分库分表后全局唯一ID的四种生成策略对比
分库分表之后,ID主键如何处理?
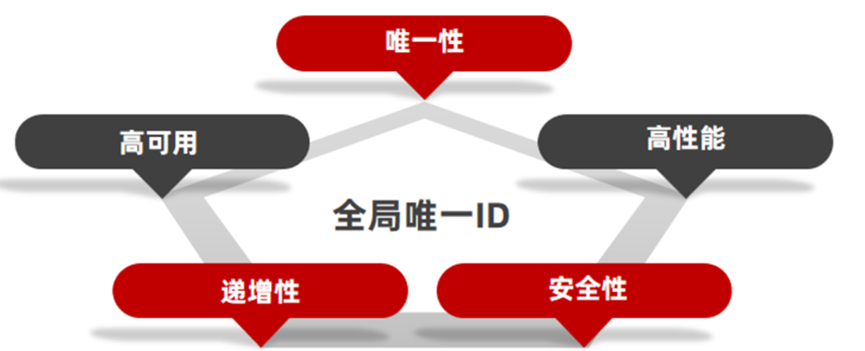
当业务量大的时候,数据库中数据量过大,就要进行分库分表了,那么分库分表之后,必然将面临一个问题,那就是ID怎么生成?因为要分成多个表之后,如果还是使用每个表的自增长ID,意味着每个表都是从1开始累加的,这样肯定是不对的。需要一个全局唯一的ID来支持。所以这也是你实际生产环境中必须考虑的一个问题。全局ID生成器,一般需要满足下列几个特性:
唯一性、高可用、递增性、安全性、高可用性
常用的主键ID生成策略有以下几种:
数据库自增ID
原理:
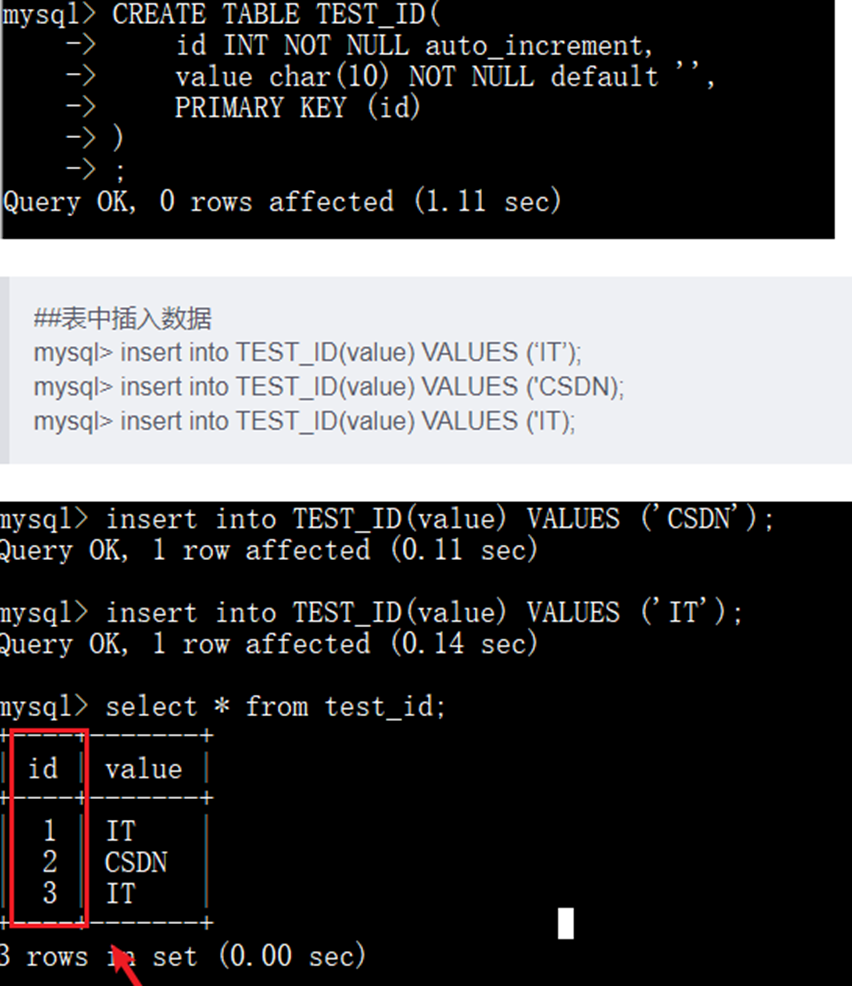
如果使用这种方式,那么这就意味着,你的系统里每次得到一个ID,都需要往一个库中的一个表中插入一条没有什么业务含义的数据,然后获取一个数据库自增的id.拿到这个ID之后,再往对应的分库分表里写。
这种方式的优缺点如下:
优点:非常简单,有序递增,方便分页和排序。
缺点:
a.分库分表之后,数据表的自增ID容易重复,无法直接使用(虽然可以设置步长,但是局限性明显);
b.性能吞吐量整个比较低。如果设计一个单独的数据库来实现分布式应用的数据唯一性,即使使用预先生成方案,也会因为事务问题,在高并发场景下容易出现单点的瓶颈问题。
使用场景:单数据库实例的表ID(包含主从同步场景);部分按天计数的流水号等
在分不分表场景、全局唯一性ID场景下不使用。
Redis生产全局ID
原理:
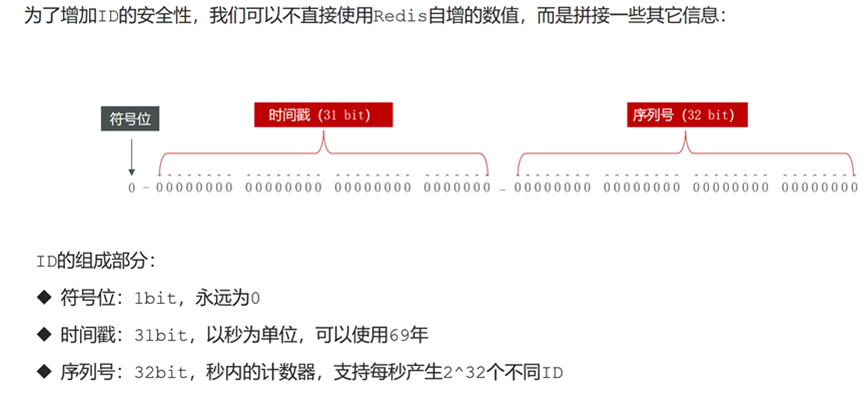
通过Redis的INCR/INCRBY自增原子操作命令,能保证生产的ID肯定是唯一的序列号,本质上实现方式与数据库一致的。
使用Redis生产全局ID的优缺点:
本文由凯哥Java(公众号:kaigejava),个人博客:www.kaigejava.com 发布于博客园.
凯哥自己开发的,领取外卖、打车、咖啡、买菜、各大电商的优惠券的公¥众¥号。如下图:
优点:整体吞吐量比数据库要高。因为Redis的吞吐量性能高于数据库
