Python 和 Scikit-Learn
Reference:http://mp.weixin.qq.com/s?src=3×tamp=1474985436&ver=1&signature=at24GKibwNNoE9VsETitURyMHzXYeytp1MoUyAFx-2WOZTdPelAdJBv9nkMPyczdr4riYdUZWOaUInIFOxWELVDugvJJxpeEgp5KWDFFtwR8VYalYfPvdWdrmi*Qoq9shyPnROU3Tch32ieV9V8clw==
python data analysis | python数据预处理(基于scikit-learn模块)
现在,很多人想开发高效的算法以及参加机器学习的竞赛。所以他们过来问我:”该如何开始?”。一段时间以前,我在一个俄罗斯联邦政府的下属机构中领导了媒体和社交网络大数据分析工具的开发。我仍然有一些我团队使用过的文档,我乐意与你们分享。前提是读者已经有很好的数学和机器学习方面的知识(我的团队主要由MIPT(莫斯科物理与技术大学)和数据分析学院的毕业生构成)。
这篇文章是对数据科学的简介,这门学科最近太火了。机器学习的竞赛也越来越多(如,Kaggle, TudedIT),而且他们的资金通常很可观。
R和Python是提供给数据科学家的最常用的两种工具。每一个工具都有其优缺点,但Python最近在各个方面都有所胜出(仅为鄙人愚见,虽然我两者都用)。这一切的发生是因为Scikit-Learn库的腾空出世,它包含有完善的文档和丰富的机器学习算法。
请注意,我们将主要在这篇文章中探讨机器学习算法。通常用Pandas包去进行主数据分析会比较好,而且这很容易你自己完成。所以,让我们集中精力在实现上。为了确定性,我们假设有一个特征-对象矩阵作为输入,被存在一个*.csv文件中。
数据加载
首先, 下载ftp://ftp.ics.uci.edu/pub/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data 数据保存到本地磁盘,然后numpy在加载信息,才能对其操作。Scikit-Learn库在它的实现用使用了NumPy数组,所以我们将用NumPy来加载*.csv文件。
import numpy as np
dataset = np.loadtxt("d:\\test.csv",delimiter=",")
X = dataset[:,0:7]
y = dataset[:,8]
我们将在下面所有的例子里使用这个数据组,换言之,使用X特征物数组和y目标变量的值。
数据标准化
我们都知道大多数的梯度方法(几乎所有的机器学习算法都基于此)对于数据的缩放很敏感。因此,在运行算法之前,我们应该进行标准化,或所谓的规格化。标准化包括替换所有特征的名义值,让它们每一个的值在0和1之间。而对于规格化,它包括数据的预处理,使得每个特征的值有0和1的离差。Scikit-Learn库已经为其提供了相应的函数。
