机器学习 - 算法 - 集成算法 - 分类 ( Bagging , Boosting , Stacking) 原理概述
Ensemble learning - 集成算法
▒ 目的
让机器学习的效果更好, 量变引起质变
继承算法是竞赛与论文的神器, 注重结果的时候较为适用
集成算法 - 分类
▒ Bagging - bootstrap aggregation
◈ 公式
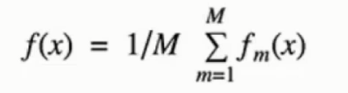
◈ 原理
训练多个分类器取平均, 并行 的训练一堆的分类器
◈ 典例
随机森林

◈ 随机
输入 - 数据源采样随机 - 在原有数据上的进行 60% - 80% 比例的有放回的数据取样
数据量相同, 但是每个树的样本数据各不相同
特征 - 特征选择随机
特征的选择加剧随机性
◈ 森林

多个决策树并行放在一起
每个树的特征数一样, 数据量一样
由于二重的随机性(数据集, 特征) , 每个树基本上都不会一样, 最终的结果也不一样
随机保证了泛化能力, 如果每个树都是一样, 那就无意义了
◈ 优势
能够处理 高纬度 ( feature 很多 ) 的数据, 而且不用做特征选择 (见ps)
在训练后, 可以对 feature 重要程度 进行比对
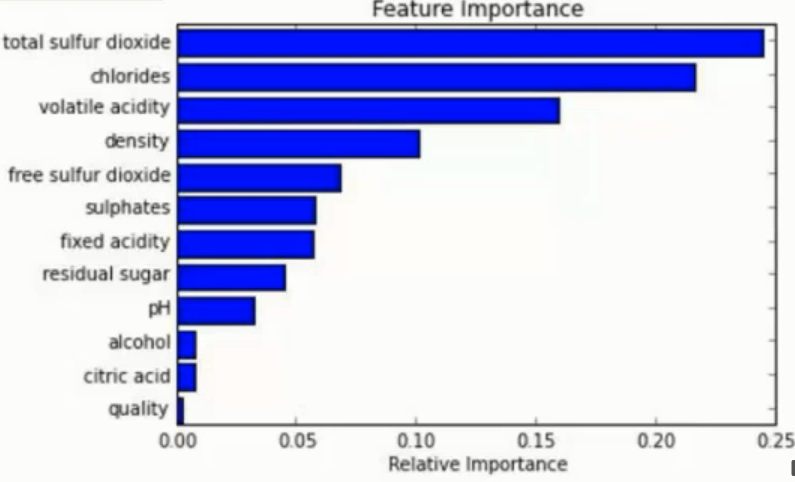
容易做成 并行化 方法, 速度较快
可进行 可视化展示 , 便于分析
◈ ps
特征选择
特征选择的目的是为了查找出权重较大对最终结果影响较大的特征
比如可以使用将某一特征的数据进行完全破坏再用无用数据填充
然后与之前的正常特征数据得到的结果比对从而两个的差值大小判断此特征的有用性
也可以建模忽略预测定的某特征进行与带有此特征的进行比对也是相同的道理
注意 : 破坏后的特征别用 0 之类的一样的数据进行填充, 完全一样的特征就没意义了
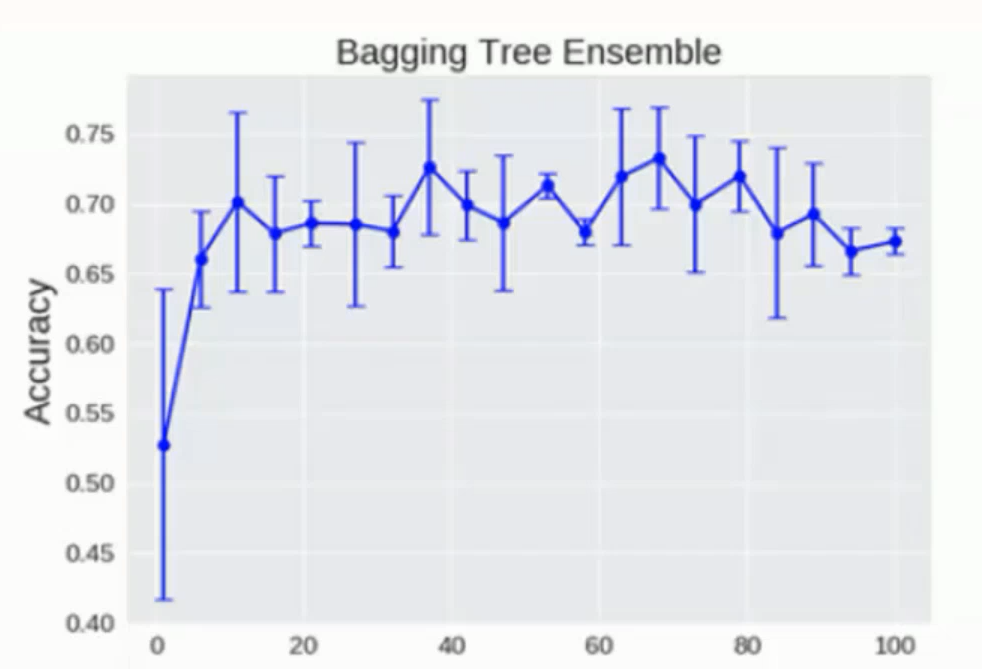
◈ 树模型临界值
随机森林中的树模型理论上是越多越好, 但是其实也会达到临界值
达到一定数量后就会在临界点附近上下浮动
▒ Boosting
◈ 公式
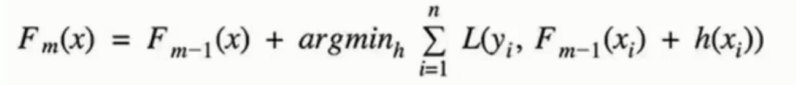
