在Pycharm上编写WordCount程序
本篇博客将给大家介绍怎么在PyCharm上编写运行WordCount程序。
第一步 下载安装PyCharm
下载Pycharm
PyCharm的下载地址(Linux版本)。
下载完成后你将得到一个名叫:pycharm-professional-2018.2.4.tar.gz文件。我们选择的是正版软件,学生可申请免费使用。详细信息请百度。
安装PyCharm
执行以下命令解压文件:
- cd ~/下载
- tar -xvf pycharm-professional-2018.2.4.tar.gz
这时候我们可以在下载目录看到一个pycharm-2018.2.4文件夹。接下来我们把它放到/usr/local下,并且重命名
- sudo mv ./pycharm-2018.2.4 /usr/local/pycharm
然后我们要执行pycharm.sh文件,完成首次安装:
- cd /usr/local/pycharm/bin
- ./pycharm.sh
等待之后我们可以看到如下图界面: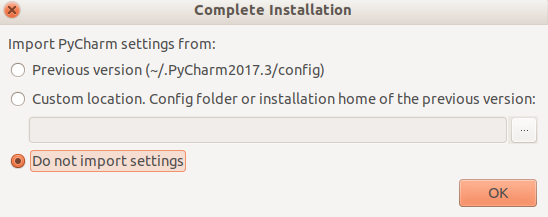
选择不导入设置,点击OK。然后我们会看到以下界面: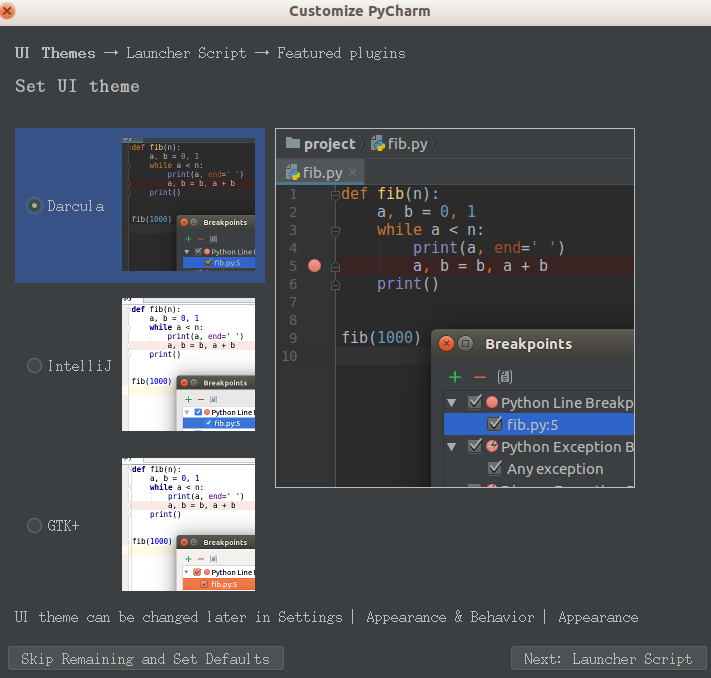
选择左下角“Skip Remaining and Set Defaults”,默认设置即可,本人更偏爱白色,所以后面的截图会跟大家不一样,但是没有影响。
配置环境变量
配置环境变量的意义在于我们以后不需要每次都到pycharm文件夹下去启动程序。
- sudo vim ~/.bashrc
将下面内容复制到文件的开头部分。
- #pycharm
- export PyCharm_HOME=/usr/local/pycharm
- export PATH=${PyCharm_HOME}/bin:$PATH
完成以上操作后你就可以在终端直接使用:pycharm.sh命令打开程序了。
第二步 创建并运行WordCount程序
创建工程文件
在开始界面选择“Create New Project”
接下来按照下图操作,修改图中两处红框内容,project起名为WordCount,python选择3.6版本,没有的请安装。
最后点击Create,完成项目创建。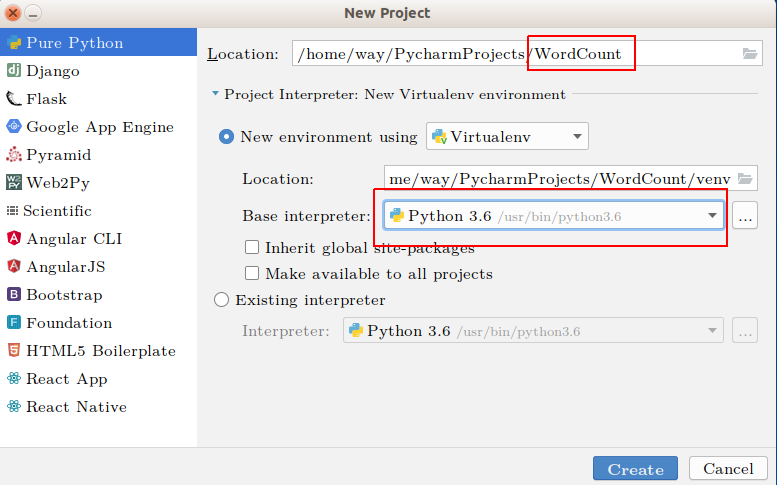
创建python文件
右键点击WordCount文件夹,选择New -> Python File,可以看到以下界面,我们取文件名为WordCount。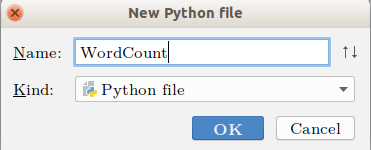
然后我们在WordCount.py中复制以下代码:
- #-*- coding:utf8-*-
- from pyspark import SparkConf, SparkContext