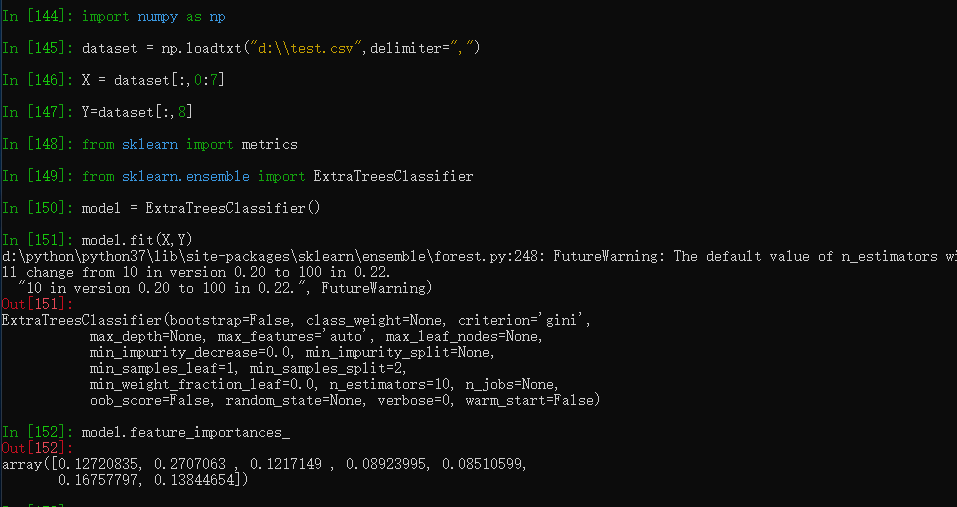
from sklearn import metrics
from sklearn.ensemble import ExtraTreesClassifier
model = ExtraTreesClassifier()
model.fit(X, y)
# display the relative importance of each attribute
print(model.feature_importances_)
特征的选取
毫无疑问,解决一个问题最重要的是是恰当选取特征、甚至创造特征的能力。这叫做特征选取和特征工程。虽然特征工程是一个相当有创造性的过程,有时候更多的是靠直觉和专业的知识,但对于特征的选取,已经有很多的算法可供直接使用。如树算法就可以计算特征的信息量。
其他所有的方法都是基于对特征子集的高效搜索,从而找到最好的子集,意味着演化了的模型在这个子集上有最好的质量。递归特征消除算法(RFE)是这些搜索算法的其中之一,Scikit-Learn库同样也有提供。
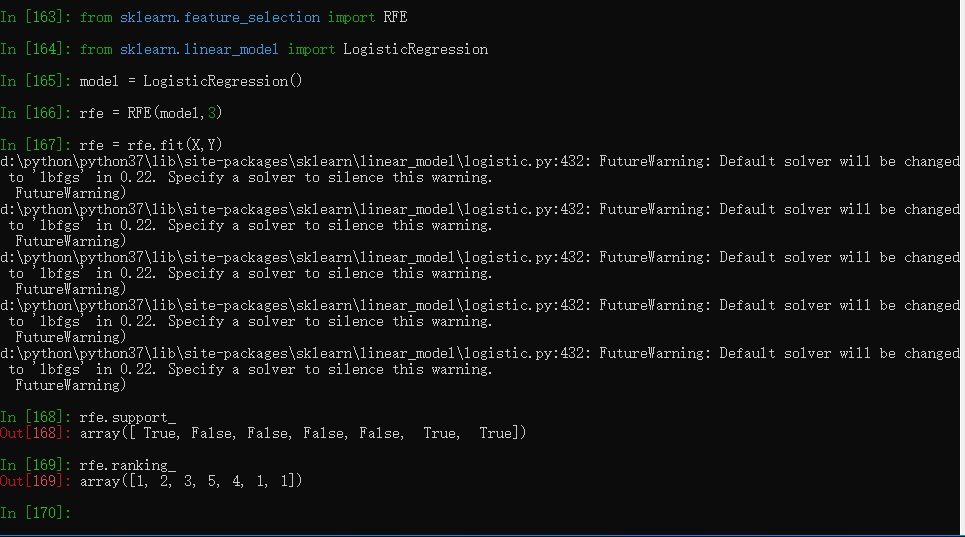
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
# create the RFE model and select 3 attributes
rfe = RFE(model, 3)
rfe = rfe.fit(X, Y)
# summarize the selection of the attributes
print(rfe.support_)
print(rfe.ranking_)
算法的开发
正像我说的,Scikit-Learn库已经实现了所有基本机器学习的算法。让我来瞧一瞧它们中的一些。
逻辑回归
大多数情况下被用来解决分类问题(二元分类),但多类的分类(所谓的一对多方法)也适用。这个算法的优点是对于每一个输出的对象都有一个对应类别的概率。
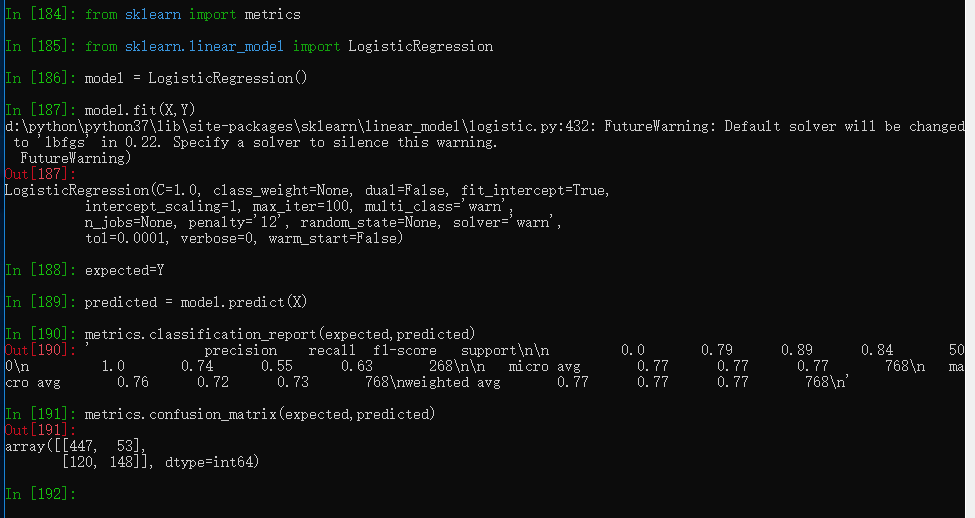
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, Y)
print(model)
# make predictions
expected = Y
predicted = model.predict(X)
# summarize the fit of the model
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))
朴素贝叶斯
它也是最有名的机器学习的算法之一,它的主要任务是恢复训练样本的数据分布密度。这个方法通常在多类的分类问题上表现的很好。
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, Y)