◈ 原理
串行算法, 后面的树基于前面树的残差计算
从弱学习器开始加强, 通过加权来进行训练 ( 加入一颗比原来强的树 )
例子说明:
比如第一颗树预测的结果相差了50, 那么第二颗的任务就是预测这50
然后第二颗预测结果是 30 , 与目标又只差了20, 于是第三颗树的任务就是预测剩余的 20
以此往下类推, 直到尽可能的填满这50的差值让预测结果和真实结果统一
◈ 典例
AdaBoost
Xgboost - 详细的内容 点击这里
◈ AdaBoost 原理
根据前一次的分类效果调整数据权重
如果某一个数据分错了, 那么在下一次的分配中会给与更高的权重使其更加精准
最终的结果根据每个分类器自身的准确性确定各自的权重再合并
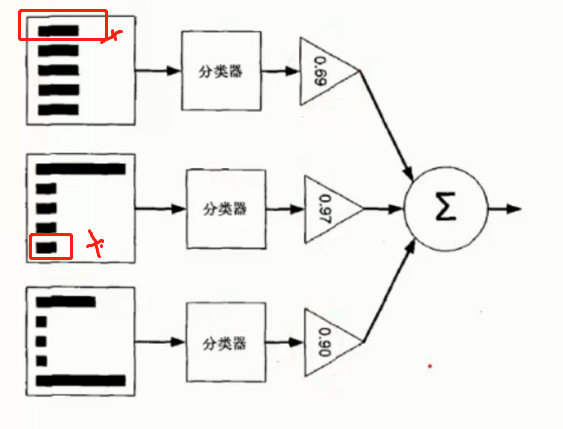
如图所示, 第一个分类器分错了 第一个数据, 因此第二分类器给了第一个数据更高的权重
但是二号又分错了第五个数据, 因此第三个分类器对第五数据更高的权重
▒ Stacking
聚合多个分类或者回归模型. ( 可以分阶段来做 )
◈ 原理
堆叠 直接一堆分类器叠加起来用, 比如有多个算法直接算完了求平均
可以堆叠各种各样的分类器 (KNN, SVM, RF 等等)
分阶段 第一阶段得出各自结果, 第二阶段再用前一阶段的结果来训练
如图, 使用 4 种分类器的结果作为二阶段 LR 分类器的输入再次处理后得到最终结果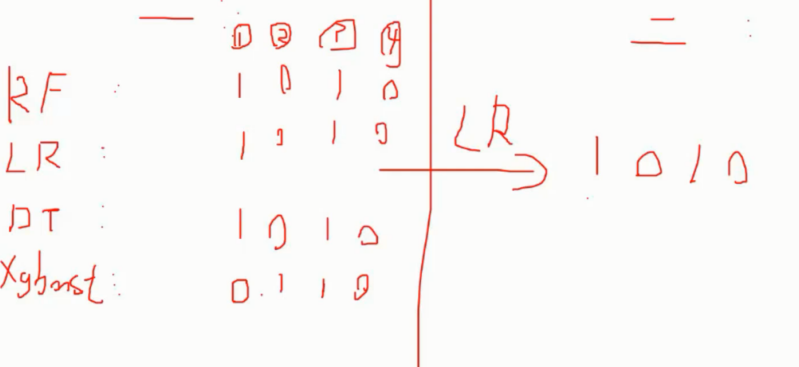
◈ 优势
准确率确实可以提升, 但是速度是个问题
机器学习 - 算法 - 集成算法 - 分类 ( Bagging , Boosting , Stacking) 原理概述的更多相关文章
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
- 机器学习:集成学习(Ada Boosting 和 Gradient Boosting)
一.集成学习的思路 共 3 种思路: Bagging:独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果: Boosting(增强集成学习):集成多个模型,每个 ...
