并查集(UnionFind)
并查集和其他树形结构不一样,是由孩子指向父亲,它解决了一些连接问题,怎么才能确定两个点是否相连呢?并查集可以非常快的确定两个点是否连接。

如何确定连个点是否连接呢?

我们可以用一个数组表示,对于0到9每个不同的编号可以表示不同的对象,这里可以看作一个点,而编号对应的不同的元素可以表示不同的集合,其中[0,2,4,6,8]表示一个集合。这样就可以表示连接问题了,0和2就是表示相连接,因为它们在一个集合,0和1因不在一个集合所以不连接。
对于一组数据并查集主要支持两个动作:
- isConnected(p,q):查询元素p和q是否在一个集合
- unionElements(p,q):合并元素p和q的集合
Code
#pragma once
class UF {
private:
virtual const int getSize() const noexcept = 0;
virtual bool isConnected(int p, int q) = 0;
virtual void unionElements(int p, int q) = 0;
};
#pragma once
#include "UF.h"
#include<cassert>
class UnionFind1 : public UF {
private:
int *id;
int size;
public:
UnionFind1(int capacity) {
id = new int[capacity];
size = capacity;
for (int i = 0; i < size; ++i) {
id[i] = i; //初始化不同的元素表示不同的集合都不相连
}
}
const int getSize() const noexcept {