print(model)
# make predictions
expected = y
predicted = model.predict(X)
# summarize the fit of the model
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))
k-最近邻
kNN(k-最近邻)方法通常用于一个更复杂分类算法的一部分。例如,我们可以用它的估计值做为一个对象的特征。有时候,一个简单的kNN算法在良好选择的特征上会有很出色的表现。当参数(主要是metrics)被设置得当,这个算法在回归问题中通常表现出最好的质量。
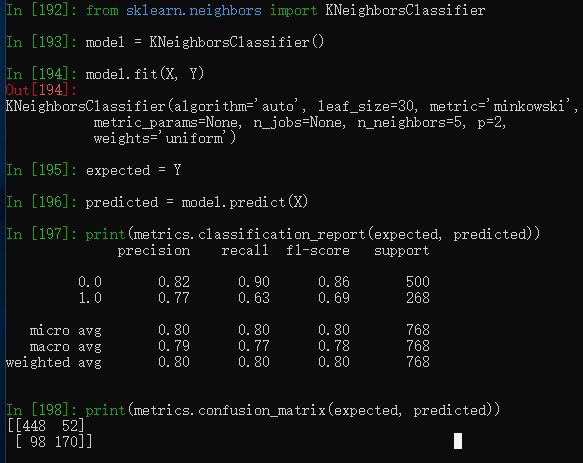
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(X, Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))
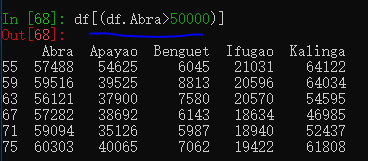
决策树
分类和回归树(CART)经常被用于这么一类问题,在这类问题中对象有可分类的特征且被用于回归和分类问题。决策树很适用于多类分类。
from sklearn import metrics
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X, Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))
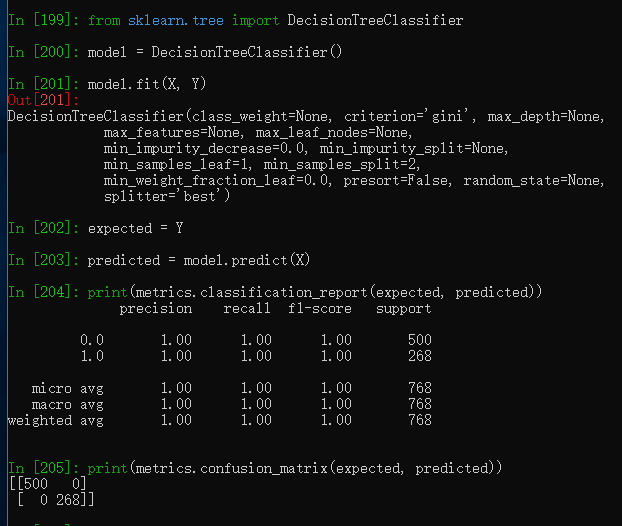
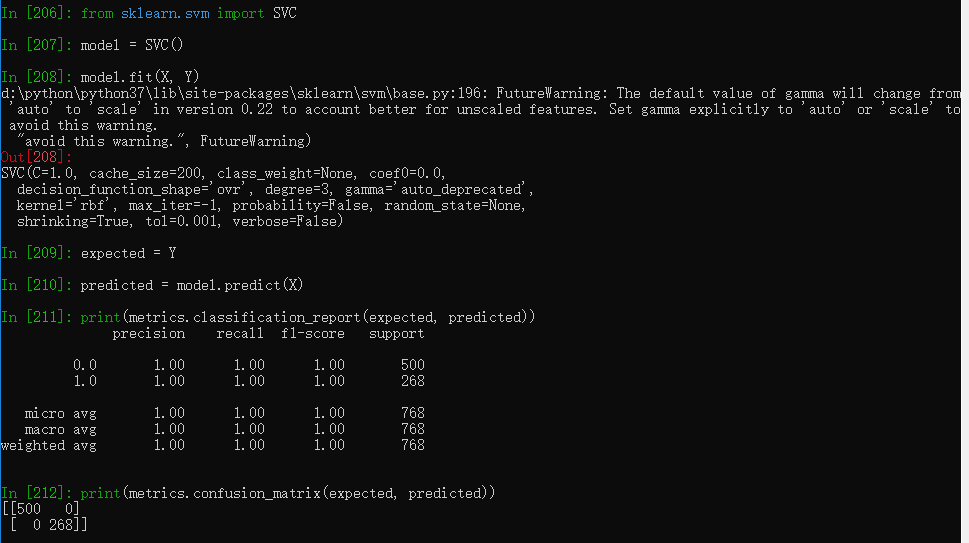
支持向量机
SVM(支持向量机)是最流行的机器学习算法之一,它主要用于分类问题。同样也用于逻辑回归,SVM在一对多方法的帮助下可以实现多类分类。
from sklearn import metrics
from sklearn.svm import SVC
model = SVC()
model.fit(X, Y)
print(model)
expected = Y
predicted = model.predict(X)
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))
除了分类和回归问题,Scikit-Learn还有海量的更复杂的算法,包括了聚类, 以及建立混合算法的实现技术,如Bagging和Boosting。
如何优化算法的参数
在编写高效的算法的过程中最难的步骤之一就是正确参数的选择。一般来说如果有经验的话会容易些,但无论如何,我们都得寻找。幸运的是Scikit-Learn提供了很多函数来帮助解决这个问题。
作为一个例子,我们来看一下规则化参数的选择,在其中不少数值被相继搜索了:
