ElasticSearch-索引库、文档操作
1、elasticsearch的作用
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
2、elasticsearch和lucene
elasticsearch底层是基于lucene来实现的。

elasticsearch的发展历史:
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon 重写了Compass,取名为Elasticsearch。

总结:
什么是elasticsearch?
一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
3、倒排索引
常规的数据库是根据id查询字段在查看是否符合要求。
倒排索引是将查询字段进行分词,然后根据分词为索引,查询包含分词的文档id。
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
总结:正向索引是根据id查文档,而倒排索引是根据文档查id。
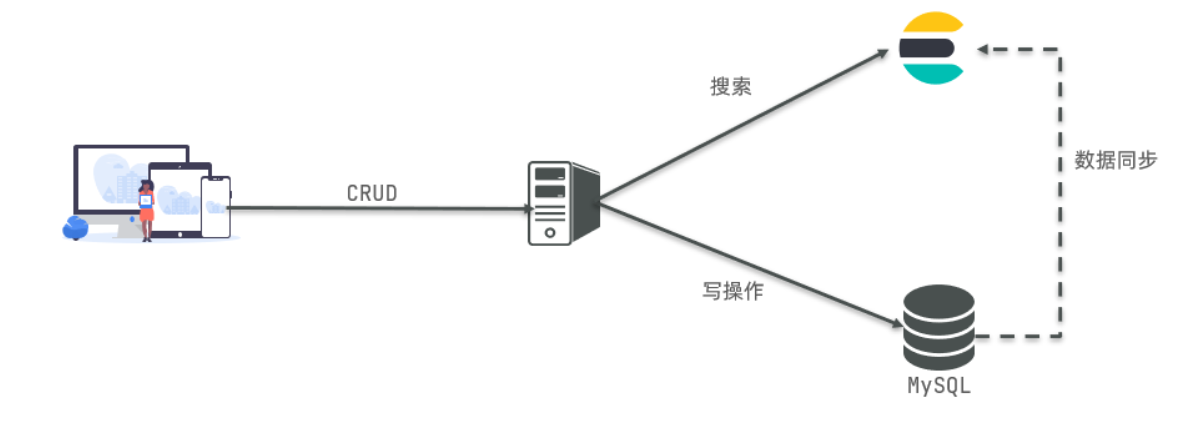
4、mysql与elasticsearch
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
对安全性要求较高的写操作,使用mysql实现
对查询性能要求较高的搜索需求,使用elasticsearch实现
两者再基于某种方式,实现数据的同步,保证一致性

5、安装es、kibana
一、单点es部署
1、创建网络(因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络)
docker network create es-net2、加载镜像(在线下载也行,文件较大下载时间过长)
大家将其上传到虚拟机中,然后运行命令加载即可:
# 导入数据
docker load -i es.tar同理还有
kibana的tar包也需要这样做。3、运行es
运行docker命令,部署单点es:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称
-e "http.host=0.0.0.0":监听的地址,可以外网访问
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小
-e "discovery.type=single-node":非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
--privileged:授予逻辑卷访问权
--network es-net:加入一个名为es-net的网络中
-p 9200:9200:端口映射配置在浏览器中输入:http://192.168.150.101:9200 即可看到elasticsearch的响应结果
二、kibana部署
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
-p 5601:5601:端口映射配置kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana查看运行日志,当查看到下面的日志,说明成功:
此时,在浏览器输入地址访问:http://192.168.150.101:5601,即可看到结果

三、ik分词器安装
1、在线安装ik插件(较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch2、离线安装ik插件(推荐)
查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins显示结果:
[
{
"CreatedAt": "2022-05-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]说明plugins目录被挂载到了:
/var/lib/docker/volumes/es-plugins/_data这个目录中。- 解压缩分词器安装包
- 下面我们需要把课前资料中的ik分词器解压缩,重命名为ik
上传到es容器的插件数据卷中
- 重启容器
# 4、重启容器
docker restart es# 查看es日志
docker logs -f es
5.测试# ik_smart模式分词器
GET /_analyze
{
"analyzer": "ik_smart",
"text": "黑马程序员学习java太棒了"
}# ik_max_word模式分词器
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "李三,给力的,奥利给!"
}3、扩展词词典、停用词词典
略
详细请参考:https://www.aliyundrive.com/s/TPM5GEUm48e
总结:
分词器的作用是什么?
创建倒排索引时对文档分词
用户搜索时,对输入的内容分词
IK分词器有几种模式?
ik_smart:智能切分,粗粒度
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
在词典中添加拓展词条或者停用词条
6、创建索引库和映射
基本语法:
请求方式:PUT
请求路径:/索引库名,可以自定义
请求参数:mapping映射
格式:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
示例:
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "falsae"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
},
// ... 略
}
}
}
7、查询索引库
基本语法:
请求方式:GET
请求路径:/索引库名
请求参数:无
格式:
GET /索引库名
8、修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
语法说明:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
9、删除索引库
语法:
请求方式:DELETE
请求路径:/索引库名
请求参数:无
格式:
DELETE /索引库名
总结:
索引库操作有哪些?
