AI论文解读:基于Transformer的多目标跟踪方法TrackFormer
摘要:多目标跟踪这个具有挑战性的任务需要同时完成跟踪目标的初始化、定位并构建时空上的跟踪轨迹。本文将这个任务构建为一个帧到帧的集合预测问题,并提出了一个基于transformer的端到端的多目标跟踪方法TrackFormer。
本文分享自华为云社区《论文解读系列十四:基于transformer的多目标跟踪方法TrackFormer详细解读》,原文作者:谷雨润一麦 。

多目标跟踪这个具有挑战性的任务需要同时完成跟踪目标的初始化、定位并构建时空上的跟踪轨迹。本文将这个任务构建为一个帧到帧的集合预测问题,并提出了一个基于transformer的端到端的多目标跟踪方法TrackFormer。本文模型通过注意力机制实现了帧与帧之间的数据关联,完成了视频序列间的跟踪轨迹的预测。Transformer的解码器同时从静态的目标查询中初始化新的目标和从跟踪查询中跟踪已有的跟踪轨迹并对位置进行更新,两种类型的查询都可以同时从self-attention和encoder-decoder的注意力中关注到全局的帧级特征。因此可以省略掉额外的图优化和匹配的过程,也不需要对运动和外貌特征进行建模。
1. Motivation
多目标跟踪任务需要跟踪一系列目标的轨迹,当目标在视频序列中移动时可以保持各自具有区分性的跟踪id。现有的tracking-by-detection的方法一般都包含两个步骤(1)检测单独视频帧中目标(2)对帧与帧之间的检测目标进行关联,从而形成每个目标的跟踪轨迹。传统的基于tracking-by-detection的方法的数据关联一般都需要图优化或者利用卷积神经网络预测目标间的分数的方式。本文提出了一个新的跟踪范式tracking-by-attention,该方法将多目标跟踪任务建模为一个集合预测问题,通过提出的TrackFormer网络实现了端到端的可训练的在线多目标跟踪网络。该网络利用encoder对来自卷积网络的图像特征进行编码,然后通过decoder将查询向量解码为包围框和对应的身份id,其中的跟踪查询用来做帧与帧之间的数据关联。
2. 网络结构
本文提出的TrackFormer是一个基于transformer的端到端多目标跟踪方法,它将多目标跟踪任务建模为一个集合预测问题,并引出了tracking-by-attention这种新的范式。下面将从整体流程、跟踪过程和网络损失函数三个方面分别对网络进行介绍。
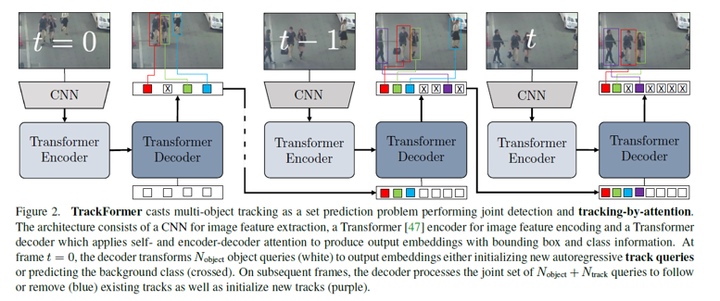
图一 trackformer训练流程图
2.1 基于集合预测的多目标任务
给定具有K个不同identity的目标的视频序列,多目标跟踪任务需要生成包括包围框和身份id(k)的跟踪轨迹
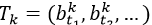
总帧数T 的子集(t1,t2,…)记录了目标从进入到离开场景的时间序列。
为了将MOT(多目标跟踪任务)建模为序列预测问题,本文利用了transformer的编码器-解码器结构。文本模型通过下面四个步骤完成在线的跟踪并同时输出每一帧目标的边界框、类别以及身份id:
1)通过通用的卷积神经网络backbone提取帧级的特征,例如ResNet
2)通过transformer的编码器的self-attention模块完成帧级特征编码
3)通过transformer的解码器的self-和cross-attention完成对查询实体的解码
4)通过多层感知机对解码器输出进行映射完成边界框和类别的预测
其中解码器的注意力机制一共分为两种(1)所有查询向量上的self-attention,可以用来响应场景中的所有目标;(2)编码器和解码器之间的注意力,可以获取到当前帧的全局视觉信息。另外,因为transformer具有排列不变性,需要分别给特征输入和解码查询实体添加额外的位置编码和目标编码。
2.2 基于解码器查询向量的跟踪过程
Transformer的解码器查询向量一共有两种初始化方式(1)静态目标查询向量,帮助模型在任意帧初始化跟踪目标(2)自回归跟踪查询向量,负责在帧与帧之间跟踪目标。Transformer同时对目标和跟踪查询进行解码可以以一种统一方式的实现检测和跟踪,因此引入了一种tracking-by-attention的模式。详细的网络结构如下图所示:
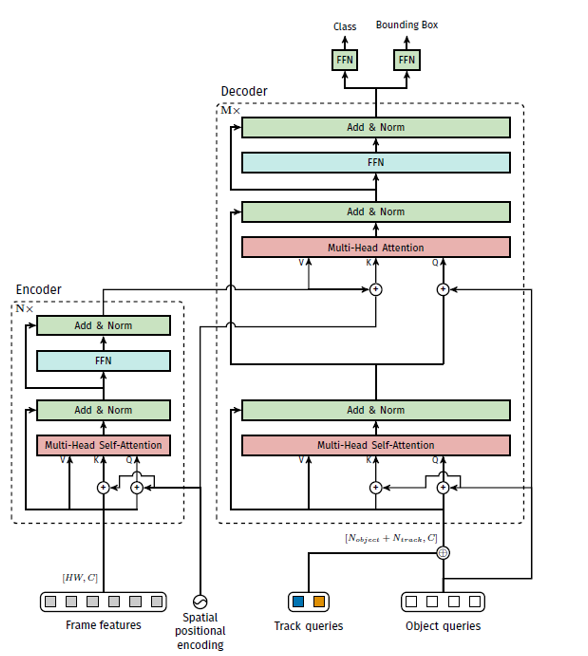
图二 trackformer网络结构
2.2.1 跟踪初始化
场景中新出现的目标都是通过固定数量(Nobject)的目标查询向量进行检测的,这Nobject个目标向量在网络训练过程中会不断学习从而可以实现场景中的所有目标编码,然后通过transformer的解码器的解码完成新目标类别和位置信息的预测,从而实现了跟踪的初始化。
2.2.2跟踪查询
为了实现帧与帧之间的跟踪,本文在解码过程中提出了“跟踪查询”这个概念。跟踪查询会在视频序列中不断跟踪目标,在携带者身份信息的同时还通过自回归的方式自适应的调整目标的位置预测。为了实现这个目标,在解码过程中会用上一帧对应的输出embedding来初始化检测的跟踪查询向量,然后在解码过程中通过encoder和decoder建立当前帧和查询向量之间注意力关系,从而完成了跟踪查询中各个实例的身份和位置的更新。
跟踪查询向量如图一中的颜色方块所示,上一帧的transformer输出embedding会被用来初始化当前帧的查询向量,通过和当前帧特征进行查询,完整帧与帧之间的目标跟踪。
2.3 网络训练及损失函数
因为查询跟踪需要跟踪下一帧的目标并和目标查询交互一起工作,TrackFormer需要专门的帧与帧之间的跟踪训练。如图一所示,本文通过同时训练紧邻的两帧来完成跟踪训练,并一起优化所有的多目标跟踪目标函数。集合预测损失度量了每一帧的所有输出
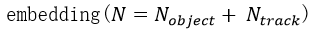
的类别和边界框预测与真实目标之间的相似性,集合预测损失一共可以分为两部分计算:
1)上一帧(t-1)的 Nobject 个目标查询的loss
2)从上一步得到得到的跟踪目标和当前帧(t)的新的检测目标总共N个查询的loss