- conf = SparkConf().setAppName("WordCount").setMaster("local")
- sc = SparkContext(conf=conf)
- inputFile = "hdfs://localhost:9000/user/way/word.txt"
- textFile = sc.textFile(inputFile)
- wordCount = textFile.flatMap(lambda line : line.split(" ")).map(lambda word : (word, 1)).reduceByKey(lambda a, b : a + b)
- wordCount.foreach(print)
这时候你会看到PyCharm自动报错,代码中带红色波浪线部分为PyCharm提示的错误。缺少pyspark等。接下来我们要利用pycharm自动帮我们安装pyspark。把鼠标放到带红色波浪线的地方,并且将光标点进错误的地方,如下图,会出现一个小红灯泡。
点击小红灯泡,选择“Install package pyspark”,等待程序自动安装完成,在程序底部可看到正在安装的提示。
补充说明一下代码。
我的inputFile = “hdfs://localhost:9000/user/way/word.txt”
这个文件是放在hdfs伪分布式文件系统上的,这时候你必须开启hdfs文件系统,相关操作查看实验室相关博客。
你也可以选择本地文件inputFile = “file:///home/way/桌面/word.txt”。 当然在这些位置你必须有这个word.txt文件。
Pycharm运行WordCount
然后你可以右键点击代码页面,选择Run “WordCount”。可以看到以下结果: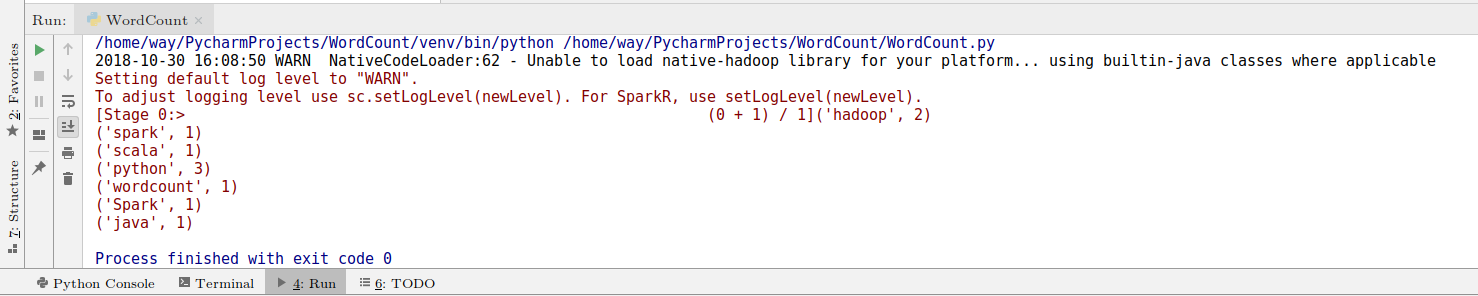
提交到spark运行
我们也可以把代码提交到Spark运行,具体方法是:
打开终端,打开Spark安装目录,并执行提交任务命令:
- cd /usr/local/spark/
- ./bin/spark-submit /home/way/PycharmProjects/WordCount/WordCount.py
翻一下我们的输出信息可以找到以下结果: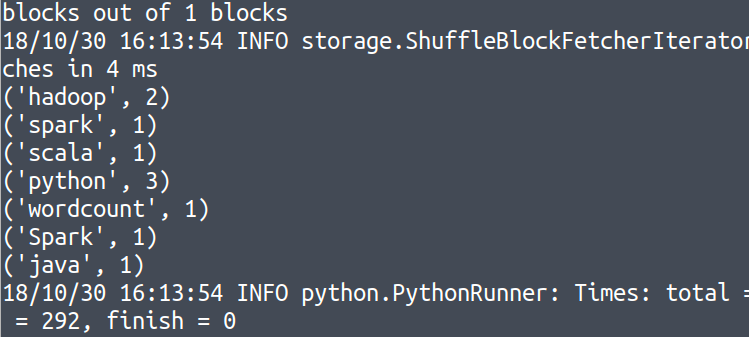
至此我们完成了在pycharm用python编写wordcount程序的实验。

在Pycharm上编写WordCount程序的更多相关文章
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- indows Eclipse Scala编写WordCount程序
Windows Eclipse Scala编写WordCount程序: 1)无需启动hadoop,因为我们用的是本地文件.先像原来一样,做一个普通的scala项目和Scala Object. 但这里一 ...
