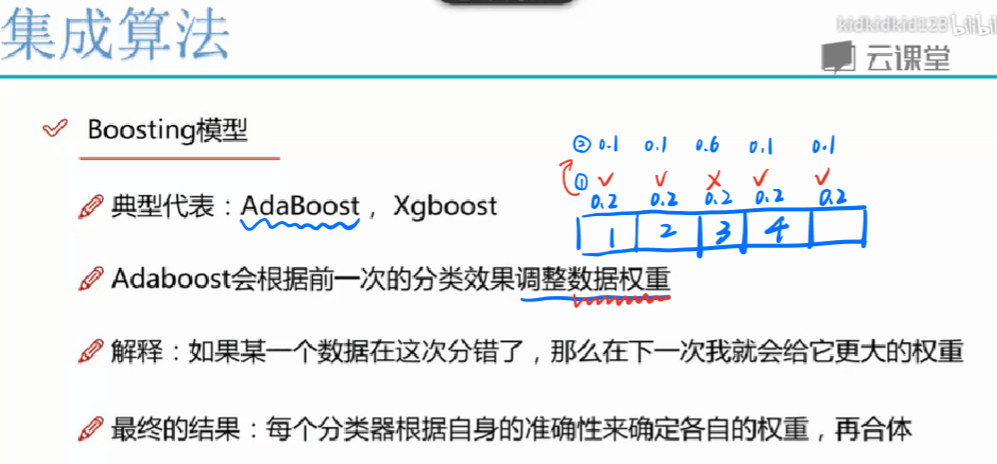
Boosting主要干两件事:调整训练样本分布,使先前训练错的样本在后续能够获得更多关注 ;集成基学习数目


1.GBDT
2.Adaboost
3.Xgboost
三、stacking


上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对testing data进行预测。在整个第一次的交叉验证完成之后我们将会得到关于当前testing data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型testing data的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对testing set数据预测的5列2000行的数据a1,a2,a3,a4,a5,对testing set的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个training set的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为testing data。让下一层的模型,基于他们进一步训练。
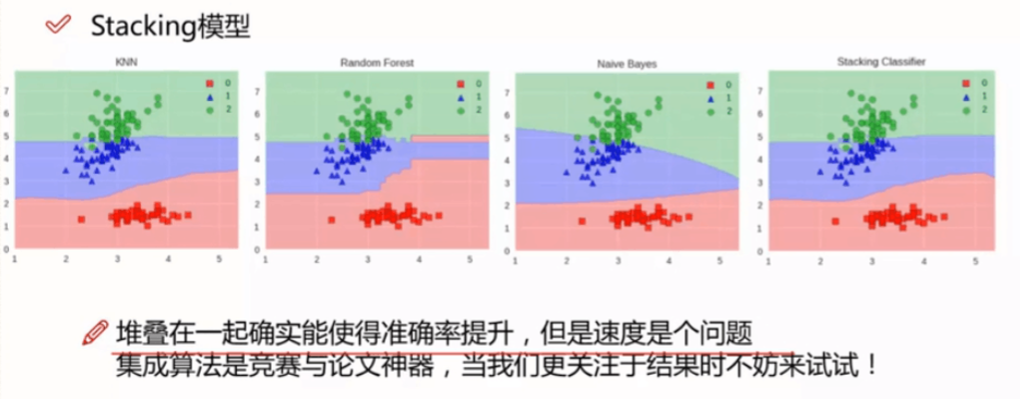
以上即为stacking的完整步骤!
四、总结
1.Bagging和Boosting的区别
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
2.RF、Adabost、GBDT模型优缺点
RF
- 优点:
- 训练可以并行化,对于大规模样本的训练具有速度的优势
- 由于进行随机选择决策树划分特征列表,这样在样本维度比较高的时候,仍然具有比较高 的训练性能
- 给出各个特征的重要性列表
- 于存在随机抽样,训练出来的模型方差小,泛化能力强
- RF实现简单
- 缺点:
- 在某些噪音比较大的特征上,RF模型容易陷入过拟合
- 取值比较多的划分特征对RF的决策会产生更大的影响,从而有可能影响模型的效果
AdaBoost
- 优点:
- 可以处理连续值和离散值
- 模型的鲁棒性比较强
- 解释强,结构简单
- 缺点:
- 对异常样本敏感,异常样本可能会在迭代过程中获得较高的权重值,最终影响模型效果
GBDT
- 优点:
- 可以处理连续值和离散值
- 在相对少的调参情况下,模型的预测效果也会不错
- 模型的鲁棒性比较强
- 缺点:
- 由于弱学习器之间存在关联关系,难以并行训练模型
3.GBDT和XGBoost比较
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
参考文献:
【1】详解stacking过程
弱分类器的进化--Bagging、Boosting、Stacking的更多相关文章
- 机器学习入门-集成算法(bagging, boosting, stacking)
目的:为了让训练效果更好 bagging:是一种并行的算法,训练多个分类器,取最终结果的平均值 f(x) = 1/M∑fm(x) boosting: 是一种串行的算法,根据前一次的结果,进行加权来提高 ...