因为transformer的输出是无序的,因此在计算集合预测损失之前需要先完成输出embedding和真实标签之间的匹配问题。这个匹配可以同时通过跟踪id和包围框以及类别之间的相似性来完成,首先考虑跟踪id的情况,我们用 Kt-1 表示t-1帧的跟踪id集合,用 Kt 表示当前帧t的跟踪id集合,通过这两个跟踪集合可以完成Ntrack跟踪查询和真实标签的硬匹配。两个集合的匹配一共可以分为三种情况:(1)kt-1 和 kt 的交集,这个可以用来直接给跟踪查询embedding匹配对应的真实标签(2)kt-1 中出现 kt 中没有的,直接舍匹配背景标签(3)kt 和 kt-1中有中不存在的在,这一部分是新的目标,需要用匈牙利算法对目标查询和真实标签的包围框和类别进行优化匹配得到最小损失的匹配结果。匹配过程如下公式所示:
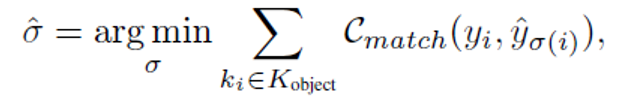
σ为gt到目标查询(Nobject)的映射关系,优化目标就是让匹配损失最小,匹配损失同时包括了类别损失和包围框损失如下所示:
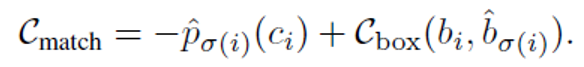
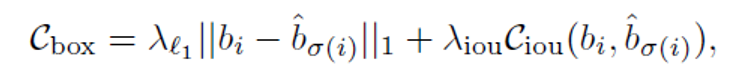
得到匹配结果后,最后就可以计算集合预测损失,同时包括了跟踪和目标查询输出的损失,计算方法如下:
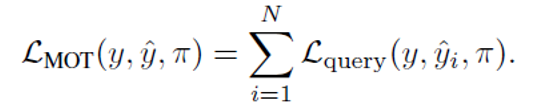
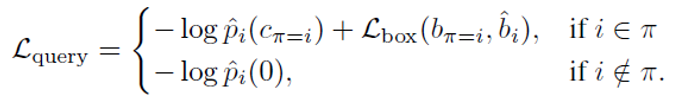
∏是通过跟踪id和匈牙利算法得到的输出与真值之间的匹配结果。
3. 实验结果
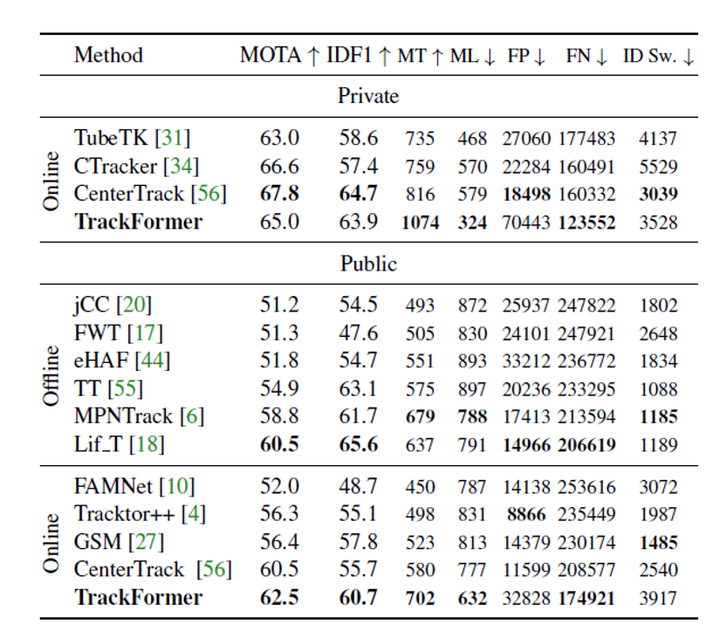
表3-1 MOT17上的跟踪结果
从表3-1的结果可以看出,在私有检测器上的跟踪结果仍有一定差距,这主要是因为基于transformer的检测器效果没有现在SOTA的方法好,但当采用共有检测器时,在线上跟踪的情况下无论是在MOTP和IDF1都有明显的提升。
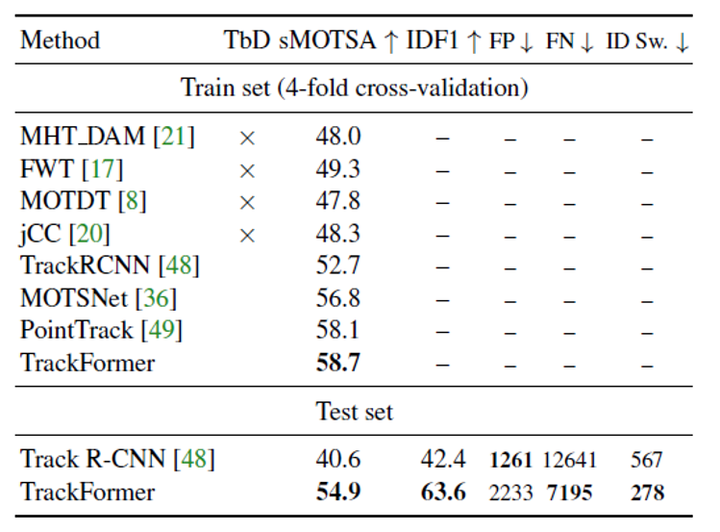
表3-2 MOTS20上的跟踪结果
除了目标检测和跟踪之外,TrackFormer还可以预测实例水平的分割图。从表3-2可以看出无论是在交叉验证结果上还是测试集上,TrackFormer都要优于现有的SOTA方法。
AI论文解读:基于Transformer的多目标跟踪方法TrackFormer的更多相关文章
- 医学AI论文解读 |Circulation|2018| 超声心动图的全自动检测在临床上的应用
文章来自微信公众号:机器学习炼丹术.号主炼丹兄WX:cyx645016617.文章有问题或者想交流的话欢迎- 参考目录: @ 目录 0 论文 1 概述 2 pipeline 3 技术细节 3.1 预处 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- 带你读AI论文丨LaneNet基于实体分割的端到端车道线检测
摘要:LaneNet是一种端到端的车道线检测方法,包含 LanNet + H-Net 两个网络模型. 本文分享自华为云社区<[论文解读]LaneNet基于实体分割的端到端车道线检测>,作者 ...