return size;
}
//返回p所在的集合
int find(int p) {
assert(p >= 0 && p < size);
return id[p];
}
//判断是否相连
bool isConnected(int p, int q) {
return find(p) == find(q);
}
//合并集合
void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID) {
return;
}
for (int i = 0; i < size; ++i) {
if (id[i] == pID) {
id[i] = qID; //让两个集合都相同就行了
}
}
}
};
优化unionElements
从代码中可以看到:
- unionElements的时间复杂度是O(n)
- isConnected的时间复杂度是O(1)
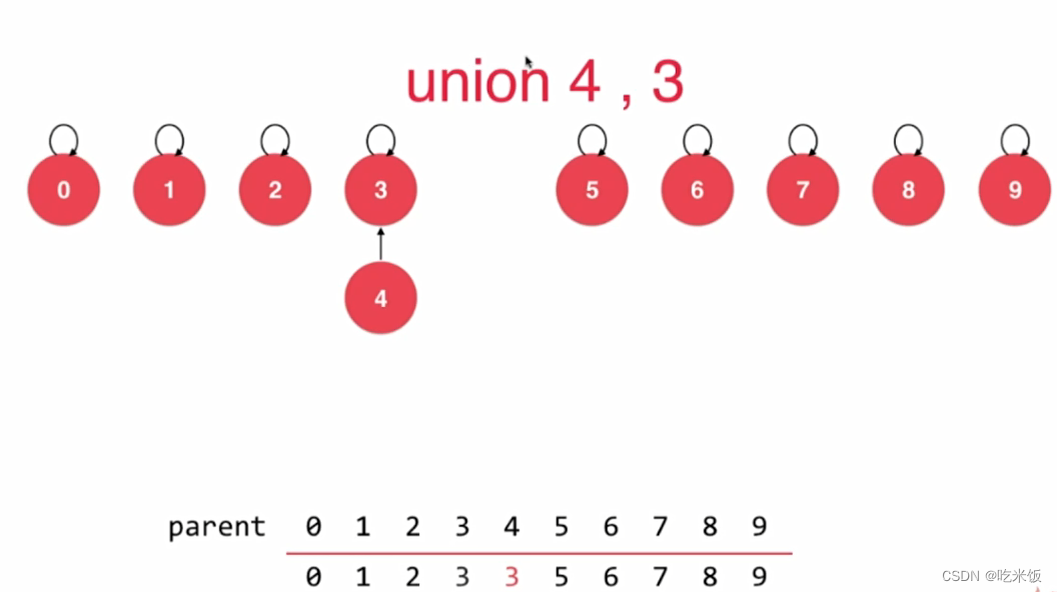
将每个元素,看做是一个节点,每个节点指向它的父节点,而根节点指向自己。如果我们进行unionElements(4,3)操作,那么就是让4索引的元素为3。同在一个树下面就是同一个集合表示相连。
Code
#pragma once
#include "UF.h"
#include<cassert>
class UnionFind2 : public UF {
private:
int *parent;
int size;
public:
UnionFind2(int capacity) {
parent = new int[capacity];
size = capacity;
for (int i = 0; i < size; ++i) {