- 机器学习 - 算法 - 集成算法 - 分类 ( Bagging , Boosting , Stacking) 原理概述
Ensemble learning - 集成算法 ▒ 目的 让机器学习的效果更好, 量变引起质变 继承算法是竞赛与论文的神器, 注重结果的时候较为适用 集成算法 - 分类 ▒ Bagging - bo ...
- Ensemble Learning: Bootstrap aggregating (Bagging) & Boosting & Stacked generalization (Stacking)
Booststrap aggregating (有些地方译作:引导聚集),也就是通常为大家所熟知的bagging.在维基上被定义为一种提升机器学习算法稳定性和准确性的元算法,常用于统计分类和回归中. ...
- Bagging, Boosting, Bootstrap
Bagging 和 Boosting 都属于机器学习中的元算法(meta-algorithms).所谓元算法,简单来讲,就是将几个较弱的机器学习算法综合起来,构成一个更强的机器学习模型.这种「三个臭皮 ...
- Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting的区别
引自http://blog.csdn.net/xianlingmao/article/details/7712217 Jackknife,Bootstraping, bagging, boosting ...
- 利用AdaBoost方法构建多个弱分类器进行分类
1.AdaBoost 思想 补充:这里的若分类器之间有比较强的依赖关系;对于若依赖关系的分类器一般使用Bagging的方法 弱分类器是指分类效果要比随机猜测效果略好的分类器,我们可以通过构建多个弱分类 ...
- 【机器学习】Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting
Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting 这些术语,我经常搞混淆, ...
- 【AdaBoost算法】弱分类器训练过程
一.加载数据(正样本.负样本特征) def loadSimpData(): #样本特征 datMat = matrix([[ 1. , 2.1, 0.3], [ 2. , 1.1, 0.4], [ 1 ...
- 用cart(分类回归树)作为弱分类器实现adaboost
在之前的决策树到集成学习里我们说了决策树和集成学习的基本概念(用了adaboost昨晚集成学习的例子),其后我们分别学习了决策树分类原理和adaboost原理和实现, 上两篇我们学习了cart(决策分 ...
随机推荐
- java基础---->使用Itext生成数据库文档
这里简单的介绍一下使用Itext生成数据库表的文档.于是我们领教了世界是何等凶顽,同时又得知世界也可以变得温存和美好. 生成数据库的文档 一.maven项目需要引入的jar依赖 <depende ...
- rc.sysinit 解析
$# :它可抓出 positional parameter 的數量,即脚本后面的参数有几个 $@和$*表示全部参数,但不包含脚本名,即$0,如果在command line上跑 my.sh p1 “p2 ...
- 1007: [HNOI2008]水平可见直线[维护下凸壳]
1007: [HNOI2008]水平可见直线 Time Limit: 1 Sec Memory Limit: 162 MBSubmit: 7184 Solved: 2741[Submit][Sta ...
- 使用 intellijIDEA + gradle构建的项目如何debug
在intellij IDEA里建立gradle项目(使用jett插件的web项目) 使用intellijIDEA提供的debug无效(无法进入断点) 摸索了一下,通过远程调试的方法来进行调试是可行的 ...
- 解决启动Distributed Transaction Coordinator服务出错的问题
解决启动Distributed Transaction Coordinator服务出错的问题 "Windows 不能在 本地计算机 启动 Distributed Transaction ...
- 近期在看的一段JS(谁能看出我想实现什么功能)
示例代码: <script type="text/javascript"> !function(){ var e=/([http|https]:\/\/[a-zA-Z0 ...
- python2和python3的不同
1.性能 Py3.0运行 pystone benchmark的速度比Py2.5慢30%.Guido认为Py3.0有极大的优化空间,在字符串和整形操作上可 以取得很好的优化结果. Py3.1性能比Py2 ...
- ZOJ 3993 - Safest Buildings - [数学题]
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3993 题意: 给出n幢建筑,每个都以一个点表示,给出点坐标. 有 ...
- 基于Docker部署nodejs应用
基于Docker部署nodejs应用 背景 公司基于Vue.js的项目最近需要部署到云端,因此需要先行在公司内部Docker环境下验证相关技术,因而有本文之前提. 本文展示在Docker容器中,应用部 ...
- POJ_3349_Snowflake Snow Snowflakes
Snowflake Snow Snowflakes Time Limit: 4000MS Memory Limit: 65536K Total Submissions: 43504 Accep ...