Spark在Yarn上运行Wordcount程序
前提条件
1.CDH安装spark服务
2.下载IntelliJ IDEA编写WorkCount程序
3.上传到spark集群执行
一.下载IntellJ IDEA编写Java程序
1.下载IDEA
官网地址:http://www.jetbrains.com/idea/ 下载IntlliJ IDEA后,进行安装。
2.新建Java项目
1.点击File
2.点击New Project
3.点击Java
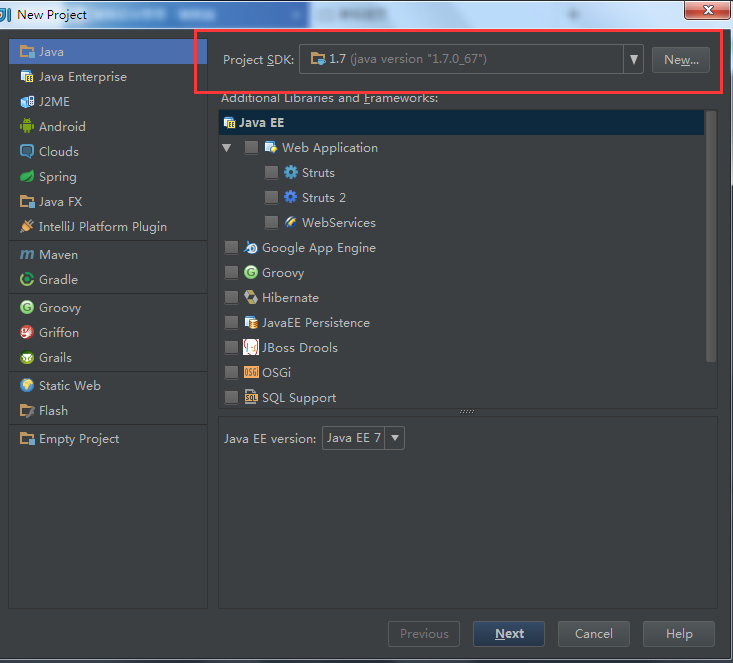
注意:Project SDK要选择本机安装的JDK的位置,由于我的JDK是1.7,所以下面的Java EE version我选择的是Java EE 7
4.点击Next后,出现如下界面,勾选Create project from template,然后点击Next

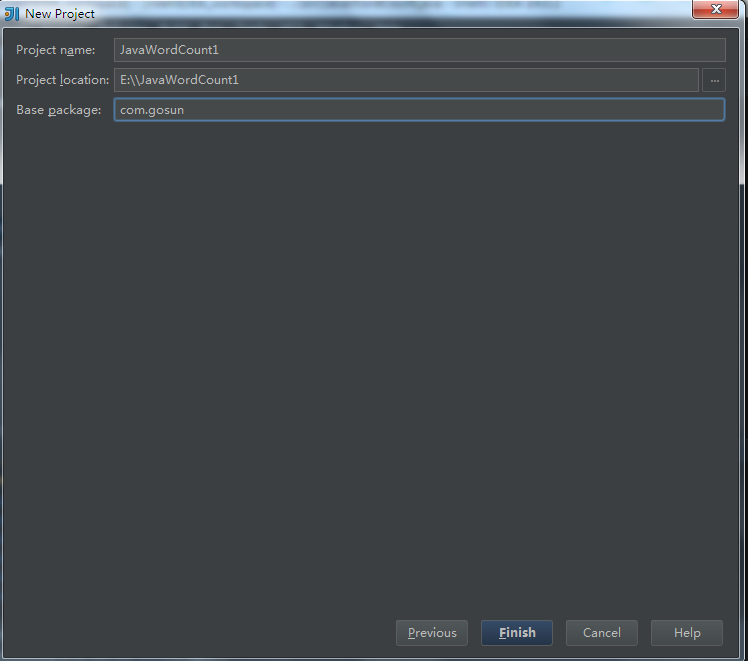
5.点击Next,填写相应的项目名称,package等相关信息
6.点击Finish,,出现如下界面,右键选择Refactor->Rename修改类名为自己想要的类名即可。