parent[i] = i;
}
}
const int getSize() const noexcept {
return size;
}
int find(int p) {
assert(p >= 0 && p < size);
while (p != parent[p]) {
p = parent[p];
}
return p;
}
bool isConnected(int p, int q) {
return find(p) == find(q);
}
void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
parent[pRoot] = qRoot;
}
};
基于size的优化
由于对真正合并那两个元素所在树的形状没有做判断,很多时候会增加树的高度。
优化方法:节点个数小的那个节点去指向节点个数多个那个根节点。
Code
#ifndef UNION_FIND_UNIONFIND3_H
#define UNION_FIND_UNIONFIND3_H
#include "UF.h"
#include <cassert>
class UnionFind3 : public UF {
private:
int *parent;
int *sz;
int size;
public:
UnionFind3(int capacity) {
parent = new int[capacity];
sz = new int[capacity];
size = capacity;
for (int i = 0; i < size; ++i) {
parent[i] = i;
sz[i] = 1;
}
}
int getSize() {
return size;
}
int find(int p) {
assert(p >= 0 && p < size);
while (p != parent[p]) {
p = parent[p];
}
return p;
}
bool isConnected(int p, int q) {
return find(p) == find(q);
}
void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
if (sz[pRoot] < sz[qRoot]) {
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
} else {
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
};
#endif //UNION_FIND_UNIONFIND3_H
基于rank的和优化
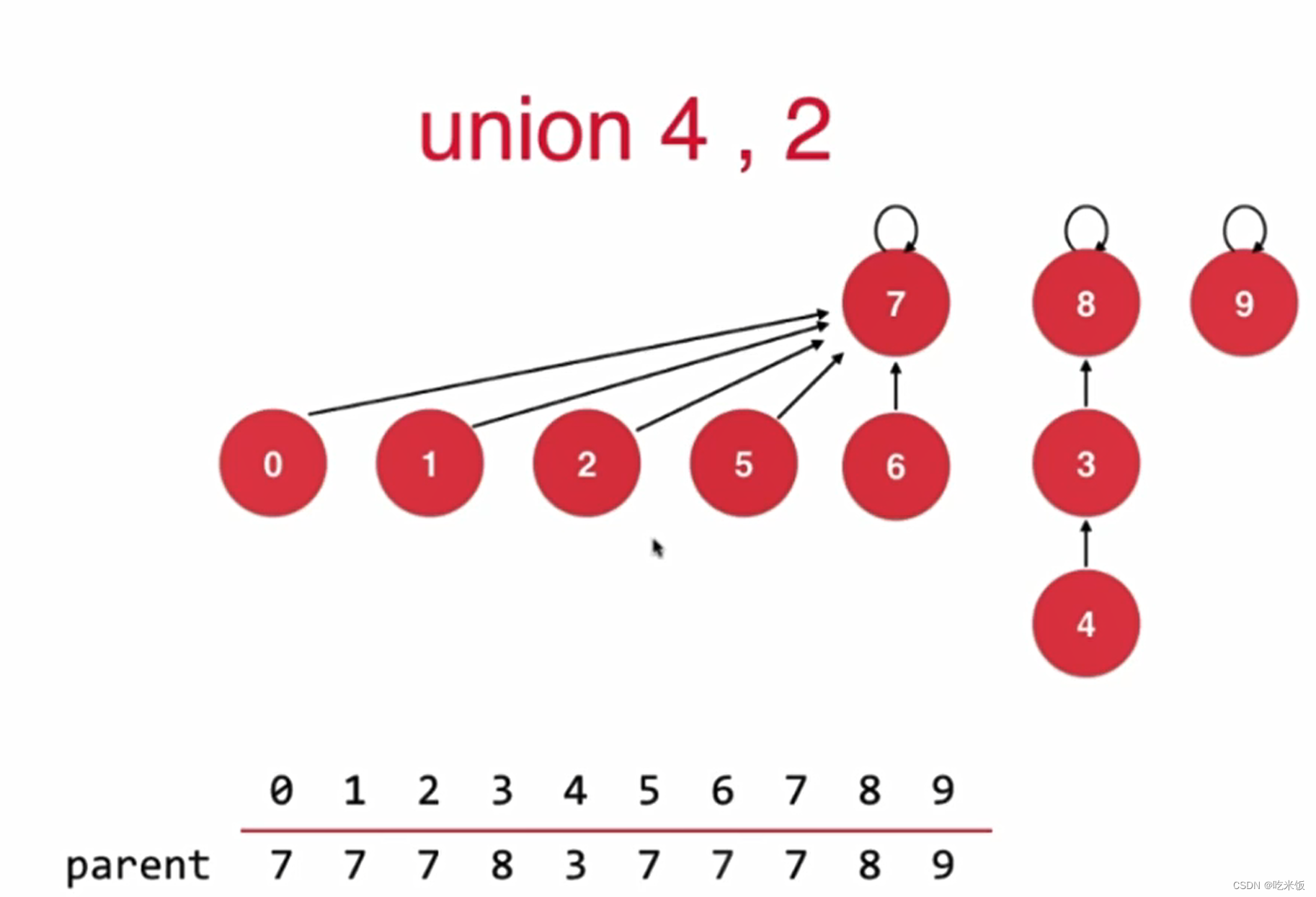
如果基于size优化会增加树的高度
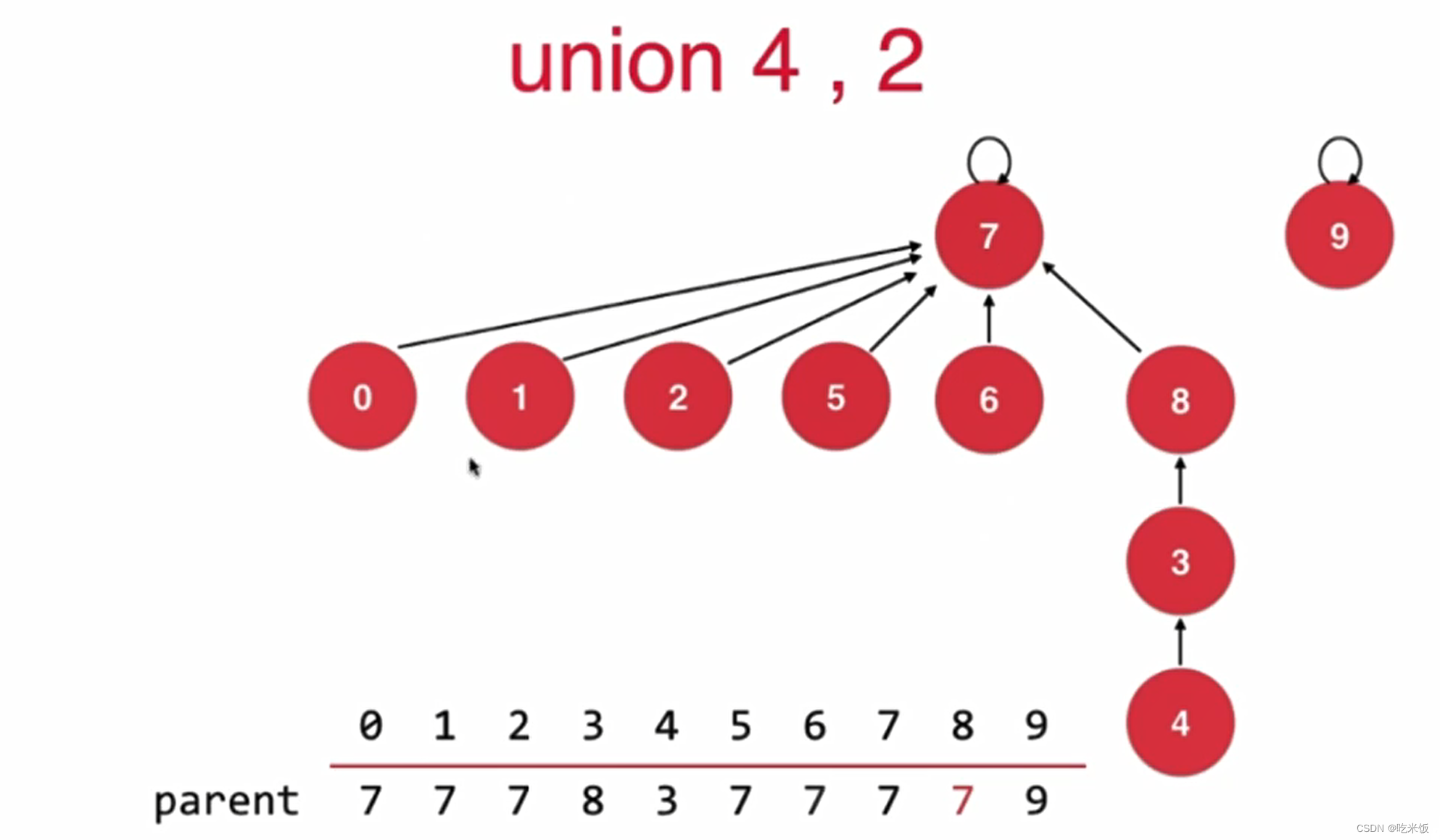
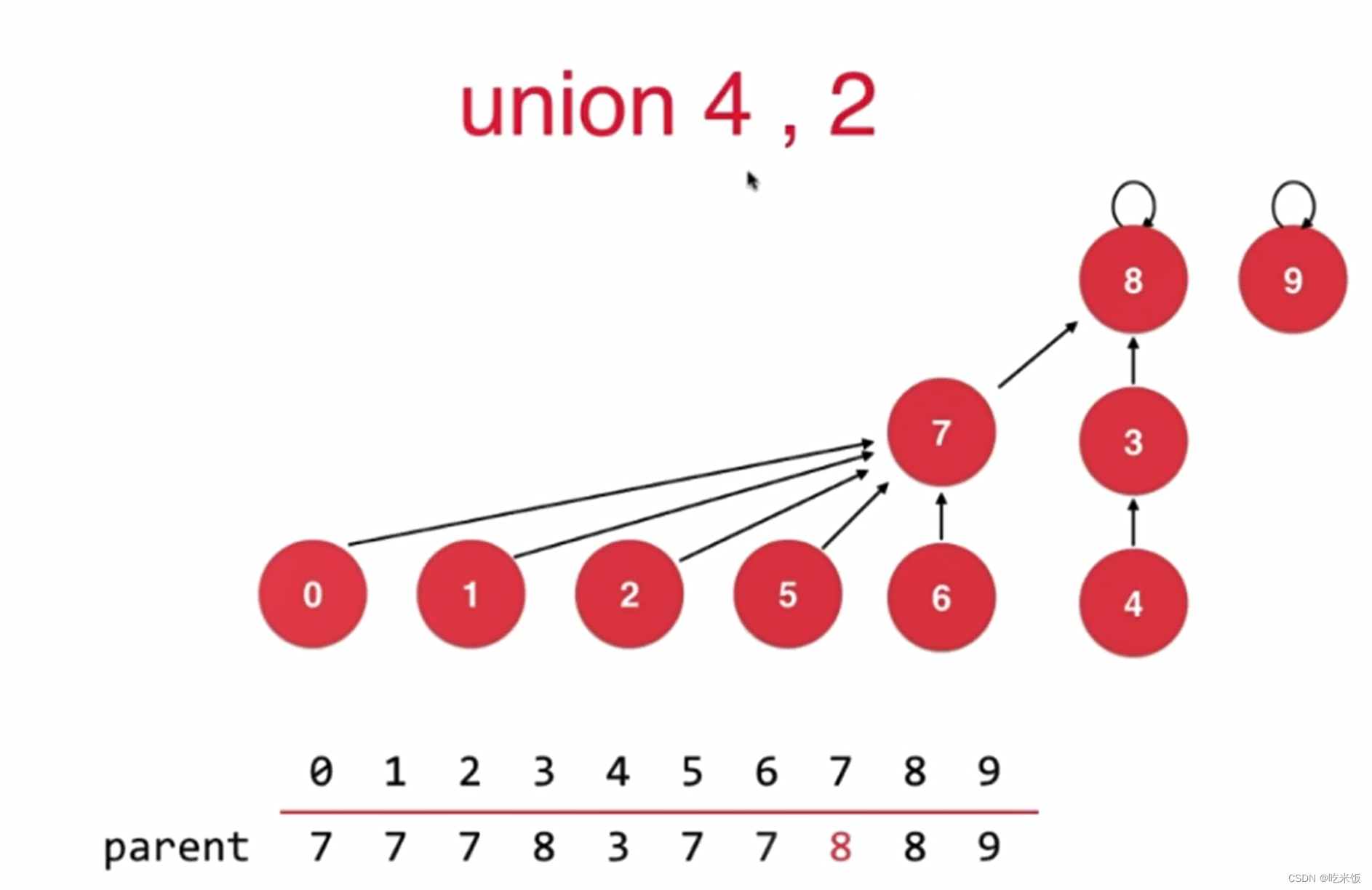
如果基于rank的优化rank[i]表示根节点为i的树的高度
Code
#ifndef UNION_FIND_UNIONFIND4_H
#define UNION_FIND_UNIONFIND4_H
#include "UF.h"
#include <cassert>
class UnionFind4 : public UF {
private:
int *parent;
int *rank;
int size;