- Spark在Yarn上运行Wordcount程序
前提条件 1.CDH安装spark服务 2.下载IntelliJ IDEA编写WorkCount程序 3.上传到spark集群执行 一.下载IntellJ IDEA编写Java程序 1.下载IDEA ...
- 在Spark上运行WordCount程序
1.编写程序代码如下: Wordcount.scala package Wordcount import org.apache.spark.SparkConf import org.apache.sp ...
- 在Linux上编写C#程序
自从C#开源之后,在Linux编写C#程序就成了可能.Mono-project就是开源版本的C#维护项目.在Linux平台上使用的C#开发工具为monodevelop.安装方式如下: 首先需要安装一些 ...
- 编写wordcount程序
一.程序概述 1.此次编写的程序为邹欣老师<构建之法>科书2.4.2 wordcount程序. 2.我写的wordcount程序要实现的功能整体可以总结为: ① 统计word文档中的字符数 ...
- 第一天:学会如何在pycharm上编写第一条robotframework用例
---恢复内容开始--- 1.python环境的安装和依赖包的下载
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 020_自己编写的wordcount程序在hadoop上面运行,不使用插件hadoop-eclipse-plugin-1.2.1.jar
1.Eclipse中无插件运行MP程序 1)在Eclipse中编写MapReduce程序 2)打包成jar包 3)使用FTP工具,上传jar到hadoop 集群环境 4)运行 2.具体步骤 说明:该程 ...
随机推荐
- var_dump — 打印变量的相关信息
<?php $a = array( 1 , 2 , array( "a" , "b" , "c" )); var_dump ( $a ...
- vue 的全局拦截器
使用拦截器 你可以截取请求或响应在被 then 或者 catch 处理之前 mounted:function(){ Vue.http.inserceptors.push(function(resque ...
- SimpleDateFormat-多线程问题
SimpleDateFormat-多线程问题: SimpleDateFormat类在多线程环境下中处理日期,极易出现日期转换错误的情况 import java.text.ParseException; ...
- ENCODE:DNA 分子元件的百科全书
ENCODE(DNA分子元件的百科全书)是由国家人类基因研究所(NHGRI)资助的一个国际研究联盟, 该联盟的目标是:建立一份综合的人类基因组功能元件的清单,这些基本元件包括那些直接作用蛋白质和RNA ...
- 100722E The Bookcase
传送门 题目大意 给你一些书的高度和宽度,有一个一列三行书柜,要求放进去书后,三行书柜的高的和乘以书柜的宽度最小.问这个值最小是多少. 分析 我们可以先将所有书按照高度降序排好,这样对于每一层只要放过 ...
- hdu6331 Problem M. Walking Plan
传送门 题目大意 给你一个n点m条边的有向图,q次询问,给定s,t,k,求由s到t至少经过k条边的最短路. 分析 我们设dp[i][j][k]为从i到j至少经过k条边的最短路,sp[i][j]意为从i ...
- c#继承、多重继承
c#类 1.c#类的继承 在现有类(基类.父类)上建立新类(派生类.子类)的处理过程称为继承.派生类能自动获得基类的除了构造函数和析构函数以外的所有成员,可以在派生类中添加新的属性和方法扩展其功能.继 ...
- MySQL慢日志线上问题分析及功能优化
本文来源于数据库内核专栏. MySQL慢日志(slow log)是MySQL DBA及其他开发.运维人员需经常关注的一类信息.使用慢日志可找出执行时间较长或未走索引等SQL语句,为进行系统调优提供依据 ...
- 编译原理-First集和Follow集
刚学first集和follow集的时候,如果上课老师没有讲明白或者自己没听明白,自己看的时候还真是有点难理解,不过结合着具体的题目可以理解的更快. 先看一下两种集合的求法: First集合的求法: ...
- apache-jmeter-3.1的简单压力测试使用方法
压力测试工具LoadRunner是收费的,而且操作复杂.作为开发人员当然是用apache提供的jmeter,免费容易上手. jmeter下载地址http://jmeter.apache.org/首先下 ...