第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取
实现暂停与重启记录状态
1、首先cd进入到scrapy项目里
2、在scrapy项目里创建保存记录信息的文件夹
3、执行命令:
scrapy crawl 爬虫名称 -s JOBDIR=保存记录信息的路径
如:scrapy crawl cnblogs -s JOBDIR=zant/001
执行命令会启动指定爬虫,并且记录状态到指定目录
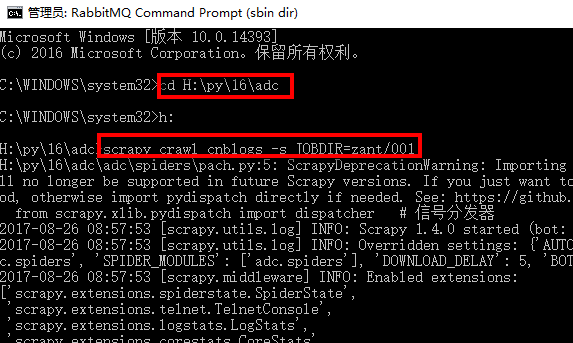
爬虫已经启动,我们可以按键盘上的ctrl+c停止爬虫
停止后我们看一下记录文件夹,会多出3个文件
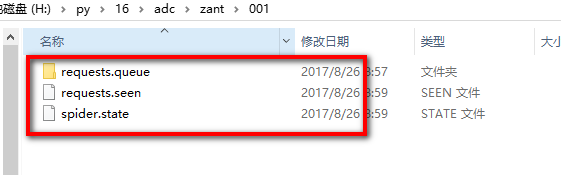
其中的requests.queue文件夹里的p0文件就是URL记录文件,这个文件存在就说明还有未完成的URL,当所有URL完成后会自动删除此文件
当我们重新执行命令:scrapy crawl cnblogs -s JOBDIR=zant/001 时爬虫会根据p0文件从停止的地方开始继续爬取,
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启的更多相关文章
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行.scrapy-splash. splinter 1.chrome谷歌浏览器无界面运行 chrome ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware随机更换user-agent浏览器用户代理 downloadmiddleware介绍中间件是 ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
随机推荐
- linux系统查毒软件ClamAV
安装方法: 长久使用参考: http://www.cnblogs.com/kerrycode/archive/2015/08/24/4754820.html#undefined 临时使用参考: htt ...
- 深入HBase架构解析(一)[转]
前记 公司内部使用的是MapR版本的Hadoop生态系统,因而从MapR的官网看到了这篇文文章:An In-Depth Look at the HBase Architecture,原本想翻译全文,然 ...
- 多媒体文件格式之FLV
[时间:2016-07] [状态:Open] FLV是一个相对简单的多媒体格式,仅支持单节目,也就是说每个FLV只能至多一个音频.至多一个视频.FLV(Flash Video)是Adobe的一个免费开 ...
- Python实现二叉树的左中右序遍历
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/3/18 12:31 # @Author : baoshan # @Site ...
- 应对新型“蠕虫”式比特币勒索软件“wannacry”的紧急措施
1.防火墙屏蔽445端口 命令行操作: 以管理员打开命令行执行以下命令 netsh firewall set opmode enable netsh advfirewall firewall add ...
- django 事务错误 -- Transaction managed block ended with pending COMMIT/ROLLBACK
Request Method: GET Request URL: http://192.168.128.111:8000/×××/××××/ Django Version: 1.4.8 Excepti ...
- 6. 支持向量机(SVM)核函数
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- ajaxfileupload.js ajax上传文件(含application/json)
jQuery.extend({ createUploadIframe: function(id, uri) { //create frame var frameId = 'jUploadFrame' ...
- 怎样用Google APIs和Google的应用系统进行集成(2)----Google APIs的全部的RESTFul服务一览
上篇文章,我提到了,Google APIs暴露了86种不同种类和版本号的API.我们能够通过在浏览器里面输入https://www.googleapis.com/discovery/v1/apis这个 ...
- selenium.common.exceptions.WebDriverException: Message: "Can't load the profile.
记录一下,Selenium在最新版本中修好了这个问题.运行CMD,然后输入 pip install -U selenium