public:
UnionFind4(int capacity) {
parent = new int[capacity];
rank = new int[capacity];
size = capacity;
for (int i = 0; i < size; ++i) {
parent[i] = i;
rank[i] = 1;
}
}
int getSize() {
return size;
}
int find(int p) {
assert(p >= 0 && p < size);
while (p != parent[p]) {
p = parent[p];
}
return p;
}
bool isConnected(int p, int q) {
return find(p) == find(q);
}
void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]) {
parent[qRoot] = pRoot;
} else {
parent[qRoot] = pRoot;
rank[pRoot] += 1;
}
}
};
#endif //UNION_FIND_UNIONFIND4_H
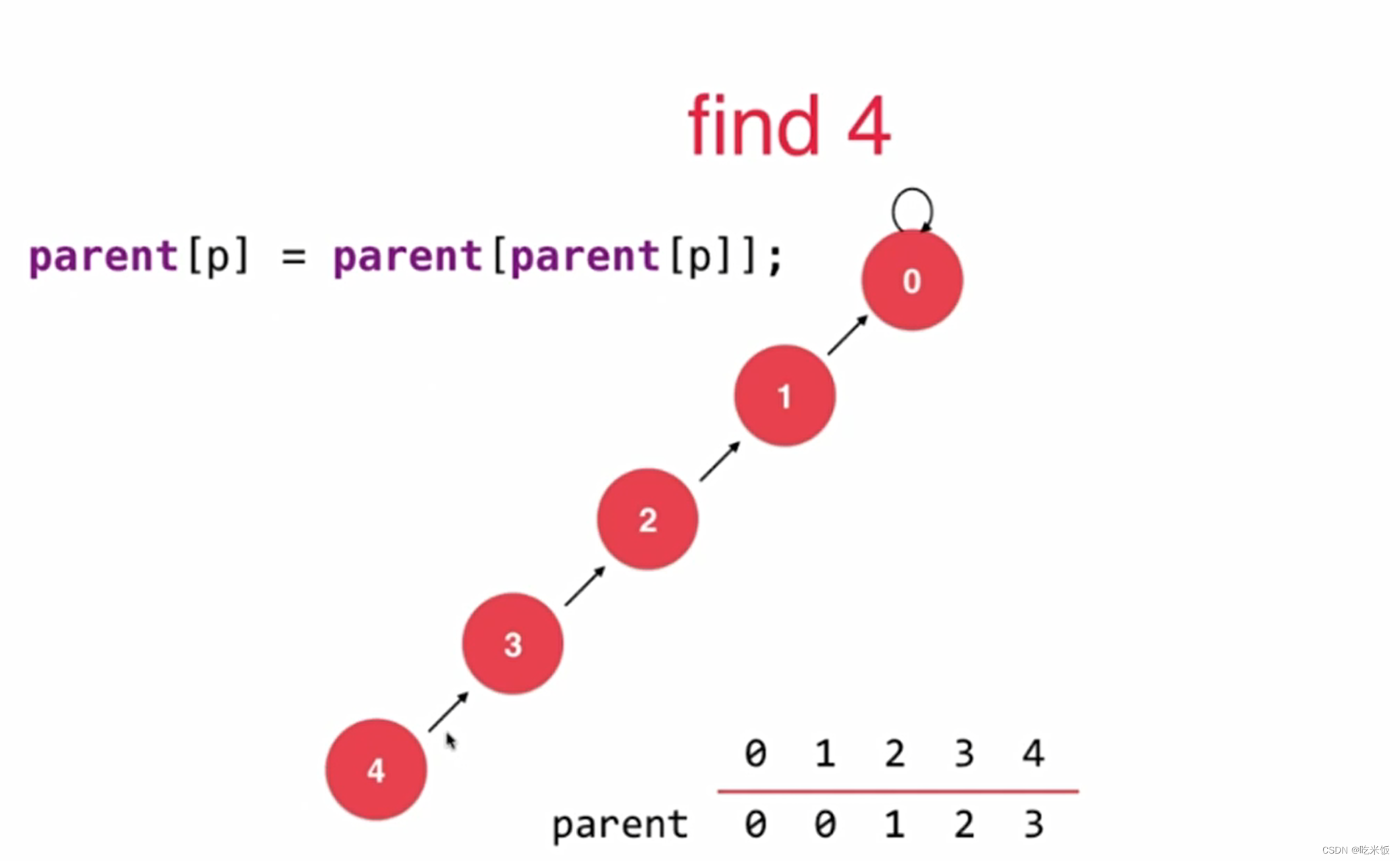
路径压缩
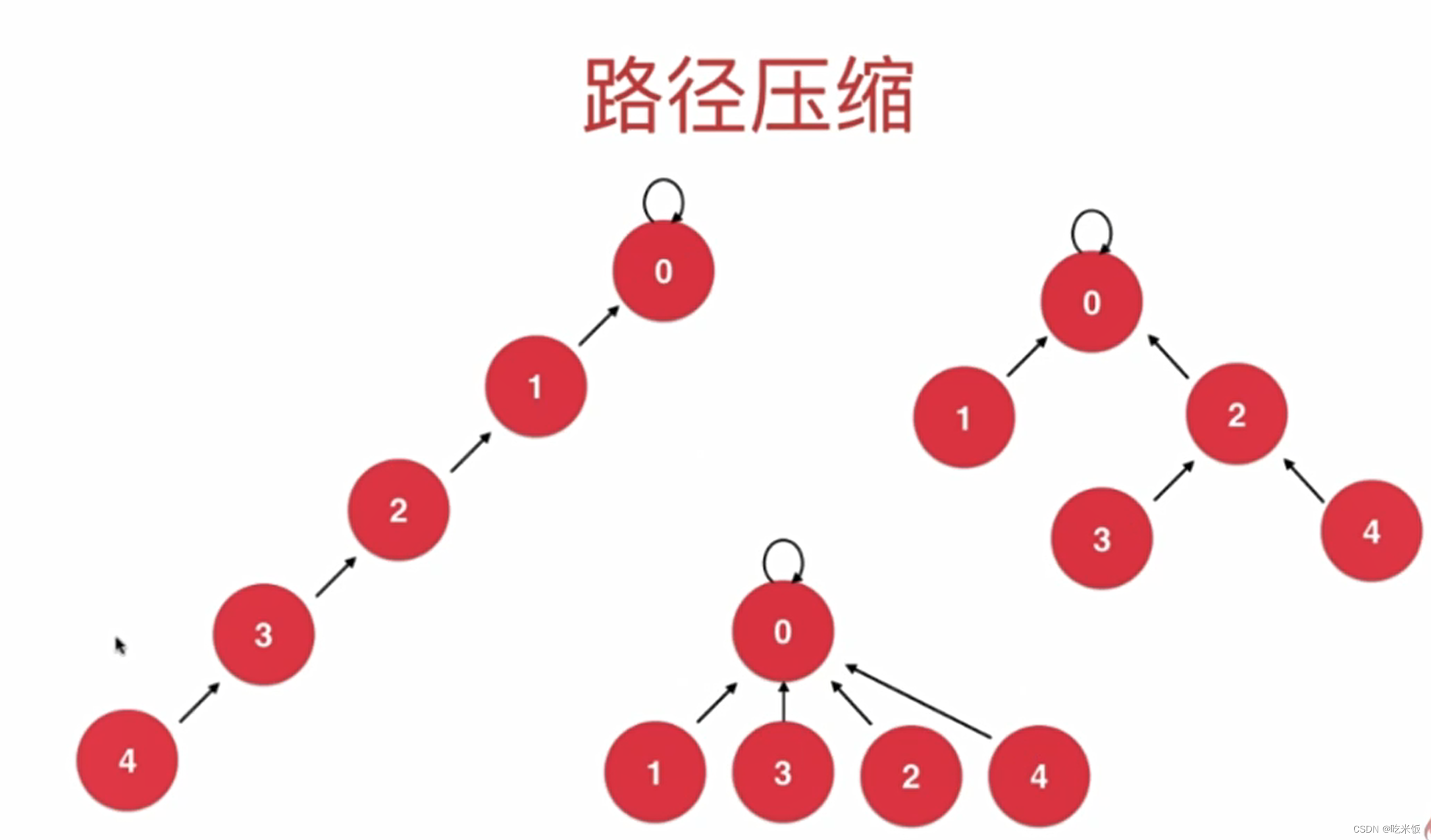
优化方法一
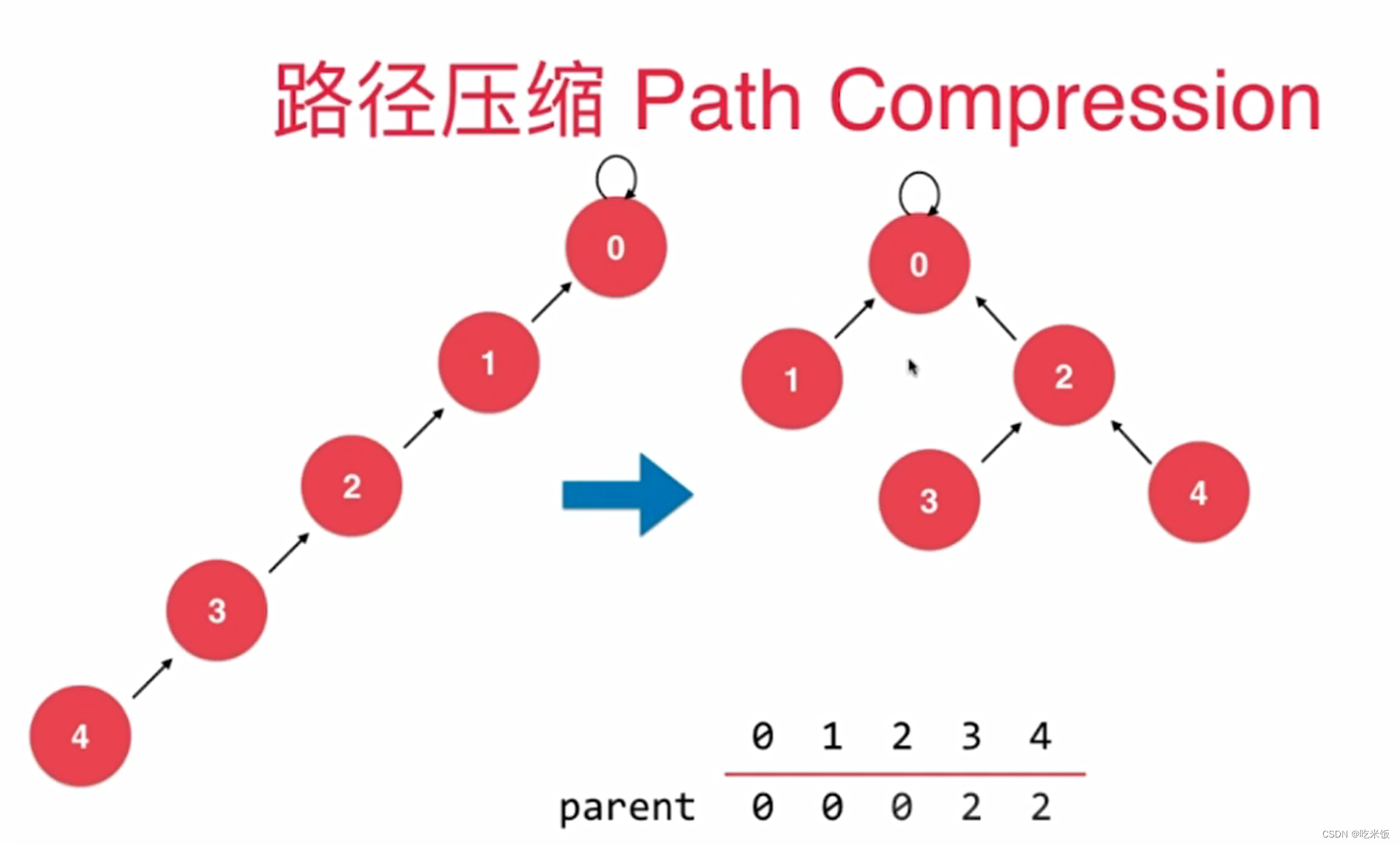
优化方法二
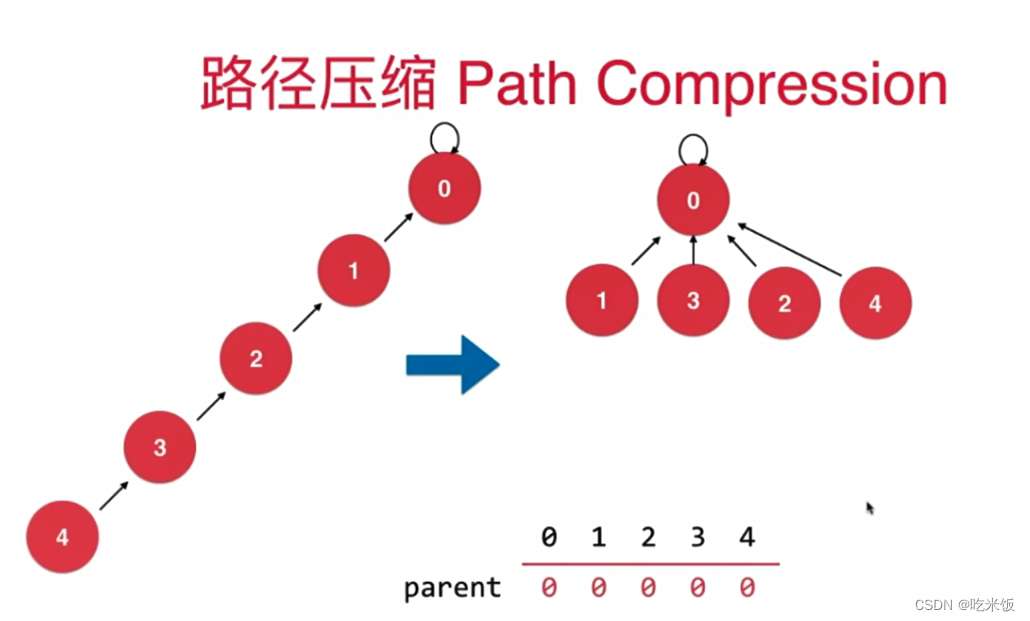
Code
#pragma once
#include "UF.h"
#include<cassert>