缺点:Redis实例或者集群宕机后,找回最新的ID值比较麻烦。但是可以在生产唯一ID的算法上进行优化,避免这种情况。
使用场景:比较适合计算场景。比如用户访问量、订单流水号(日期+流水号)等。
凯哥推荐文章:Redis实战9-全局唯一ID
UUID、GUID生成ID
优缺点:
优点:性能非常高。在本地生成,没有网络消耗;
缺点:UUID太长了,占用空间大,作为主键性能太差了;
由于UUI不具有有序性,会导致B+树索引在写的时候有过多的随机写操作。
使用场景:如果你要随机生成一个什么文件名称、编号之类的,可以考虑使用UUID,但是如果是作为数据库的主键,不建议使用UUID的。
雪花算法(snowflake)
雪花算法来源于Twitter,使用Scala语言实现,雪花算法的特性是有序、唯一且要求性能高,低延迟(每台集群每秒至少生成10K条数据,并且响应时间在2MS内),要在分布式环境(多集群、跨机房)下使用。因此雪花算法得到的ID是分段组成的。
a.与指定日期时间差(时间差到毫秒级)的,41位数字,可以使用69年;
b.机器ID+集群ID,10位,最多支持1024台机器;
c.序列号,12位。每台机器每毫秒内最多生产4096个序列号.
雪花算法的核心思想是:
分布式ID固定是一个long类型的数字,一个long类型占用8个字节,也就是8*8=64个bit位。所以,雪花算法的格式如下图:

雪花算法分段,每段含义:
第一段:也就是最高1位是符号位。固定值,就是0,标识全部ID都是正整数。
第二段:接下来的41位,标识的是时间戳。单位是毫秒。41bits标识的数字对应的是2^41次方-1.也就是可以标识2的41次方-1个毫秒值。换算成年就是标识69年的时间;
第三段:再接下来的10位标识的是机器ID。如果有异地部署,多集群的也可以配置,需要在线下提前规划好各地机房,各个集群,实例ID的编号。其中包括5位的机器id和5位的集群id.最多可以部署2^10台机器。也就是1024台。
第四段:最后12位是序列号。用于记录同一毫秒内产生的不同ID.12个比特位可以代表的最大正整数是2^12-1=4096.也就是说,可以用这12个bits代表数字来区分同一毫秒内4096个不同的ID.
