exactly-once和kafka
Exactly-Once的概念是指"恰好一次",简单讲就是同一个数据只会被处理一次,应用有机质保证不会重复处理同一条数据(如果数据因为因为网络业务异常被发送多次);Exactly-Onece实现了操作的等幂性,如果在kafka处理数据全流程保证历史/重新处理数据结果都是一致的。
Kafka处理数据的这种等幂性要从三个点说起:
1. 重复发送数据等幂性:kafka客户端每次传输数据都会传送pid以及seqNo,前者说明的producer的标志,后者是当前producer消息的序列,这两个数据可以保证数据的唯一性;当出现重复数据,可以根据这两个字段进行判断;该特性默认关闭,需要设置enable.idempotence=true
2. 数据处理数据的等幂性:borker通过"事务"机制实现了分配数据到topic和partition之间的等幂。
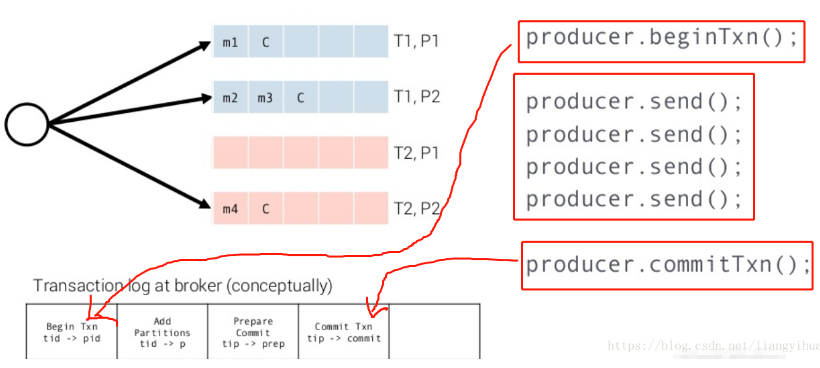
注意,虽然代码中采用producer,但是这部分流程是在broker中实现的,我们看到kafka中通过设置了事务处理,实现了要么全部写入,要全部不写入;回滚通过读取日志实现(这个和mysql的binlog很类似)。
3. 消息的消费,注意消息消费也不是原子操作,而是有一套流程的:1)消息消费;2)消息的处理;3)把消息处理结果发送到某个topic中;4)偏移量发送到指定的topic中。前两部不是很清楚意思,有些混淆,但是后面两步通常会被忽略;保证exactly onece的机制第二部类似,对于这四个步骤,都会放到一个事务中,操作流程将会记录到Transaction Log中。
同样的消息处理的exactly因为都是有一定的成本的,默认是关闭,打开:processing.guarantee="exactly-once "
消息传输保障除了exactly-once之外,还有两种,分别是:
at most once:这个机制是指客户端数据最多传一次即可保证成功,简单讲就是完全没有数据保障,客户端传输一次就完事,网络异常,处理故障丢数据不再关心;
at least onece:这个是kafka默认的机制,就是数据可能会被传输多次,相同的数据可能会被处理多次,且处理过程不具有等幂性;即有重复的可能性(默认不会校验pid以及seqNo是否有重复)
其实我们看到,传输保障并不是描述服务器端的机制,而是是客户端和服务器端(生产者-消费者)共通协作实现的。
参考:
https://blog.csdn.net/liangyihuai/article/details/82931140
kafka的exactly once机制描述的很清晰(本博客中图片就是来自于此文)
https://www.cnblogs.com/bonelee/p/6360644.html
https://www.cnblogs.com/foreach-break/p/distributed_system_and_transaction.html#_3
解释传输保障的三个级别,描述的还是比较清晰的
exactly-once和kafka的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧. 本篇不谈论 Kafka 和其他的一些消息 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- .net windows Kafka 安装与使用入门(入门笔记)
完整解决方案请参考: Setting Up and Running Apache Kafka on Windows OS 在环境搭建过程中遇到两个问题,在这里先列出来,以方便查询: 1. \Jav ...
- kafka配置与使用实例
kafka作为消息队列,在与netty.多线程配合使用时,可以达到高效的消息队列
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- Kafka副本管理—— 为何去掉replica.lag.max.messages参数
今天查看Kafka 0.10.0的官方文档,发现了这样一句话:Configuration parameter replica.lag.max.messages was removed. Partiti ...
- Kafka:主要参数详解(转)
原文地址:http://kafka.apache.org/documentation.html ############################# System ############### ...
- kafka
2016-11-13 20:48:43 简单说明什么是kafka? Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息 ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
随机推荐
- C/C++.判断文件是否存在(_access)
1. int _access(char* path,int mode)头文件<io.h>功能:确定文件或文件夹的访问权限.如果指定的存取方式有效,则函数返回0,否则函数返回-1. 参数pa ...
- java笔记 -- GregorianCalendar和DateFormateSymbols 类方法
java.util.GregorianCalendar new GregorianCalendar() 构造一个日历对象, 用于表示默认地区,默认时区的当前时间. new GregorianCalen ...
- js的点滴2
博客: 1.大牛博客:每一篇博客都需要仔细的看.http://blog.csdn.net/hongchh/article/details/54744318 2.layui:的作者 贤心的博客:http ...
- vuejs点滴
博客0.没事的时候可以看的一些博客:https://segmentfault.com/a/1190000005832164 http://www.tuicool.com/articles/vQBbii ...
- 机器学习之 XGBoost和LightGBM
目录 1.基本知识点简介 2.梯度提升树GBDT算法 2.1 思路和原理 2.2 梯度代替残差建立CART回归树 3.XGBoost提升树算法 3.1 XGBoost原理 3.2 XGBoost中损失 ...
- 有关两个jar包中包含完全相同的包名和类名的加载问题
首先从表现层介绍,后续后深入原理. 1,先简单介绍maven如何生成jar文件方便测试 <plugin> <artifactId>maven-assembly-plugin&l ...
- 创建spark_读取数据
在2.0版本之前,使用Spark必须先创建SparkConf和SparkContext,不过在Spark2.0中只要创建一个SparkSession就够了,SparkConf.SparkContext ...
- iOS应该具备知识点
序言 我相信很多人都在说,iOS行业不好了,iOS现在行情越来越难了,失业的人比找工作的人还要多.失业即相当于转行,跳槽即相当于降低自己的身价.那么做iOS开发的你,你是否在时刻准备着跳槽或者转行了. ...
- Spring Boot + Spring Cloud 实现权限管理系统 (系统服务监控)
系统服务监控 新建监控工程 新建Spring Boot项目,取名 kitty-monitor,结构如下. 添加项目依赖 添加 spring boot admin 的相关依赖. pom.xml < ...
- Mac下安装Apache
没错,这一篇又是因为头头给我安排的任务得出来的总结. 本身Mac是有自带的Apache,但是对并发量有限制,这个可以在系统的配置参数里面看,所以本人决定重新安装一个,来,请按照下面的流程来走: 一.下 ...