创建索引库:PUT /索引库名
查询索引库:GET /索引库名
删除索引库:DELETE /索引库名
添加字段:PUT /索引库名/_mapping
10、新增文档
语法:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
示例:
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
11、查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
GET /heima/_doc/1
12、删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
示例:
# 根据id删除数据
DELETE /heima/_doc/1
13、修改文档
修改有两种方式:
全量修改:直接覆盖原来的文档
增量修改:修改文档中的部分字段
一、全量修改
全量修改是覆盖原来的文档,其本质是:
根据指定的id删除文档
新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}二、增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}示例:
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}
总结:
文档操作有哪些?
创建文档:POST /{索引库名}/_doc/文档id { json文档 }
查询文档:GET /{索引库名}/_doc/文档id
删除文档:DELETE /{索引库名}/_doc/文档id
修改文档:
全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
增量修改:POST /{索引库名}/_update/文档id { "doc": {字段}}
14、初始化RestClient
1)引入es的RestHighLevelClient依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2)初始化RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
15、创建索引库
/**
* 创建索引库
*/
@Test
public void createHotelIndex() throws IOException {
// 1 新建创建索引库请求
CreateIndexRequest request=new CreateIndexRequest("hotel");
// 2 请求添加索引映射(参数1 为常见索引库的json字符串)
request.source(IndexMappingsContent.INDEX_MAPPINGS, XContentType.JSON);
// 3 客户端调用创建索引库
client.indices().create(request, RequestOptions.DEFAULT);
}
16、删除索引库
/**
* 删除索引库
*/
@Test
public void deleteHotelIndex() throws IOException {
// 1 新建删除索引库请求
DeleteIndexRequest request=new DeleteIndexRequest("hotel");
// 2 客户端调用删除索引库
client.indices().delete(request, RequestOptions.DEFAULT);
}
17、判断索引库是否存在
/**
* 判断索引库是否存在
*/
@Test
public void existHotelIndex() throws IOException {
// 1 新建删除索引库请求
GetIndexRequest request=new GetIndexRequest("hotel");
// 2 客户端调用删除索引库
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("hotel索引库存在么?"+exists);
}
总结:
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
初始化RestHighLevelClient
创建XxxIndexRequest。XXX是Create、Get、Delete
准备DSL( Create时需要,其它是无参)
发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
18、新增文档
/**
* 新增文档
*/
@Test
public void addDocument() throws IOException {
/**
* 从mysql中取一条数据存入es 测试
*/
Hotel hotel = iHotelService.getById(36934L);
HotelDoc hotelDoc = new HotelDoc(hotel);
String jsonString = JSON.toJSONString(hotelDoc); /**
* 创建新增文档请求
*/
IndexRequest request=new IndexRequest("hotel").id(hotelDoc.getId().toString());
/**
* 请求中放入文档json字符串
*/
request.source(jsonString, XContentType.JSON);
/**
* 客户端发起新增文档请求
*/
client.index(request, RequestOptions.DEFAULT);
}
19、查询文档
/**
* 查询文档
*/
@Test
public void getDocument() throws IOException {
/**
* 1 创建获取文档请求
*/
GetRequest request=new GetRequest("hotel","36934");
/**
* 2 执行获取文档请求
*/
GetResponse response = client.get(request, RequestOptions.DEFAULT);
/**
* 3 解析获取响应结果
*/
String asString = response.getSourceAsString();
/**
* 4 将json字符串转为对象
*/
HotelDoc hotelDoc = JSON.parseObject(asString, HotelDoc.class);
System.out.println(hotelDoc);
}
20、删除文档
/**
* 删除文档
*/
@Test
public void deleteDocument() throws IOException {
DeleteRequest request=new DeleteRequest("hotel","36934");
DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);
System.out.println(delete.toString());
}
21、修改文档
/**
* 更新文档
* 1 全量修改与新增完全一致 判断条件是id
* 2 增量修改如下
*/
@Test
public void updateDocument() throws IOException {
UpdateRequest request=new UpdateRequest("hotel","36934");
request.doc(
"brand","7天酒店"
);
client.update(request,RequestOptions.DEFAULT);
}
22、批量导入es
/**
* 批量导入
*/
@Test
public void bulkDocument() throws IOException {
/**
* 查询所有mysql数据
*/
List<Hotel> list = iHotelService.list();
/**
* 构建批量请求-->执行批量请求
*/
BulkRequest request=new BulkRequest();
for (Hotel hotel : list) {
HotelDoc hotelDoc = new HotelDoc(hotel);
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
client.bulk(request,RequestOptions.DEFAULT);
}
总结:
文档操作的基本步骤:
初始化RestHighLevelClient
创建XxxRequest。XXX是Index、Get、Update、Delete、Bulk
准备参数(Index、Update、Bulk时需要)
发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
解析结果(Get时需要)
ElasticSearch-索引库、文档操作的更多相关文章
- Elasticsearch (1) - 索引库 文档 分词
创建索引库 ES的索引库是一个逻辑概念,它包括了分词列表及文档列表,同一个索引库中存储了相同类型的文档.它就相当于MySQL中的表,或相当于Mongodb中的集合. 关于索引这个语: 索引(名词):E ...