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
alphas = np.array([1,0.1,0.01,0.001,0.0001,0])
model = Ridge()
grid = GridSearchCV(estimator=model, param_grid=dict(alpha=alphas))
grid.fit(X, Y)
print(grid)
print(grid.best_score_)
print(grid.best_estimator_.alpha)

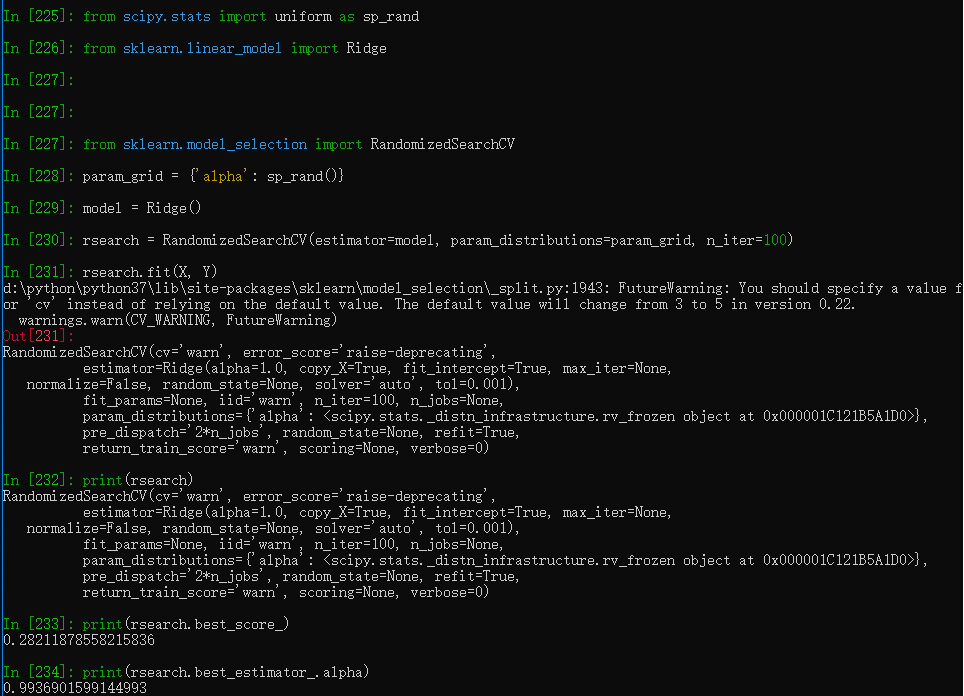
有时候随机地从既定的范围内选取一个参数更为高效,估计在这个参数下算法的质量,然后选出最好的。
import numpy as np
from scipy.stats import uniform as sp_rand
from sklearn.linear_model import Ridge
from sklearn.model_selection import RandomizedSearchCV
param_grid = {'alpha': sp_rand()}
model = Ridge()
rsearch = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=100)
rsearch.fit(X, Y)
print(rsearch)
print(rsearch.best_score_)
print(rsearch.best_estimator_.alpha)
至此我们已经看了整个使用Scikit-Learn库的过程,除了将结果再输出到一个文件中。这个就作为你的一个练习吧,和R相比Python的一大优点就是它有很棒的文档说明。
test.csv
Python 和 Scikit-Learn的更多相关文章
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
- Linear Regression with Scikit Learn
Before you read This is a demo or practice about how to use Simple-Linear-Regression in scikit-lear ...
- Python basic (from learn python the hard the way)
1. How to run the python file? python ...py 2. UTF-8 is a character encoding, just like ASCII. 3. ro ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