class UnionFind : public UF {
public:
UnionFind(int cap) : size(cap) {
parent = new int[size];
rank = new int[size];
for (int i = 0; i < size; ++i) {
parent[i] = i;
rank[i] = 1;
}
}
~UnionFind() noexcept {
delete[] parent;
parent = nullptr;
}
const int getSize() const noexcept override {
return size;
}
//查询元素p和q是否在一个集合
bool isConnected(int p, int q) override {
return find(p) == find(q);
}
//合并元素p和q的集合
void unionElements(int p, int q) override {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
//就把其中一个的根节点挂到另一个的根上
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot; //高度小的根节点指向高度大的根节点,从而减少树的高度,防止退化
} else if (rank[qRoot] < rank[pRoot]) {
parent[qRoot] = pRoot;
} else {
parent[qRoot] = pRoot;
++rank[pRoot];
}
}
private:
//查找元素p对应的集合编号,O(h)复杂度, h为树的高度
//根节点就是集合编号,且根节点指向自己,索引 p == parent[p]
int find(int p) {
assert(p >= 0 && p < size);
while (p != parent[p]) {
parent[p] = parent[parent[p]]; //路径压缩,让p这个节点指向它父亲的父亲
p = parent[p];
}
return p;
}
//递归版路径压缩,让集合中所有节点指向根节点
int recFind(int p) {
assert(p >= 0 && p < size);
if (p != parent[p]) {
parent[p] = find(parent[p]);
}
return parent[p];
}
private:
int *parent;
int *rank;
int size;
};
并查集(UnionFind)的更多相关文章
- 并查集(union-find)算法
动态连通性 . 假设程序读入一个整数对p q,如果所有已知的所有整数对都不能说明p和q是相连的,那么将这一整数对写到输出中,如果已知的数据可以说明p和q是相连的,那么程序忽略p q继续读入下一整数对. ...
- 并查集 Union-Find
并查集能做什么? 1.连接两个对象; 2.查询两个对象是否在一个集合中,或者说两个对象是否是连接在一起的. 并查集有什么应用? 1. Percolation问题. 2. 无向图连通子图个数 3. 最近 ...
- 并查集(Union-Find)算法介绍
原文链接:http://blog.csdn.net/dm_vincent/article/details/7655764 本文主要介绍解决动态连通性一类问题的一种算法,使用到了一种叫做并查集的数据结构 ...