- 【机器学习】Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting
Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting 这些术语,我经常搞混淆, ...
- 机器学习入门-集成算法(bagging, boosting, stacking)
目的:为了让训练效果更好 bagging:是一种并行的算法,训练多个分类器,取最终结果的平均值 f(x) = 1/M∑fm(x) boosting: 是一种串行的算法,根据前一次的结果,进行加权来提高 ...
- 机器学习:集成学习(Bagging、Pasting)
一.集成学习算法的问题 可参考:模型集成(Enxemble) 博主:独孤呆博 思路:集成多个算法,让不同的算法对同一组数据进行分析,得到结果,最终投票决定各个算法公认的最好的结果: 弊端:虽然有很多机 ...
- 一小部分机器学习算法小结: 优化算法、逻辑回归、支持向量机、决策树、集成算法、Word2Vec等
优化算法 先导知识:泰勒公式 \[ f(x)=\sum_{n=0}^{\infty}\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \] 一阶泰勒展开: \[ f(x)\approx ...
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
- 机器学习之KNN算法(分类)
KNN算法是解决分类问题的最简单的算法.同时也是最常用的算法.KNN算法也可以称作k近邻算法,是指K个最近的数据集,属于监督学习算法. 开发流程: 1.加载数据,加载成特征矩阵X与目标向量Y. 2.给 ...
- 集成算法——Ensemble learning
目的:让机器学习效果更好,单个不行,群殴啊! Bagging:训练多个分类器取平均 Boosting:从弱学习器开始加强,通过加权来进行训练 (加入一棵树,比原来要强) Stacking:聚合多个分类 ...
随机推荐
- 交换机配置-----monitor session
目录 交换机配置-----monitor 1.前言 2.monitor session的作用 3.配置命令 4.使用 交换机配置-----monitor 1.前言 本文章适用于Dell Network ...
- JEESZ-SSO解决方案
提醒:文档只是作为一个基础的参考,愿意了解的朋友可以随时咨询. 第一节:单点登录简介 第一步:了解单点登录 SSO主要特点是: SSO应用之间使用Web协议(如HTTPS),并且只有一个登录入口. S ...
- Oralce问题之Oracle ORA-28001:某用户密码过期
解决办法: (1).通过CMD打开命令行窗口,以sysdba连接数据库 SqlPlus / as sysdba (2).通过查询dba_user检查哪些用户过期 Sql>Select UserN ...
- Ping-Pong (Easy Version)的解析
原题链接:http://codeforces.com/problemset/problem/320/B 之前自己做的时候一直读不懂题意,看了大佬的博客才知道是用dfs写,一道暴力搜索大水题https: ...
- ELK架构图示例
这是最简单的一种ELK架构方式.优点是搭建简单,易于上手.缺点是Logstash耗资源较大,运行占用CPU和内存高.另外没有消息队列缓存,存在数据丢失隐患. 此架构由Logstash分布于各个节点上搜 ...
- onpageshow、onpagehide、onload、onunload
onpageshow :在用户浏览网页时触发, 在页面从浏览器缓存中读取时也触发 通过event.persisted 来判断, 如果页面从浏览器的缓存中读取该属性返回 ture,否则返回 false ...
- crontab踩坑(二):Unit crond.service could not be found.
这是因为Ubuntu上的服务名称是cron不是crond.所以你的命令应该是: sudo service cron start
- 2018-2019 ACM-ICPC Brazil Subregional Programming Contest B. Marbles(博弈)
题目链接:https://codeforc.es/gym/101908/problem/B 题意:两个人玩游戏,有 n 块石头,初始坐标为(x,y),一次操作可以将一块石头移动到(x - u,y),( ...
- 05 vue项目01-组件关系、bootstrap
1.django后端项目 1.项目预期 配置前端静态资源 页面展示 2.django项目代码 主url from django.contrib import admin from ...
- 【ArcMap】
1.加载图层(1)内容列表中右键添加数据(2)目录列表中拖拽(3)导航中的添加数据 2.编辑要素(1)选中编辑器点击开始编辑(2)在编辑要素中选中要编辑的要素 选择构造工具 执行编辑操作(3)停止编辑 ...