随机推荐
- python--异常捕获
#异常捕获---指定异常类型 try: #尝试 fi=open(r'D:\Users\4399-3046\Desktop\test.txt',mode='wb'); fi.write('写入文字'); ...
- js中的new Option默认选中
new Option("文本","值",true,true).后面两个true分别表示默认被选中和有效! //js默认选中 var sel = document ...
- RocketMQ事务消息回查设计方案
用户U1从A银行系统转账给B银行系统的用户U2的处理过程如下:第一步:A银行系统生成一条转账消息,以事务消息的方式写入RocketMQ,此时B银行系统不可见这条消息(Prepare阶段) 第二步:写入 ...
- Unknown lifecycle phase "mvn"
Unknown lifecycle phase "mvn" maven执行命令错误 : 执行输入命令即可,不需要添加 mvn 此处不需要写mvn,而是执行写compile就行,否 ...
- tomcat配置调优与安全总结
http://vekergu.blog.51cto.com/9966832/1672931 tomcat配置调优与安全总结 作为运维,避免不了与tomcat打交道,然而作者发现网络上关于tomcat配 ...
- Java 之 Web前端(二)
1.Cookie (客户端所拥有) a.含义:服务器给浏览器的甜点 b.语法: //创建Cookie Cookie cookie = new Cookie("name", &quo ...
- DDoS攻击与防御(1)
分布式拒绝服务攻击的精髓是,利用分布式的客户端,向服务提供者发起大量看似合法的请求,消耗或长期占用大量资源,从而达到拒绝服务的目的.从不同的角度看,分布式拒绝服务攻击的方法有不同的分类标准.依据消耗目 ...
- spring mvc简单介绍xml版
spring mvc介绍:其实spring mvc就是基于servlet实现的,只不过他讲请求处理的流程分配的更细致而已. spring mvc核心理念的4个组件: 1.DispatcherServl ...
- Xamarin Essentials教程振动Vibration
Xamarin Essentials教程振动Vibration 振动是提醒用户的有效方式,尤其是声音提示效果不明显的场景中,如吵杂的环境中,手机放到包中.在很多的游戏中,振动还用来模拟游戏特效,如 ...
- 牛客国庆集训派对Day1.B.Attack on Titan(思路 最短路Dijkstra)
题目链接 \(Description\) 给定\(n,m,C\)及大小为\((n+1)(m+1)\)的矩阵\(c[i][j]\).平面上有\((n+1)(m+1)\)个点,从\((0,0)\)编号到\ ...