7.添加spark-assembly-1.3.0-cdh5.4.2-hadoop2.6.0-cdh5.4.2.jar到项目中
7.1创建名称为lib的目录

7.2将spark-assembly-1.3.0-cdh5.4.2-hadoop2.6.0-cdh5.4.2.jar (在spark集群的位置为:/usr/lib/spark/assembly/lib目录下)copy到lib目录下
然后右键点击jar包选择add Library,完成该动作后,在项目中就可以引用此jar包中的类了。
8.用Java实现WordCount功能
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern; public final class JavaWordCount { private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) {
if(args.length<1){
System.err.print("Usage:JavaWordCount<file>");
System.exit(1);
} SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile(args[0],1);
System.out.println(System.getenv("SPARK_HOME"));
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(SPACE.split(s));
}
}); JavaPairRDD<String,Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s,1);
}
}); JavaPairRDD<String,Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1+i2;
}
}); List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}
}
9.打成jar包
9.1点击File
9.2选择Project Structure
9.3选择Artifacts
可修改右边Name生成jar包的名称
9.4点击OK,完成生成jar包,可在对应的目录下找到刚才生成的jar包
10.将生成的jar包上传到spark某个目录下
11.spark-submit --master yarn-client --name JavaWordCount --class JavaWordCount --executor-memory 1G --total-executor-cores 2 /etc/spark/JavaWordCount.jar hdfs://master:8020/suajing/install.log
其中,红色标注部分根据实际的项目进行修改,
我的项目名称为JavaWordCount,则--name 为JavaWordCount,
我的Class没有pacakage,如果你的class是在某个pacakage底下,则需要将class修改成包+类名全路径,例如:com.gosun.JavaWordCount。
我的jar包放在/etc/spark/目录下,写成/etc/spark/JavaWordCount.jar
hdfs上的文件路径为上面所示。
12.执行结果:未报错就表示执行成功了,可以看到如下统计的结果

Spark在Yarn上运行Wordcount程序的更多相关文章
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- Hadoop 系列文章(三) 配置部署启动YARN及在YARN上运行MapReduce程序
这篇文章里我们将用配置 YARN,在 YARN 上运行 MapReduce. 1.修改 yarn-env.sh 环境变量里的 JAVA_HOME 路径 [bamboo@hadoop-senior ha ...
- Hadoop YARN上运行MapReduce程序
(1)配置集群 (a)配置hadoop-2.7.2/etc/hadoop/yarn-env.sh 配置一下JAVA_HOME export JAVA_HOME=/home/hadoop/bigdata ...
- 在Spark上运行WordCount程序
1.编写程序代码如下: Wordcount.scala package Wordcount import org.apache.spark.SparkConf import org.apache.sp ...
- Yarn上运行spark-1.6.0
目录 目录 1 1. 约定 1 2. 安装Scala 1 2.1. 下载 2 2.2. 安装 2 2.3. 设置环境变量 2 3. 安装Spark 2 3.1. 下载 2 3.2. 安装 2 3.3. ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- Apache Spark源码走读之10 -- 在YARN上运行SparkPi
y欢迎转载,转载请注明出处,徽沪一郎. 概要 “spark已经比较头痛了,还要将其运行在yarn上,yarn是什么,我一点概念都没有哎,再怎么办啊.不要跟我讲什么原理了,能不能直接告诉我怎么将spar ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- Spark standalone简介与运行wordcount(master、slave1和slave2)
前期博客 Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master.slave1和slave2) Spark运行模式概述 1. Stan ...
随机推荐
- wordpress发送测试邮件
下面的邮箱设置使用了qq邮箱的设置 写上接收测试邮件的邮箱 再send test
- 【HDU3652】B-number 数位DP
B-number Problem Description A wqb-number, or B-number for short, is a non-negative integer whose de ...
- React 开发注意事项,注意点
react优势: 仅仅只要表达出你的应用程序在任一个时间点应该长的样子,然后当底层的数据变了,React 会自动处理所有用户界面的更新. 数据变化后,React 概念上与点击“刷新”按钮类似,但仅会更 ...
- hdu 2099 整除的尾数
Problem Description 一个整数,只知道前几位,不知道末二位,被另一个整数除尽了,那么该数的末二位该是什么呢? Input 输入数据有若干组,每组数据包含二个整数a,b(0< ...
- BZOJ4518: [Sdoi2016]征途
Description Pine开始了从S地到T地的征途. 从S地到T地的路可以划分成n段,相邻两段路的分界点设有休息站. Pine计划用m天到达T地.除第m天外,每一天晚上Pine都必须在休息站过夜 ...
- 好的 iOS 代码习惯
一,使用别人的框架时,尽量在退出时移除框架创建的对象 if (_giftToastView) { [_giftToastView removeFromSuperview]; _giftToastVie ...
- js小效果-轮播图
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...
- GPIO裸机编程
作者:李老师,华清远见嵌入式学院讲师. GPIO控制技术是接口技术中最简单的一种.本章通过介绍S5PV210芯片的GPIO控制方法,让读者初步掌握控制硬件接口的方法.本章的主要内容: GPIO功能介绍 ...
- C#常用方法二
public sealed class StringTool { /// <summary> /// 将txt文件读入字符串 /// </summary> /// <pa ...
- POJ3903:Stock Exchange(LIS)
题目链接:http://acm.hust.edu.cn/vjudge/contest/view.action?cid=87125#problem/E 题目: Description The world ...