- 解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法
摘要:本文提出了两个用于无监督的具备可解释性和鲁棒性时间序列离群点检测的自动编码器框架. 本文分享自华为云社区<解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法&g ...
- 论文解读(XR-Transformer)Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification
Paper Information Title:Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text C ...
- 带你读AI论文丨针对文字识别的多模态半监督方法
摘要:本文提出了一种针对文字识别的多模态半监督方法,具体来说,作者首先使用teacher-student网络进行半监督学习,然后在视觉.语义以及视觉和语义的融合特征上,都进行了一致性约束. 本文分享自 ...
- THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor 论文解读
THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
随机推荐
- 16.2 ARP 主机探测技术
ARP (Address Resolution Protocol,地址解析协议),是一种用于将 IP 地址转换为物理地址(MAC地址)的协议.它在 TCP/IP 协议栈中处于链路层,为了在局域网中能够 ...
- [WPF]原生TabControl控件实现拖拽排序功能
在UI交互中,拖拽操作是一种非常简单友好的交互.尤其是在ListBox,TabControl,ListView这类列表控件中更为常见.通常要实现拖拽排序功能的做法是自定义控件.本文将分享一种在原生控件 ...
- 虹科分享 | 一起聊聊Redis企业版数据库与【微服务误解】那些事儿!
如今,关于微服务依然存在许多误解,企业盲目追求这种炫酷技术并不可取.同时,这种盲目行为对于希望用微服务来有效解决问题的公司很不利.不是说任何特定的技术都是缺乏实际价值的,如微服务.Kubernetes ...
- 关于STM32F407ZGT6的USB损坏后使用ST-Link和USART1实现串口功能
开发板:STM32F407ZGT6: 目标:想使用软件"串口调试助手" 情况:开发板上的USB_UART口所在器件损坏或者直接没有: 解决办法:查看该开发板的原理图,可得:串口1的 ...
- 9.24 多校联测 Day4 总结
没有罚坐,但好像什么也没做. 反向挂分,RP++. 开考推 T1 的 k=2.推推推,写写写,假了.又假了.还是假的. 此时已过去 1h,开 T2,没有看懂题,又看了一会依旧没有看懂. 开 T3.尝试 ...
- Redis Functions 介绍之二
首先,让我们先回顾一下上一篇讲的在Redis Functions中关于将key的名字作为参数和非key名字作为参数的区别,先看下面的例子.首先,我们先在一个Lua脚本文件mylib.lua中定义如下的 ...
- 关于Anolis8/Centos8系统重启后ip地址丢失的原因
关于Anolis8/Centos8系统重启后ip地址丢失的原因 #.今天把之前在VMware安装的Anolis8系统重启了,启动之后发现Xshell连接不上.在VMware上登录后执行ip a命令发现 ...
- Excel表格函数公式出现溢出怎么办?
Excel是一款广泛使用的电子表格软件,它可以帮助我们进行各种计算.数据分析与处理等操作.在使用Excel时,我们通常需要使用到各种函数公式来完成不同的任务.然而,在使用函数公式时有时会出现" ...
- ARM汇编指令实验
题目 地址为0x40008000起始的内存中存放了20个无符号的8位整数,请编写ARM汇编程序实现如下功能: 采用冒泡法将以上内存中的数据按照从小到大的顺序排列. 注意:在验收实验时,需要自己把具体的 ...
- 在net中通过Autofac实现AOP的方法及实例详解
在本示例中,我们将使用Autofac和AspectC(Autofac.Extras.DynamicProxy2)来演示如何实现AOP(面向切面编程).我们将创建一个简单的C#控制台应用程序,并应用AO ...