- java客户端的elasticSearch索引库的相关操作
package com.hope.es;import org.elasticsearch.client.transport.TransportClient;import org.elasticsear ...
- ElasticSearch 基本概念 and 索引操作 and 文档操作 and 批量操作 and 结构化查询 and 过滤查询
基本概念 索引: 类似于MySQL的表.索引的结构为全文搜索作准备,不存储原始的数据. 索引可以做分布式.每一个索引有一个或者多个分片 shard.每一个分片可以有多个副本 replica. 文档: ...
- ES入门三部曲:索引操作,映射操作,文档操作
ES入门三部曲:索引操作,映射操作,文档操作 一.索引操作 1.创建索引库 #语法 PUT /索引名称 { "settings": { "属性名": " ...
- ElasticSearch文档操作介绍三
ElasticSearch文档的操作 文档存储位置的计算公式: shard = hash(routing) % number_of_primary_shards 上面公式中,routing 是一个可变 ...
- 008-elasticsearch5.4.3【二】ES使用、ES客户端、索引操作【增加、删除】、文档操作【crud】
一.ES使用,以及客户端 1.pom引用 <dependency> <groupId>org.elasticsearch.client</groupId> < ...
- Elasticsearch (1) 文档操作
本文介绍如何在Elasticsearch中对文档进行操作. 1.检查Elasticsearch及Kibana运行是否正常 在浏览器输入192.168.6.16:9200,有如下输出则说明Elastic ...
- mongodb安装,库操作,集合操作(表),文档操作(记录)
安装 1.下载地址 https://fastdl.mongodb.org/win32/mongodb-win32-x86_64-2008plus-ssl-4.0.8-signed.msi 2.如果报没 ...
- elasticsearch查询篇索引映射文档数据准备
elasticsearch查询篇索引映射文档数据准备 我们后面要讲elasticsearch查询,先来准备下索引,映射以及文档: 我们先用Head插件建立索引film,然后建立映射 POST http ...
- Elastic Stack 笔记(四)Elasticsearch5.6 索引及文档管理
博客地址:http://www.moonxy.com 一.前言 在 Elasticsearch 中,对文档进行索引等操作时,既可以通过 RESTful 接口进行操作,也可以通过 Java 也可以通过 ...
随机推荐
- 什么是「滑动窗口算法」(sliding window algorithm),有哪些应用场景?
今天是算法数据结构专题的第2篇文章,我们一起来学习一下「滑动窗口算法」. 前言 最近刷到leetCode里面的一道算法题,里面有涉及到Sliding windowing算法,因此写一篇文章稍微总结一下 ...
- 汇编 | CPU物理地址本质理解
物理地址 我们知道,CPU访问内存单元时,要给出内存单元的地址.所有的内存单元构成的存储空间是一个一维的线性空间,每一个内存单元在这个空间中都有唯一的地址,我们将这个唯一的地址称为物理地址. CPU通 ...
- 2019年第十届蓝桥杯国赛C++B组
部分题目示意图来自网络,所以会带水印 最后编辑时间: 2021年5月12日 统一声明 如果不写默认带有常用头文件 如果不表明主函数默认表示在 void solve(){} 默认使用 using nam ...
- Codeforces 1312B Bogosort (逆序证明)
Example input 3 1 7 4 1 1 3 5 6 3 2 1 5 6 4 output 7 1 5 1 3 2 4 6 1 3 5 看题的时候发现和sort有关,但一定要逆序排序 证明: ...
- Vue第四篇 Vue路由系统
01-路由注册 <!DOCTYPE html> <html lang="en"> <head> <meta charset="U ...
- arthas 使用总结
本文为博主原创,未经允许不得转载: Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱.在线排查问题,无需重启:动态跟踪Java代码:实时监控JVM状态. Github: https ...
- Object.defineProperty()实现双向数据绑定
<div id="app"> <input type="text" name="txt" id="txt&quo ...
- grpc-环境与示例
1. 数据传输基本原理 2. grpc环境安装 代码生成器 go get -u github.com/golang/protobuf/protoc-gen-go // 会自动在 $GOPATH/bin ...
- [转帖]一篇来自网络的关于“enqueue”events的简短参考
https://www.cnblogs.com/lhdz_bj/p/8716701.html 仅供自己和各位同学参考: Enqueue Type Description enq: AD - alloc ...
- [转帖]Skip List--跳表(全网最详细的跳表文章没有之一)
https://www.jianshu.com/p/9d8296562806 跳表是一种神奇的数据结构,因为几乎所有版本的大学本科教材上都没有跳表这种数据结构,而且神书<算法导论>.< ...