此算法的优缺点如下:
雪花算法的优缺点:
优点:毫秒数在高位,自增序列在低位,所以整个ID都呈现出递增趋势;
不依赖数据库等三方系统,以服务部署方式,稳定性更高,生成ID的性能也是非常高的;
可以根据自身业务特性来分配bit位,非常灵活。
缺点:
太依赖集群的时钟,如果机器时钟回拨了,可能会导致重复或者服务处于不可用。
结束语
大家好,我是凯哥Java(kaigejava),乐于分享技术文章,欢迎大家关注“凯哥Java”,及时了解更多。让我们一起学Java。也欢迎大家有事没事就来和凯哥聊聊~~~
分库分表后全局唯一ID的四种生成策略对比的更多相关文章
- 分库分表后跨分片查询与Elastic Search
携程酒店订单Elastic Search实战:http://www.lvesu.com/blog/main/cms-610.html 为什么分库分表后不建议跨分片查询:https://www.jian ...
- 分库分表之后全局id怎么生成
数据库自增id: 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案的好 ...
- 分库分表之后全局id咋生成?
1.面试题 分库分表之后,id主键如何处理? 2.面试官心里分析 其实这是分库分表之后你必然要面对的一个问题,就是id咋生成?因为要是分成多个表之后,每个表都是从1开始累加,那肯定不对啊,需要一个全局 ...
- 分库分表数据库自增 id
分库分表之后,ID 主键如何处理? 面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 ...
- 为什么MySQL分库分表后总存储大小变大了?
1.背景 在完成一个分表项目后,发现分表的数据迁移后,新库所需的存储容量远大于原本两张表的大小.在做了一番查询了解后,完成了优化. 回过头来,需要进一步了解下为什么会出现这样的情况. 与标题的问题的类 ...
- 游戏服务器生成全局唯一ID的几种方法
在服务器系统开发时,为了适应数据大并发的请求,我们往往需要对数据进行异步存储,特别是在做分布式系统时,这个时候就不能等待插入数据库返回了取自动id了,而是需要在插入数据库之前生成一个全局的唯一id,使 ...
- 分布式唯一ID的几种生成方案
前言 在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID.退款ID等.那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十 ...
- mysql分库分表那些事
为什么使用分库分表? 如下内容,引用自 Sharding Sphere 的文档,写的很大气. <ShardingSphere > 概念 & 功能 > 数据分片> 传统的 ...
- 001---mysql分库分表
mysql分库分表 一.整体的切分方式 1.分库分表:即数据的切分就是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)中,以达到分散单台设备负载的效果 2.数据的切分根 ...
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一.前言 在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个: 1. 分布式全局唯一id 2. 分片规则和策略 3. 跨分片技术问题 4. 跨分片事物 ...
随机推荐
- HTTP事务理解
借图: 首先三次握手理解: TCP三次握手好比两个对话, 第一次握手:甲给乙一直发送信息,乙没有回应,甲不知道乙有没有收到信息 第二次握手:乙收到信息,然后再给甲回信息,此时甲知道乙收到信息,但乙不知 ...
- python跟踪脚本运行过程(类似bash shell -x)
#详细追踪 python -m trace --trace pyscript.py #显示调用了哪些函数 python -m trace --trackcalls pyscript.py
- Linux自己制作rpm包
制作rpm包 由源码包---->rpm包 安装制作rpm包工具包rpm-build 在制作过程中需要源码包和配置文件 rpmbuild制作rpm包的原理: 1.首先rpmbuild会先将源码包进 ...
- django 计算两个TimeField的时差
在 Django 中,你可以使用 datetime 模块来计算两个 TimeField 字段的时间差.以下是一个示例: from datetime import datetime, timedelta ...
- Day 1 - 二分
整数二分 我们可以做到每次排除一半的答案,时间复杂度 \(O(\log n)\). long long l = L, r = R; while(l <= r) { long long mid = ...
- CF858C 题解
洛谷链接&CF 链接 本篇题解为此题较简单做法及较少码量,并且码风优良,请放心阅读. 题目简述 给你一个均为小写字母的字符串,如果它的子串同时满足: 三个连着的辅音字母. 这一段连着的辅音字母 ...
- [UE源码] 关于使用UE待改进的一些尝试
UE从自己做了一款游戏后,发现了蓝图以及UE引擎本身的一些优缺点: 1.蓝图在一些简单的逻辑上书写方便,直观,而且编译速度快,但是也有一些其他问题: 结构体赋值后,无法二次修改 只有3种容器Array ...
- C# 通过反射(Reflection)调用不同名泛型方法
概述 由于工作需要,需要通过数据类型和方法名控制方法走向 用到的数据类型有8种(string,Int16,Int32,Int64,Boolean,Byte,Single,Double) 读取的方法(参 ...
- 【Scala】09 偏函数 PartialFunction
更像是策略函数 可拆分成一个部分,是若干个函数的组合 package cn object HelloScala { def main(args: Array[String]): Unit = { // ...
- 【SpringBoot】04 初探YAML与配置
什么是YAML? https://www.cnblogs.com/mindzone/p/12849789.html 复合结构的语法 一个标配JavaBean public class Person { ...