- 数据结构之并查集Union-Find Sets
1. 概述 并查集(Disjoint set或者Union-find set)是一种树型的数据结构,常用于处理一些不相交集合(Disjoint Sets)的合并及查询问题. 2. 基本操作 并查集 ...
- 并查集 (Union-Find Sets)及其应用
定义 并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题.常常在使用中以森林来表示. 集就是让每个元素构成一个单元素的集合,也就是按一定顺序将属于同一组的 ...
- 【LeetCode】并查集 union-find(共16题)
链接:https://leetcode.com/tag/union-find/ [128]Longest Consecutive Sequence (2018年11月22日,开始解决hard题) 给 ...
- 数据结构《14》----并查集 Union-Find
描述: 并查集是一种描述解决等价关系.能够方便地描述不相交的多个集合. 支持如下操作 1. 建立包含元素 x 的集合 MakeSet(x) 2. 查找给定元素所在的集合 Find(x), 返回 ...
- 并查集(union-find set)与Kruskal算法
并查集 并查集处理的是集合之间的关系,即‘union' , 'find' .在这种数据类型中,N个不同元素被分成若干个组,每组是一个集合,这种集合叫做分离集合.并查集支持查找一个元素所属的集合和两个元 ...
- 并查集(Union-Find) 应用举例 --- 基础篇
本文是作为上一篇文章 <并查集算法原理和改进> 的后续,焦点主要集中在一些并查集的应用上.材料主要是取自POJ,HDOJ上的一些算法练习题. 首先还是回顾和总结一下关于并查集的几个关键点: ...
- 并查集(union-find sets)
一.并查集及其优化 - 并查集:由若干不相交集合组成,是一种简单但是很好用的数据结构,拥有优越的时空复杂性,一般用于处理一些不相交集合的查询和合并问题. - 三种操作: 1.Make_Set(x) 初 ...
随机推荐
- 《系列一》-- 2、XmlBeanFactory 的类图介绍.md
阅读之前要注意的东西:本文就是主打流水账式的源码阅读,主导的是一个参考,主要内容需要看官自己去源码中验证.全系列文章基于 spring 源码 5.x 版本. Spring源码阅读系列--全局目录.md ...
- .gitignore 无法工作
在开发一个新项目时,发现每次编译时都会产生一些 .obj 无用的文件,这些文件并不需要 push 到 github 上 故使用 .gitignore 忽略这些文件 首先,我们可以设置这些文件的输出目录 ...
- 以二进制文件安装K8S之环境准备
为了k8s集群能正常运行,需要先完成4项准备工作: 1.关闭防火墙 2.禁用SeLinux 3.关闭Swap 4.安装Docker 关闭防火墙 # 查看防火墙状态 getenforce #关闭防火墙, ...
- vue upload 图片转base64、转二进制数组,保存编码数据到文件
功能需求 1.图片转base64 2.base 64 转二进制数组 3.保存二进制数据到文件下载到本地 解决方法 问题1: 参考资料 vue element upload图片 转换成base64 具体 ...
- 【LeetCode剑指offer#06】实现pow函数、计算x的平方根
实现pow函数 实现 pow(x, n) ,即计算 x 的整数 n 次幂函数(即,xn ). 示例 1: 输入:x = 2.00000, n = 10 输出:1024.00000 示例 2: 输入:x ...
- 详解SSL证书系列(3)如何选择SSL证书
我们知道了在网站部署 SSL 证书后,不管是对网站本身还是对网站的用户都能够带来许多好处.那么随着 HTTPS的普及,市面上也出现了各种不同的 SSL 证书.并且由于 SSL 证书的多样性,很多人对于 ...
- 【Azure Function App】在ADF(Azure Data Factory)中调用 Azure Function 时候遇见 Failed to get MI access token
问题描述 在ADF(Azure Data Factory)中,调用Azure Function App中的Function,遇见了 Failed to get MI access token Ther ...
- 【Azure Redis 缓存】Azure Cache for Redis 专用终结点, 虚拟网络, 公网访问链路
问题描述 为优化Redis访问链路,对下面三种方案进行对比: 1.Redis添加到虚拟网络 2.Redis添加专用终结点 3.Redis默认公共链路 问题分析 第三种:Redis默认公共链路,顾名思义 ...
- RocketMQ(11) 消息重试机制和死信队列
七.消息发送重试机制 1 说明 Producer对发送失败的消息进行重新发送的机制,称为消息发送重试机制,也称为消息重投机制. 对于消息重投,需要注意以下几点: 生产者在发送消息时,若采用同步或异步发 ...
- 关于Java并发多线程的一点思考
写在开头 在过去的2023年双11活动中,天猫的累计访问人次达到了8亿,京东超60个品牌销售破10亿,直播观看人数3.0亿人次,订单支付频率1分钟之内可达百万级峰值,这样的瞬间高并发活动,给服务端带来 ...